Nvidia researchers develop DoRA, a smarter way to fine-tune AI models for specific tasks

Nvidia researchers have introduced a method for resource-efficient fine-tuning of AI models. DoRA achieves higher accuracy than the widely used LoRA without increasing the computational cost for inference.
LoRA (Low-Rank Adaptation) has become an increasingly popular method for fine-tuning large AI language models for specific tasks. LoRA adjusts the weights of the pre-trained model with only a few parameters, thus reducing the computational cost compared to classical fine-tuning of the entire network. However, so-called full fine-tuning still achieves higher accuracy.
Nvidia researchers have now examined the differences in learning behavior between LoRA and classic full fine-tuning to find methods to minimize these differences. They analyzed the changes in model weights during fine-tuning, particularly considering the magnitude and direction components of the weights. The magnitude components show how much the weights change, while the direction components indicate in which direction these changes occur, i.e., how the ratio of the weights to each other changes.
Here, clear differences emerge: While LoRA makes magnitude and direction changes proportionally, full fine-tuning can make more subtle adjustments. LoRA lacks the ability to combine large magnitude changes with small direction changes or vice versa.
DoRA approaches learning capability of full fine-tuning
Based on these findings, the researchers introduce Weight-Decomposed Low-Rank Adaptation (DoRA). DoRA first decomposes the pre-trained weights into magnitude and direction components, and then trains both. Since the direction component has many parameters, it is additionally decomposed with LoRA to accelerate training.
By separately optimizing magnitude and direction, DoRA simplifies the task for LoRA compared to the original approach. Additionally, splitting the weights stabilizes the optimization of direction adaptation. Through this modification, DoRA achieves a learning capability similar to full fine-tuning.
In experiments with various tasks such as commonsense reasoning, visual instruction optimization, and image-text understanding, DoRA consistently outperforms LoRA without additional computational cost during inference. The improved learning capability allows DoRA to achieve higher accuracy than LoRA in the tested benchmarks with fewer parameters.
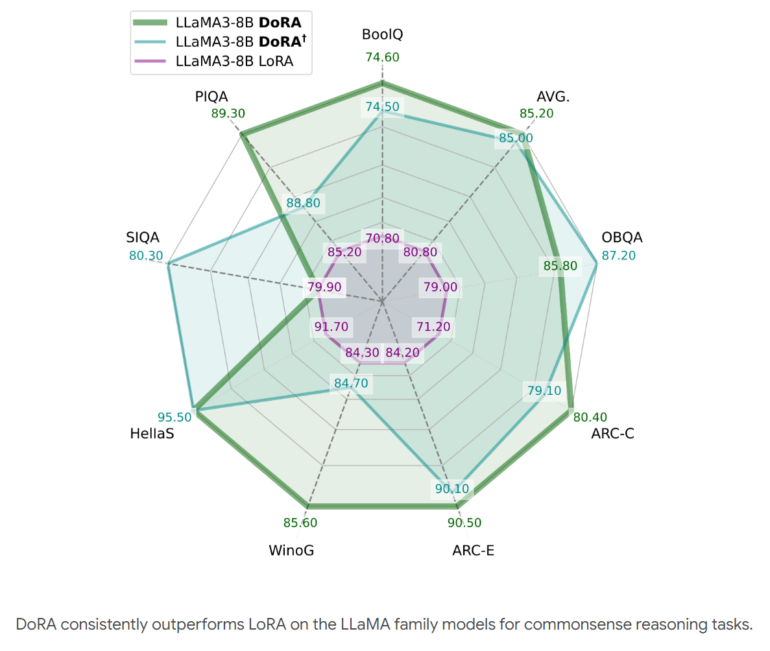
DoRA is compatible with LoRA and its variants, such as VeRA. The method can also be applied to different model architectures, such as Large Language Models (LLM) and Large Vision Language Models (LVLM). The researchers want to transfer DoRA to other domains such as audio in the future.
More information and the code can be found on the DoRA project page.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.