
Nvidia has released Nemotron-4 340B, an open-source pipeline for generating synthetic data. The language model is designed to help developers create high-quality datasets for training and fine-tuning large language models (LLMs) for commercial applications.
The Nemotron-4 340B family consists of a base model, an instruction model, and a reward model, which together form a pipeline for generating synthetic data that can be used to train and refine LLMs. Nemotron's base model was trained with 9 trillion tokens.
Synthetic data mimics the properties of real data and can improve data quality and quantity, which is particularly important when access to large, diverse, and annotated datasets is limited.
According to Nvidia, the Nemotron-4 340B Instruct model generates diverse synthetic data that can improve the performance and robustness of customized LLMs in various application areas such as healthcare, finance, manufacturing, and retail.
The Nemotron-4 340B Reward model can further improve the quality of the AI-generated data by filtering out high-quality responses.
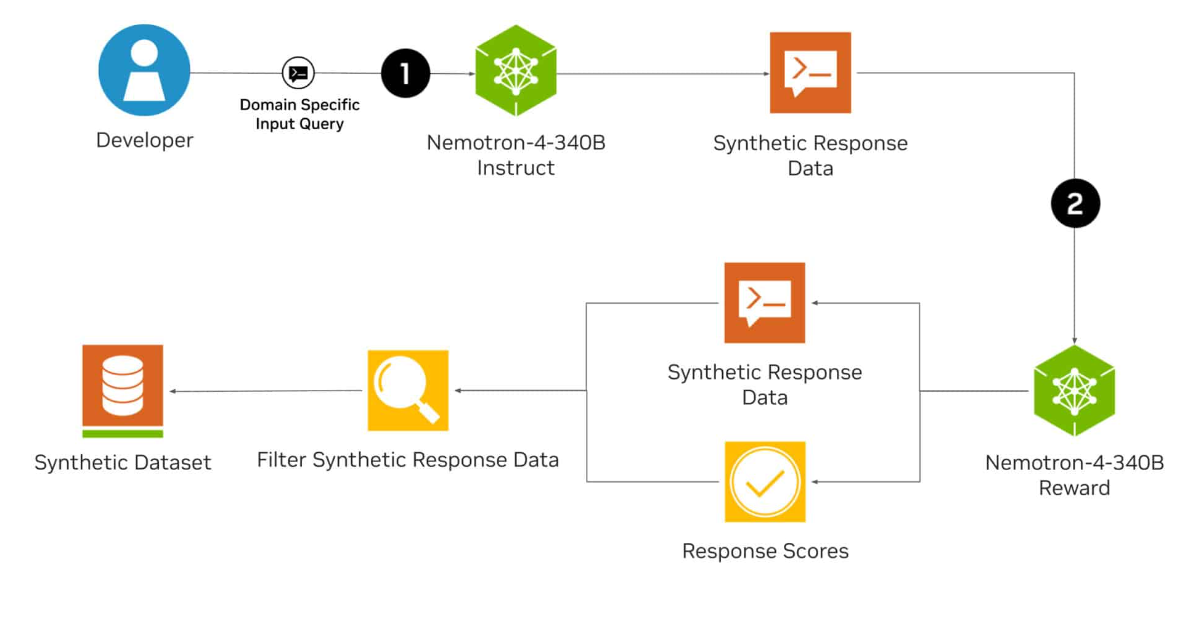
98 percent of the training data used to fine-tune the Instruct model is synthetic and was created using Nvidia's pipeline.
In benchmarks such as MT-Bench, MMLU, GSM8K, HumanEval, and IFEval, the Instruct model generally performs better than other open-source models such as Llama-3-70B-Instruct, Mixtral-8x22B-Instruct-v0.1, and Qwen-2-72B-Instruct, and in some tests, it even outperforms GPT-4o.

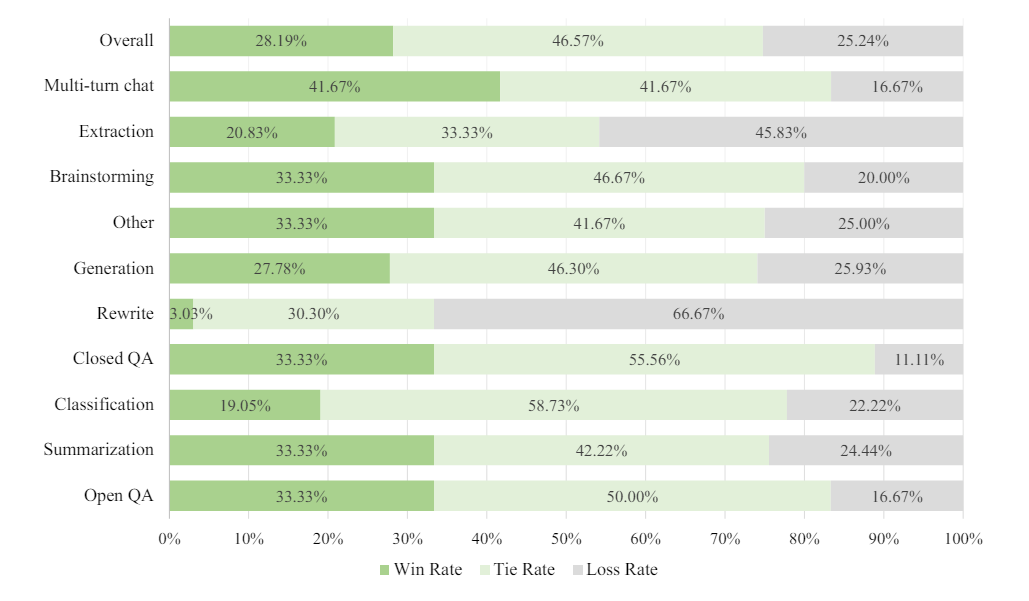
It also performs comparable to or better than OpenAI's GPT-4-1106 in human evaluation for various text tasks such as summaries and brainstorming. Detailed benchmarks are available in the technical report. According to Nvidia, the models run on DGX H100 systems with eight GPUs at FP8 precision.
The models are optimized for inference with the open-source framework Nvidia NeMo and the Nvidia TensorRT-LLM library. Nvidia makes them available under its Open Model License, which also allows for commercial use. All data is available on Huggingface.
Releasing Nemotron framed as a synthetic data generator seems to be a very strategic move by Nvidia: instead of positioning Nemotron as a competitor to Llama 3 or GPT-4, the model family is supposed to help other developers to train better or more models in different domains. More training and more models on the market means more demand for GPUs.





