Midjourney develops new method to improve LLMs creative writing range

Researchers from Midjourney and New York University have developed a new approach that could help language models generate more diverse creative texts without significantly sacrificing quality.
In a recently published paper, the team introduces "deviation metrics" into the AI training process. The method works by measuring how different each generated text is from others created for the same prompt. These differences get calculated using embedded texts and their pairwise cosine distance - essentially giving the system a mathematical way to understand text variation.
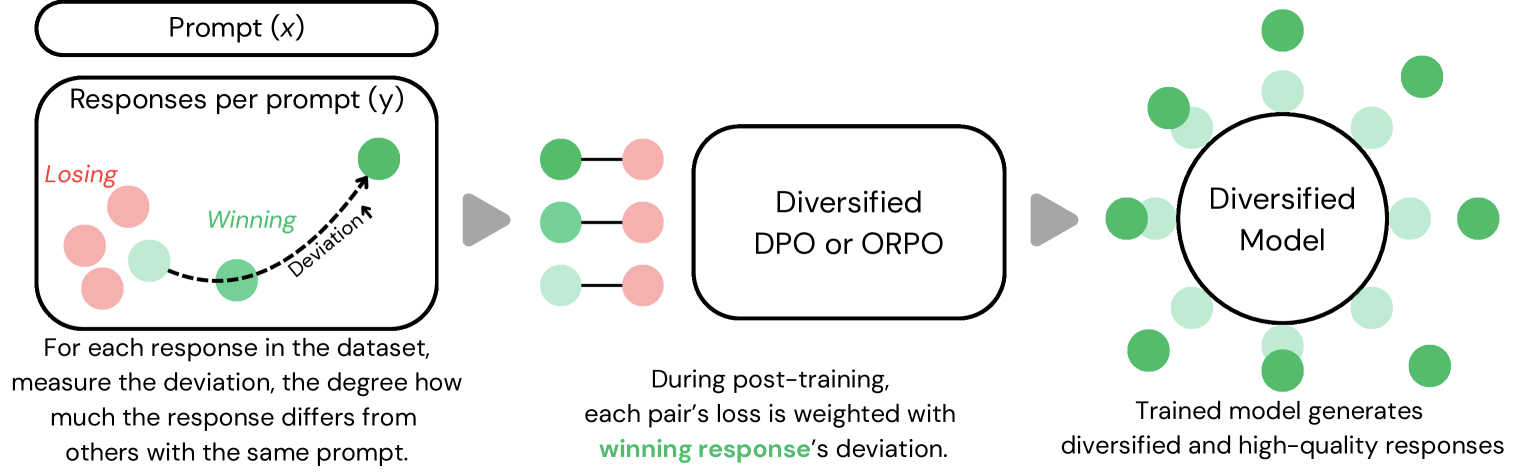
Initial testing looks promising. Models using this new training method generated 23 percent more diverse texts, with quality scores dropping by only five percent according to Reddit's reward system.
A test case shows how this works in practice. When given the prompt "Why are you shaking, my love? You're king now," the standard GPT-4o model mostly stuck to stories about nervous new rulers. The modified Llama-3.1-8B model, despite being smaller, produced everything from dark fantasy tales about bear princes to supernatural stories set underwater.
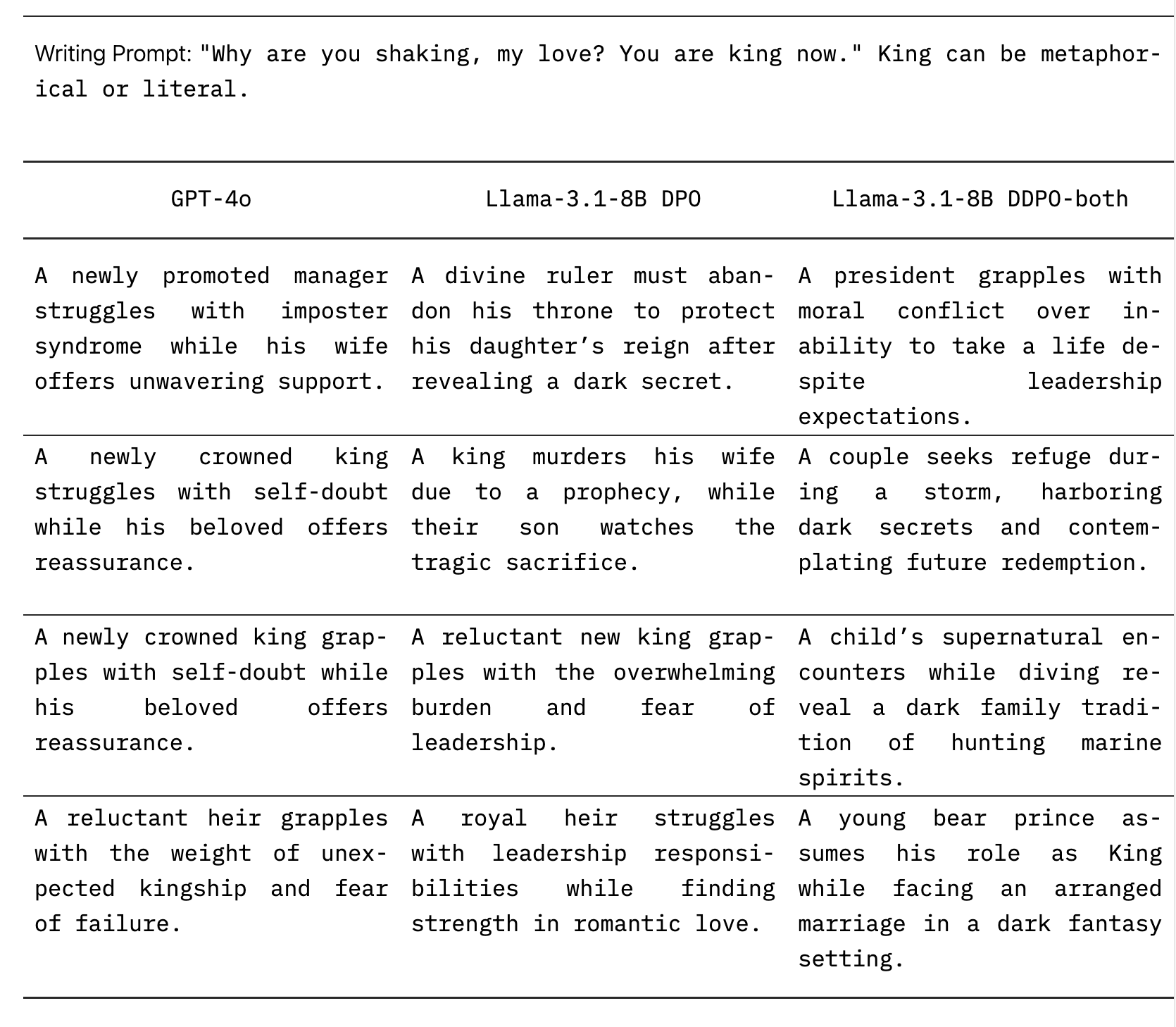
Human testers backed up these findings, saying the texts showed more variety while maintaining quality. The researchers only tested against the older GPT-4o though, not the newer GPT-4.5, which produces more natural-sounding text but costs more to use.

Two types of diversity
The researchers focused on two kinds of variety: semantic (different story content and plots) and stylistic (writing that sounds like it comes from different authors). They developed specific versions for each type but found combining them worked best.
For their research, the team used more than 100,000 prompt-response pairs from Reddit's r/WritingPrompts. They discovered they could get significantly better variety with just four different responses per prompt.
The system can maintain quality by using carefully selected training examples or setting minimum standards for how different responses need to be. This makes it more flexible than other methods for increasing output variety.
Some questions still need answers. The researchers haven't yet shown whether their method works beyond creative writing - technical documentation and summaries might require different approaches. The technique's effectiveness in online training environments, which many large models use, also remains untested.
The quality measurement system itself raises questions. While Reddit upvotes provide some insight into text quality, they miss important factors like technical accuracy, consistency, and professional writing standards. These limitations suggest more comprehensive evaluation methods may be needed.
Even with these open questions, the technique could change how LLMs handle creative writing tasks, where current models often fall into repetitive patterns. The researchers say they'll share their code on GitHub, so others can build on their work.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.