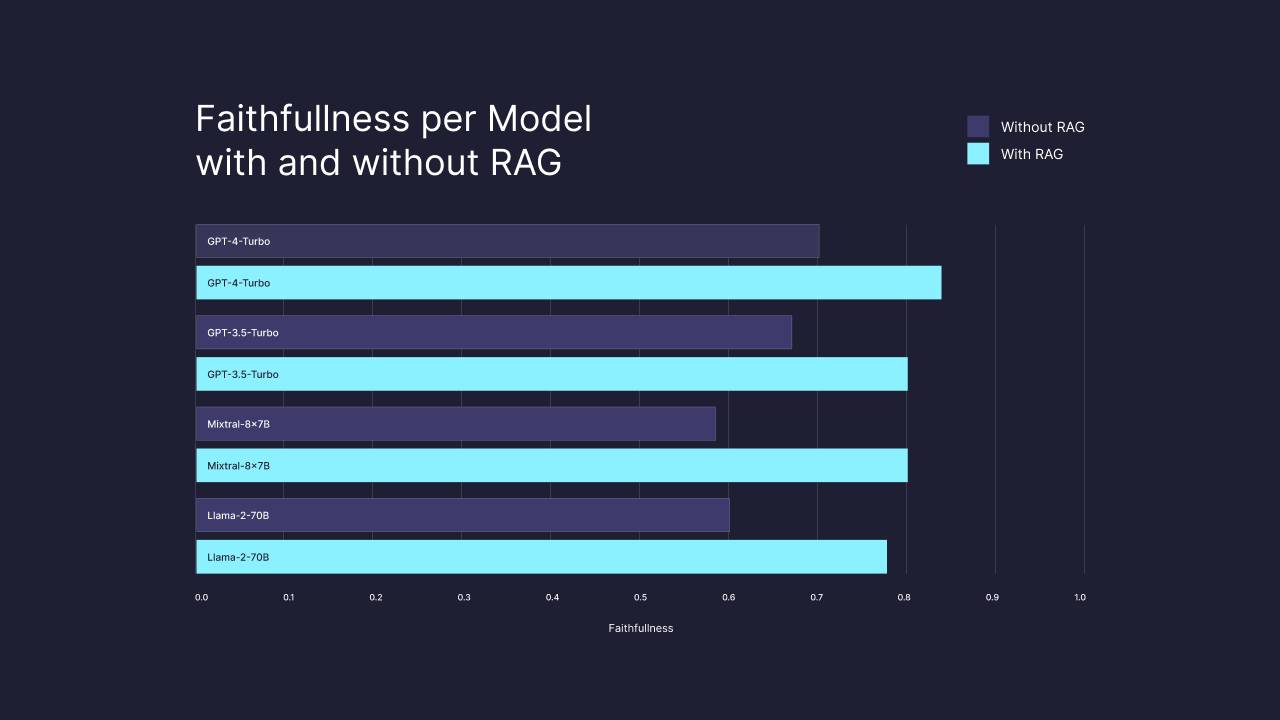
Retrieval-Augmented Generation (RAG) in combination with large data sets significantly improves the performance of LLMs.
Recent research by a team at Pinecone has investigated the impact of using Retrieval-Augmented Generation (RAG) on the performance of large language models in generative AI applications. The results show that RAG significantly improves the performance of LLMs, even on questions that are within their training domain. Moreover, the positive effect increases as more data is available for retrieval. The company tested with sample sizes of up to one billion documents.
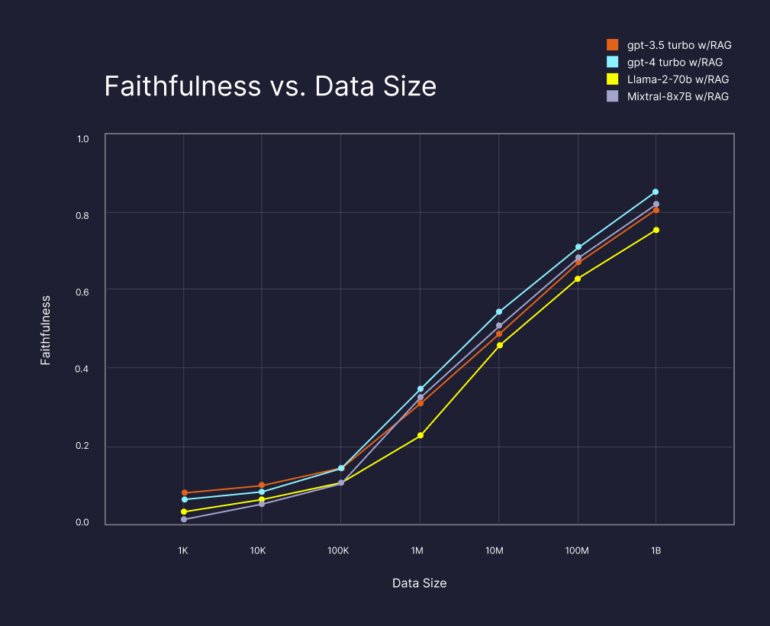
RAG is a methodology that improves the performance of LLMs by allowing these models to access a large amount of external information. This method significantly expands the models' knowledge and enables them to generate more accurate, reliable, and contextually relevant answers.
Open-source models with RAG are significantly more reliable
For the experiment, the researchers used the Falcon RefinedWeb dataset, which contains 980 million web pages from CommonCrawl. These were divided into sections of 512 tokens, from which a random sample of one billion was drawn. They then used GPT-4-Turbo to generate 1,000 open-ended questions with a broad distribution across the dataset. The models were then tested by instructing them to answer these questions using either only their internal knowledge or the information retrieved with RAG.
In all experiments, the following prompt was used to instruct the model to draw information exclusively from the knowledge base and to prevent hallucinations. It is well known that large language models tend to invent an answer even if they do not know it.
Use the following pieces of context to answer the user question. This context retrieved from a knowledge base and you should use only the facts from the context to answer.
Your answer must be based on the context. If the context does not contain the answer, just say that 'I don't know', don't try to make up an answer, use the context.
Don't address the context directly, but use it to answer the user question like it's your own knowledge.
Answer in short, use up to 10 words.Context:
{context}From the study
The experiments with the open-source models LLaMA-2-70B and Mixtral-8x-7B also showed how important it is to adhere strictly to the given context and not fall back on internal knowledge.
Your answer must be based on the context, don't use your own knowledge. Question: {question}
From the study
More data is better?
Pinecone's study shows that simply having more data available for context retrieval significantly improves the results of LLMs, even when the data size is increased to one billion, regardless of the LLM chosen. Compared to GPT-4 alone, GPT-4 with RAG and sufficient data significantly improved the quality of responses by 13 percent for the “faithfulness” metric, even for information on which the LLM was trained. According to Pinecone, this metric indicates how factually correct an answer is.
In addition, the study showed that the same performance (80 percent faithfulness) can be achieved with other LLMs, such as the open-source LLaMa-2-70B and Mixtral-8x-7B models, as long as sufficient data is provided via a vector database.
As an additional metric of faithfulness, the researchers examined the relevance of the responses. This shows high values in all experiments, which can only be slightly increased by RAG, up to three percent for GPT-4 and up to five percent for LLaMa.

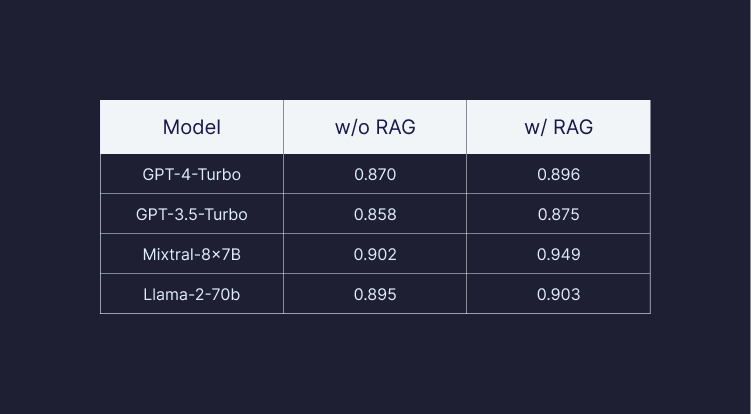
The research suggests that RAG can significantly improve the results of large language models with sufficient data. Previous studies by Microsoft and Google, for example, had already suggested this. However, the potential of scaling is now becoming apparent: the more data that can be searched, the more accurate the results.