Microsoft's tiny Phi-1 language model shows how important data quality is for AI training

When scaling AI systems, people often talk about the size of the models and the amount of data. But a third factor is just as important: the quality of the data.
Researchers at Microsoft studied the ability of a tiny language model to perform coding tasks when trained on small but high-quality data with the transformer-based language model phi-1.
The researchers say they used only "textbook quality" data to train the AI. From The Stack and StackOverflow datasets, they filtered out six billion high-quality training tokens for code using a classifier based on GPT-4. The team generated another billion tokens using GPT 3.5.
Training took only about four days on eight Nvidia A100 graphics cards.
Phi-1 beats significantly larger models in benchmarks
The largest small model, phi-1 1.3B, which was additionally refined with code tasks, beats models that are 10x larger and use 100x more data in the HumanEval and MBPP benchmarks. Only GPT-4 beats phi-1 in the test scenarios.
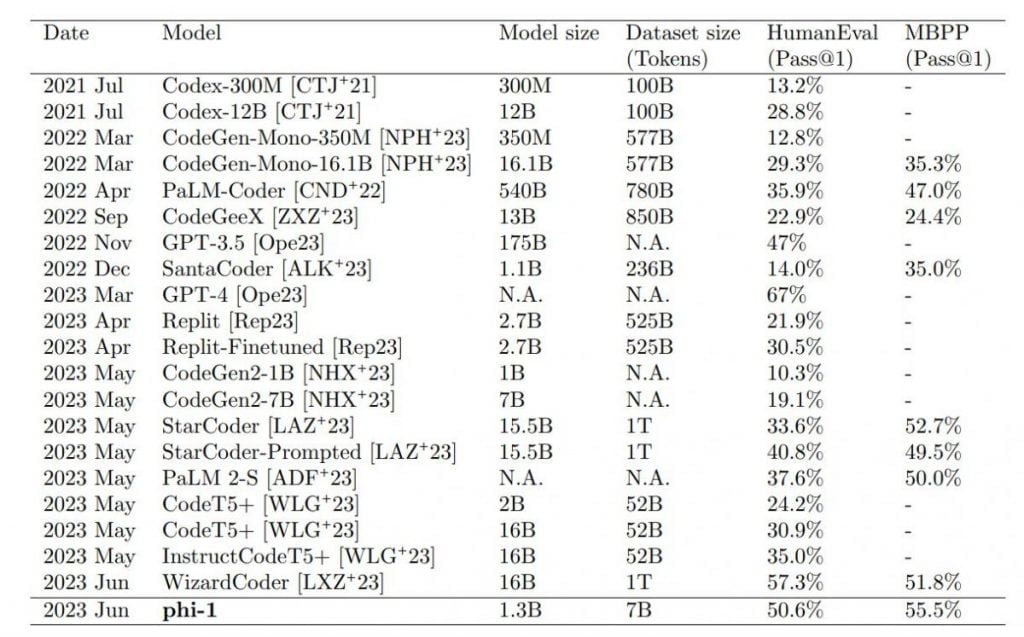
The results exceeded the researchers' expectations. The team attributes them directly to data quality, as the title of the paper suggests: "Textbooks is all you need," in reference to Google's research on the Transformer breakthrough ("Attention is all you need").
However, Phi-1 also has some limitations compared to larger models. Its specialization in Python programming limits its versatility, it lacks the domain-specific knowledge of larger LLMs, such as programming with specific APIs, and the structured nature of Phi-1 makes it less robust to style variations or input errors in prompts.
Further improvements in model performance would be possible if the synthetic data were generated using GPT-4 rather than GPT-3.5, which has a high error rate. However, the team points out that despite the many errors, the model was able to learn effectively and generate correct code. This suggests that useful patterns or representations can be extracted from faulty data.
Expert models focused on data quality
The researchers say their work confirms that high-quality data is critical for training AI. However, they say, collecting high-quality data is challenging. In particular, it must be balanced, diverse, and avoid repetition. Especially for the last two points, there is a lack of measurement methods. Phi-1 will soon be released as open source on Hugging Face.
Just as a comprehensive, well-crafted textbook can provide a student with the necessary knowledge to master a new subject, our work demonstrates the remarkable impact of high quality data in honing a language model’s proficiency in code-generation tasks.
From the paper
Andrei Karpathy, former head of AI at Tesla and now back at OpenAI, shares this sentiment, saying he expects to see more "small and powerful expert models" in the future. These AI models would prioritize data quality, diversity over quantity, and be trained on complementary synthetic data.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.