Mistral's Mixtral 8x22B sets new records for open source LLMs

French AI startup Mistral AI has unveiled Mixtral 8x22B, a new open-source language model that the company claims achieves the highest open-source performance and efficiency.
The model is a sparse mixture-of-experts (SMoE) model that actively uses only 39 billion of its 141 billion parameters. As a result, the development team claims it offers an exceptionally good price/performance ratio for its size. Its predecessor, Mixtral 8x7B, has been well received by the open-source community.
According to Mistral, Mixtral 8x22B's strengths include multilingualism, with support for English, French, Italian, German, and Spanish, as well as strong math and programming capabilities. It also offers native function calling for using external tools. At 64,000 tokens, the context window is smaller than that of current leading commercial models such as GPT-4 (128K) or Claude 3 (200K).
Open source without restrictions
The Mistral team releases Mixtral 8x22B under the Apache 2.0 license, the most permissive open-source license available. It allows unrestricted use of the model.
According to Mistral, the model's sparse use of active parameters makes it faster than traditional densely trained 70-billion-parameter models and more capable than other open-source models.
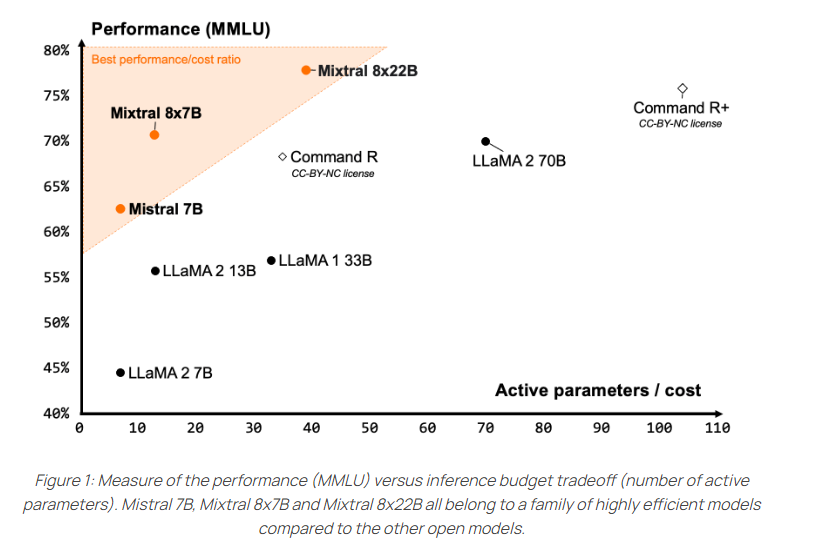
Compared to other open models, the Mixtral 8x22B achieves the best results on popular comprehension, logic and knowledge tests such as MMLU, HellaSwag, Wino Grande, Arc Challenge, TriviaQA and NaturalQS.
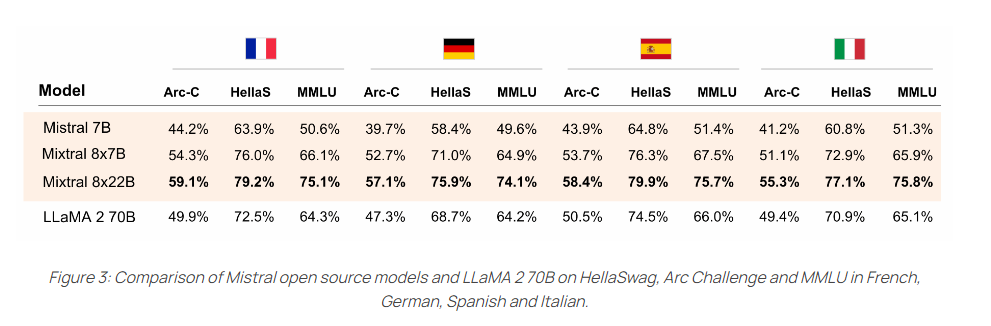
It also clearly outperforms the 70B LLaMA-2 model in the supported languages - French, German, Spanish and Italian - on the HellaSwag, Arc Challenge and MMLU benchmarks.
The new model can now be tested on Mistral's "la Plateforme". The open-source version is available at Hugging Face, and is a good starting point for fine-tuning applications, according to Mistral. The model requires 258 gigabytes of VRAM.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.