MLPerf: Nvidia claims leadership in performance and versatility

Nvidia leads this year's MLPerf inference benchmark. New data shows performance leaps with Hopper and new hardware.
In the MLPerf benchmark, hardware vendors and service providers compete with their AI systems. The test is hosted by MLCommons and aims to transparently compare different chip architectures and system variants.
Today MLPerf released new results of the MLPerf Inference 3.0 benchmark. A new feature is a network environment that tests the AI performance of different systems under more realistic conditions: Data is streamed to an inference server. The test is designed to more accurately reflect how data enters the AI accelerator and is output in the real world, thus revealing bottlenecks in the network.
Nvidia Hopper makes significant year-over-year gains
According to Nvidia, the H100 Tensor Core GPUs in the DGX H100 systems have up to 54 percent more inference performance than last year due to software optimizations. This jump is seen in RetinaNet inference, with other models such as 99% accurate BERT running 12% faster, ResNet-50 running 13% faster, and 3D U-Net used in medical applications running 31% faster.
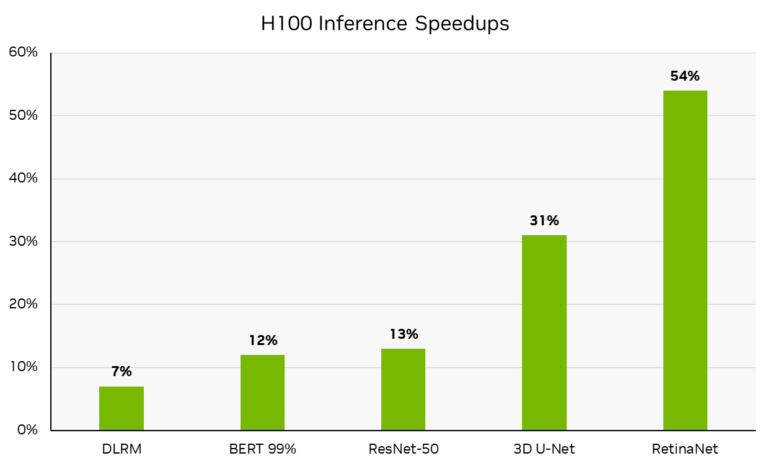
In presenting the results, Nvidia emphasized that they see themselves as the clear leader in performance, but also as the equally important leader in the versatility of their architecture. Nvidia is the only company to present results for all tasks in MLPerf Inference 3.0.
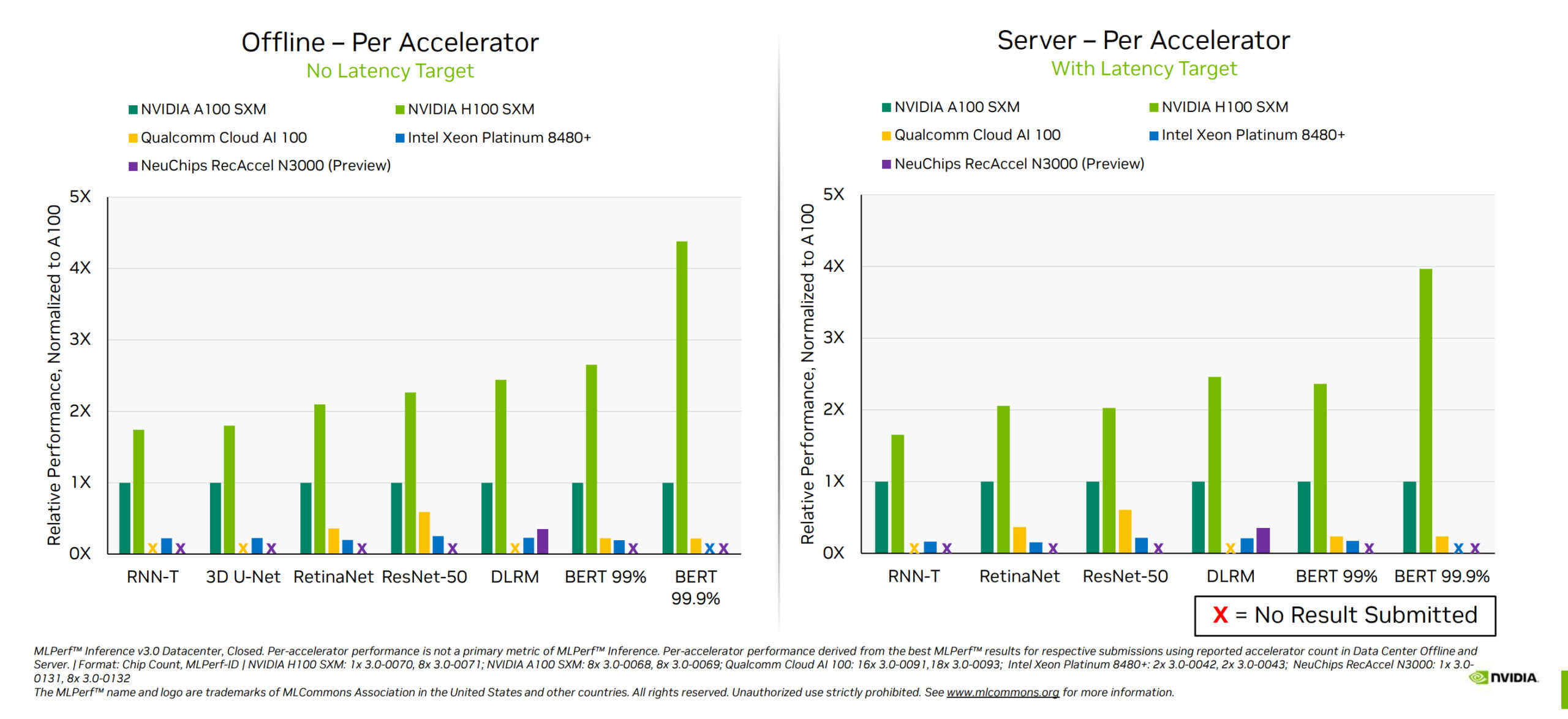
Compared to an A100 GPU, the H100 GPU is also significantly stronger at inferencing transformer models, such as BERT 99.9, thanks to the Transformer engine, where the H100 delivers more than four times the performance.
As a result, the card promises to deliver big performance gains for many generative AI models, such as those that generate text, images, or 3D models.
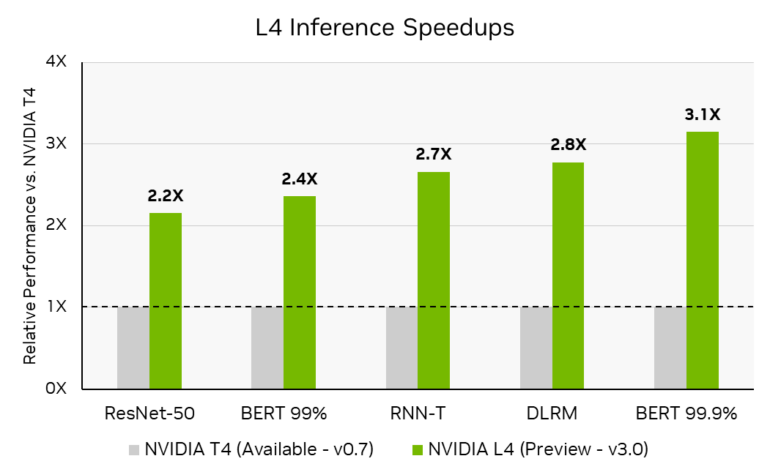
New L4 card up to 3 times faster than predecessor
New to the benchmark is Nvidia's L4 Tensor GPU, which the company recently unveiled at GTC. The card is already available from some cloud providers and delivers 2.2 to 3.1 times the inference performance of its predecessor, the T4, in the benchmarks.
Nvidia's Jetson AGX Orin for the Edge is also up to 63 percent more energy efficient and up to 81 percent more powerful than last year thanks to numerous improvements.
In the newly added network test, Nvidia's DGX A100 systems delivered 96 percent of maximum local performance on the BERT model, which is the performance the system delivers when the model is running locally. According to Nvidia, the reason for the slight performance drop is due to CPU latency. In the RestNet 50 test, which is run exclusively on GPUs, the DGX systems achieved 100 percent of local performance.
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.