- Added new features
Update from May 1, 2024:
Nvidia is updating its experimental ChatRTX chatbot for RTX GPU owners with additional AI models, including Google's Gemma, ChatGLM3, and OpenAI's CLIP model for photo searches. In addition, ChatRTX now supports voice queries using OpenAI's Whisper model.
ChatRTX is available as a 36GB download from Nvidia's website and requires an RTX 30 or 40 series GPU with at least 8GB of VRAM.
Updated February 13, 2024:
Update from February 13, 2024:
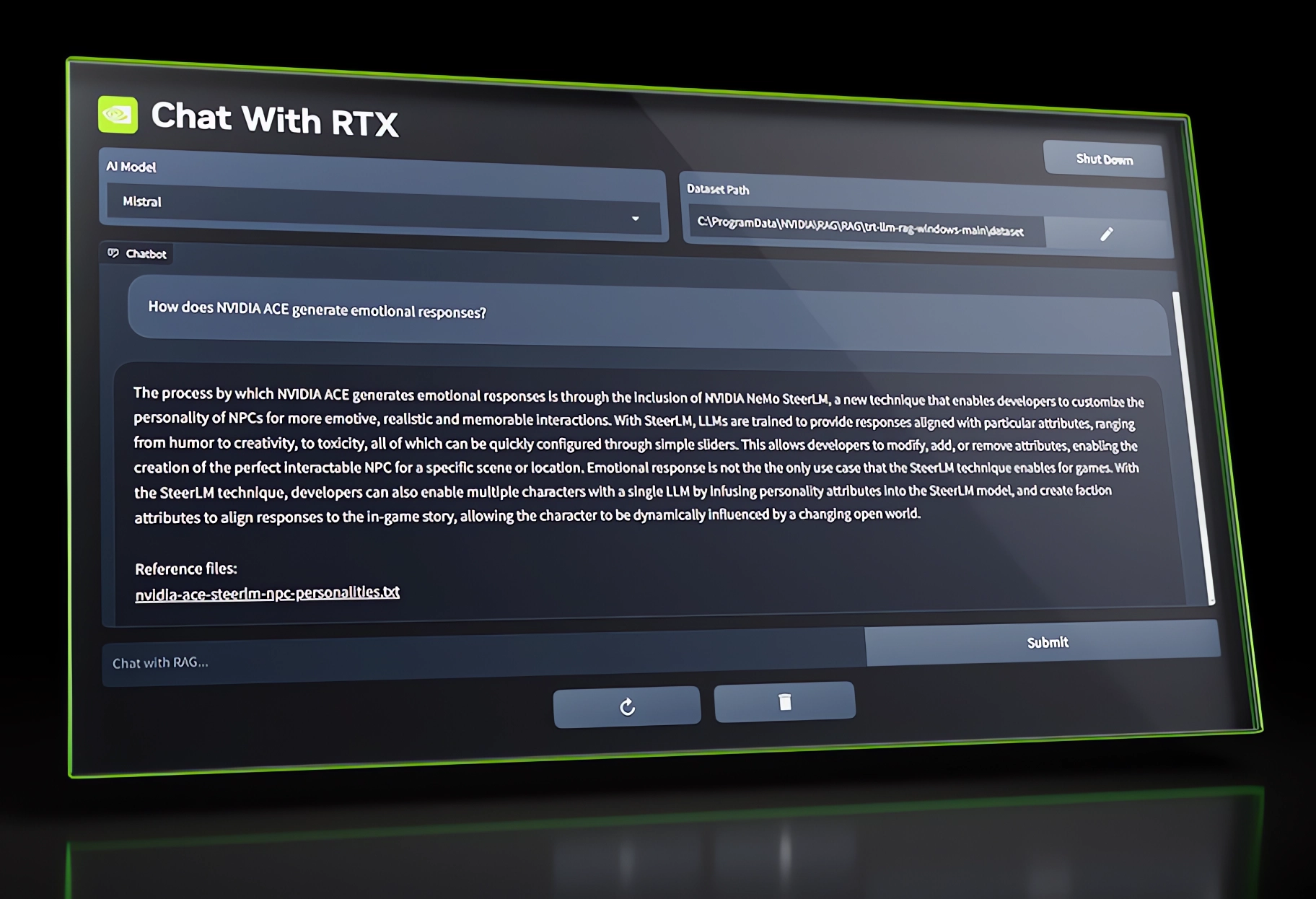
Nvidia's free 'Chat with RTX' turns your documents into a personalized AI chatbot
"Chat with RTX" from Nvidia is now available as a free download. The download takes about 35 GB.
The chip manufacturer recommends at least a Geforce RTX 30 series graphics card with 8 GB VRAM and 16 GB RAM as well as Windows 11. Once installed, you can use Llama 2 and Mistral language models to make your files and YouTube video transcripts "chattable" on your local drive via RAG.
Original post from January 11, 2024:
Nvidia has announced a new demo application called Chat with RTX that allows users to personalize an LLM with their content such as documents, notes, videos, or other data.

The application leverages Retrieval Augmented Generation (RAG), TensorRT-LLM, and RTX acceleration to allow users to query a custom chatbot and receive contextual responses quickly and securely.
The chatbot runs locally on a Windows RTX PC or workstation, providing additional data protection over your standard cloud chatbot.
Chat with RTX supports various file formats, including text, PDF, doc/docx, and XML. Users can simply point the application to the appropriate folders, and it will load the files into the library.
Users can also specify the URL of a YouTube playlist and the application will load the transcripts of the videos in a playlist and make them chattable. Google Bard offers a similar feature, but only with a Google account in the Google Cloud. Chat with RTX processes the transcript locally.
Video: Nvidia
You can register here to be notified when Chat with RTX is available.
Developers can get started right away
The Chat with RTX Tech Demo is based on the TensorRT-LLM RAG Developer Reference Project available on GitHub. According to Nvidia, developers can use this reference to build and deploy their RAG-based applications for RTX accelerated by TensorRT-LLM.
In addition to Chat with RTX, Nvidia also introduced RTX Remix at CES, a platform for creating RTX remasters of classic games, which will be available in beta in January, and Nvidia ACE Microservices, which provides games with intelligent and dynamic digital avatars based on generative AI.
Nvidia has also released TensorRT acceleration for Stable Diffusion XL (SDXL) Turbo and Latent Consistency models, which is expected to deliver up to a 60 percent performance boost. An updated version of the Stable Diffusion WebUI TensorRT extension with improved support for SDXL, SDXL Turbo, LCM - Low-Rank Adaptation (LoRA) is now available.

