New Deepseek technique balances signal flow and learning capacity in large AI models

DeepSeek researchers have developed a technique that makes training large language models more stable. The approach uses mathematical constraints to solve a well-known problem with expanded network architectures.
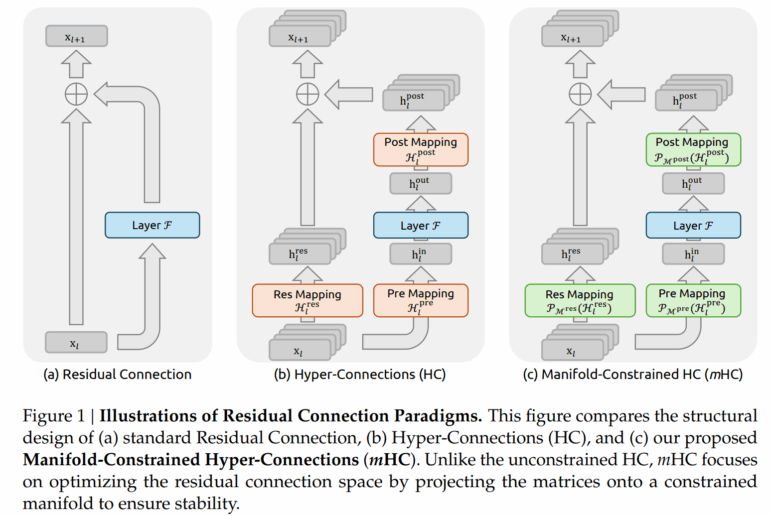
Neural networks have used residual connections for about a decade to move information through deep architectures. Think of these connections as shortcuts: information from early layers reaches later layers directly, which makes training more stable. Newer approaches like "Hyper-Connections" (HC) expand on this principle by widening the information flow and introducing more complex connection patterns.
The problem, according to the researchers: while these expansions boost performance, they destabilize training in larger models. DeepSeek's team has now introduced "Manifold-Constrained Hyper-Connections" (mHC), a solution designed to deliver both benefits.
Why expanded connections cause training to derail
With standard residual connections, signals pass through the network essentially unchanged. This property keeps training stable - the errors the model learns from flow reliably back through all layers, and adjustments stay within expected bounds.
Hyper-Connections work differently. Signals pass through learnable matrices that transform them. This is intentional, since it lets the network learn more complex patterns. The problem emerges when these changes compound across many layers. Instead of passing signals through unchanged, each layer can amplify or weaken them further.
The researchers document this issue using a 27-billion-parameter model: at around 12,000 training steps, HC shows a sudden spike in loss - the error rate the model learns from. This kind of jump is a warning sign that training has become unstable and the learning signals (gradients) have gone haywire.
The cause, according to the team, lies in how much signals get amplified as they move through the network. The researchers measure this with a metric that should ideally stay around 1 - meaning the signal arrives at the same strength it started with. With HC, however, this value peaks at 3,000. That means signals get amplified three thousand times over, which inevitably causes problems.
HC also creates significant memory access overhead. Since the information flow widens by a factor of about 4, memory accesses increase accordingly.
Mathematical guardrails keep signals under control
The core idea behind mHC is constraining the learnable connection matrices mathematically. The researchers use matrices with a special property: all entries are non-negative, and both row and column sums equal exactly 1.
What does this mean in practice? When such a matrix is applied to a signal, it creates a weighted mixture of input values. Since the weights are positive and sum to 1, signals get redistributed but not amplified uncontrollably, even when many such steps happen in sequence.
To convert any matrix into this form, the researchers use an iterative procedure called the Sinkhorn-Knopp algorithm. It alternates between normalizing rows and columns until both sum to 1. The implementation uses 20 such passes, which experiments show strikes a good balance between accuracy and computational cost.
The result: signal amplification drops from 3,000 to about 1.6 - a reduction of three orders of magnitude. Signals stay close to their original strength, and training remains stable.
Better results with more stable training
The researchers tested mHC on models with 3, 9, and 27 billion parameters, based on the DeepSeek-V3 architecture. The 27B model shows stable training curves without the crashes seen with HC.
On benchmarks, mHC outperforms both the baseline and HC on most tests. On BBH, which tests complex reasoning tasks, mHC hits 51.0 percent compared to 48.9 for HC and 43.8 for the baseline. On DROP, which combines reading comprehension with numerical reasoning, mHC scores 53.9 versus 51.6 and 47.0. The improvements over HC are modest at 2.1 and 2.3 percentage points, but training stability is significantly better.
Scaling experiments indicate that mHC's advantages hold across different model sizes and training budgets. The relative improvement over the baseline decreases only slightly with larger models.
Optimizations keep overhead low
To make mHC practical, the researchers put considerable effort into the technical implementation. By combining compute operations, they reduced memory accesses. A selective approach stores only essential intermediate results and recalculates the rest as needed, cutting memory requirements.
Special attention went to integrating mHC with DualPipe, the method DeepSeek-V3 uses to distribute training across many GPUs. The researchers optimized communication between compute units so it happens in parallel with actual calculations.
The result: mHC adds only 6.7 percent overhead compared to the standard architecture. Given the stability and performance gains, the researchers consider this tradeoff acceptable.
The team sees mHC as a starting point for further research into network topologies. The framework allows exploration of different mathematical constraints that could be tailored to specific learning objectives.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.