Microsoft releases full Phi-4 model with weights under MIT license
Update from January 8, 2025:
Following through on their December announcement, Microsoft has now released the complete model weights for their compact yet capable LLM Phi-4 on Hugging Face.
By releasing Phi-4 under the MIT license, Microsoft has given developers and researchers free rein to use, modify, and build upon the model - including for commercial applications. Publishing the model weights means developers can now access and modify the underlying parameters directly.
Original article from December 13, 2024:
Microsoft's Phi-4 developers say synthetic data is not a "cheap substitute" for organic data
Microsoft Research's new Phi-4 LLM matches the abilities of much larger models while using just 14 billion parameters - about one-fifth the size of similar systems.
According to Microsoft's technical report, the model even outperforms GPT-4, its teacher model, when answering science and technology questions. Phi-4 shows particular strength in mathematics, achieving a 56.1 percent success rate on university-level questions and 80.4 percent on mathematical competition problems.
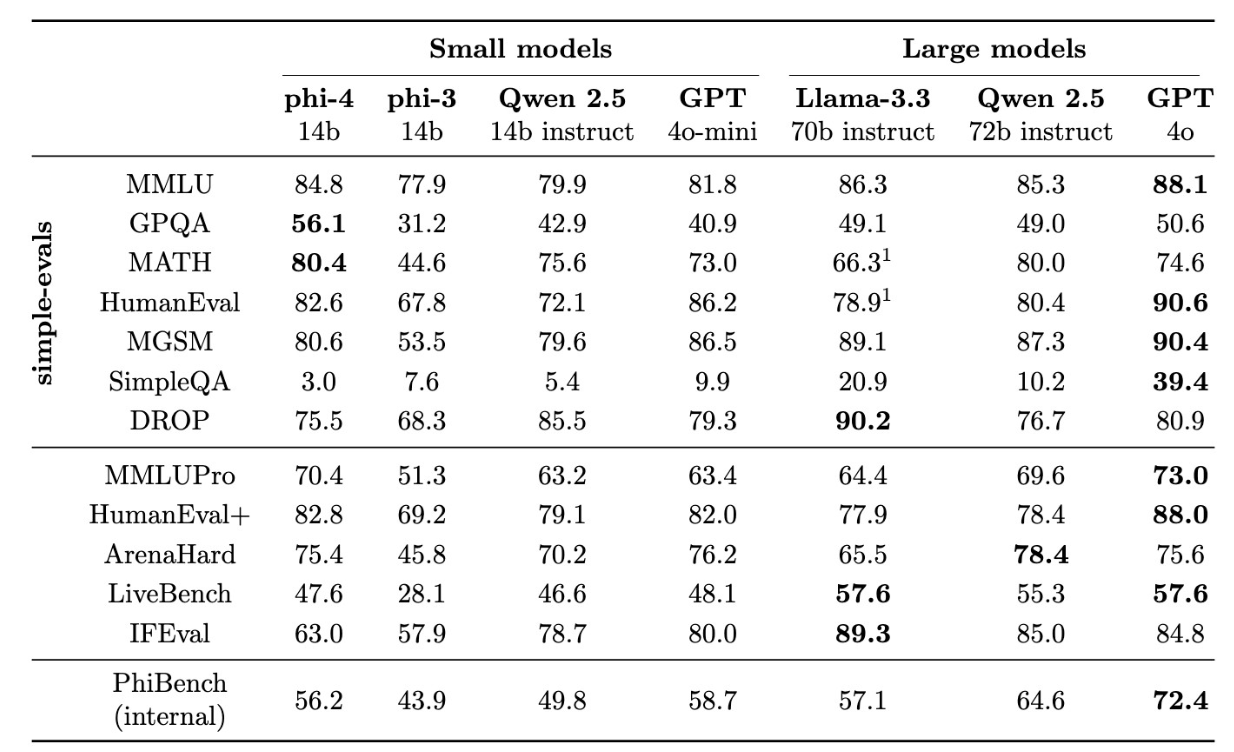
Microsoft notes that Phi-4 struggles with following exact prompt instructions and formatting requirements like tables. The researchers explain this stems from training that focused on Q&A and reasoning rather than strict prompt following.
Like other language models, Phi-4 can generate false information, such as fictional biographies for unknown people. It also sometimes fails basic logic tests, such as incorrectly determining that 9.9 is less than 9.11, a popular logic test case for language models.
Synthetic data isn't a "a cheap substitute" for organic data
Like its predecessor Phi-1, Phi-4's core principle focuses on the quality of training data. But while most language models rely primarily on web content or code, Microsoft took a different approach with Phi-4, using carefully generated synthetic "textbook-like" data for its pre- and mid-training.
The team created 50 different types of synthetic datasets in areas such as mathematical reasoning, programming, and general knowledge, totaling about 400 billion tokens.
"Rather than serving as a cheap substitute for organic data, synthetic data has several direct advantages over organic data," the technical report states.
The researchers supplemented this synthetic data with carefully filtered organic sources, including public documents and educational materials.
Microsoft also developed new training methods to improve the model's ability to distinguish between high-quality and low-quality answers. The team identified "pivotal tokens"—specific words or symbols that can make or break an answer's accuracy. By training the model to better recognize these critical decision points, the team improved its overall question-answering performance.
Model weights coming soon
Former Microsoft Phi developer Sebastien Bubeck, who recently moved to OpenAI, announced the model's weights will be available to the public. "Phi-4 is in Llama 3.3-70B category (win some, lose some) with 5x fewer parameters," Bubeck wrote.
The research team wanted to make sure that Phi-4 wasn't just memorizing its training data, so they put it to the test using American math competitions from November 2024—problems that didn't exist when the model was trained.
Phi-4 scored an average of 91.8 percent on these new tests, outperforming both larger and smaller competing models, which surprised even the research team, according to Bubeck.

However, it's worth noting that strong benchmark results don't always translate to real-world success. Previous Phi models have shown excellent benchmark performance but proved less practical in actual use cases.
Microsoft currently offers Phi-4 through its Azure AI Foundry platform and plans to release it on HuggingFace next week, likely under a research license.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.