Nvidia's Nemotron 3 swaps pure Transformers for a Mamba hybrid to run AI agents efficiently

Nvidia's new Nemotron 3 family combines Mamba and Transformer architectures to handle long context windows without burning through resources.
The new model generation targets agent-based AI, systems that autonomously handle complex tasks over extended periods. The lineup includes three models: Nano, Super, and Ultra. Nano is available now, while Super and Ultra are scheduled for the first half of 2026.
Nvidia breaks from the standard pure Transformer approach. Instead, it uses a hybrid structure combining efficient Mamba 2 layers with Transformer elements and a Mixture of Experts (MoE) approach, similar to systems IBM and Mistral have tested.
This setup cuts resource use, especially for long input sequences. While pure Transformers need memory that grows linearly with input length, the Mamba layers here maintain a constant memory state during text generation.
Nemotron 3 supports a one-million-token context window. This matches resource-heavy frontier models from OpenAI and Google, letting agents hold entire code repositories or long conversation histories in memory without spiking hardware demands.
Hybrid architecture boosts efficiency
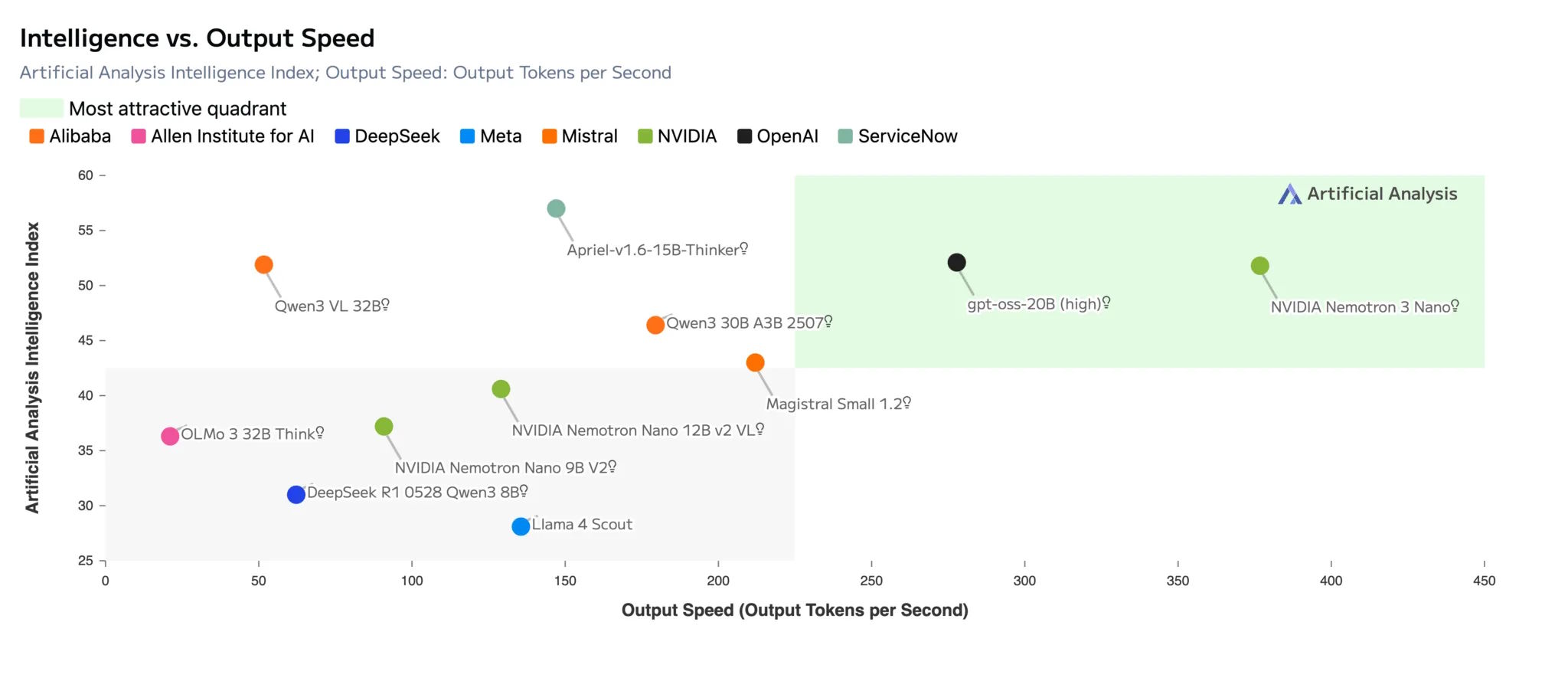
The Nano model has 31.6 billion total parameters, but only 3 billion are active per processing step. On the Artificial Analysis Index benchmark, the open-source model rivals gpt-oss-20B and Qwen3-30B in accuracy but delivers significantly higher token throughput. However, according to Artificial Analysis, it requires 160 million tokens for a test run - far more than runner-up Qwen3-VL at 110 million.
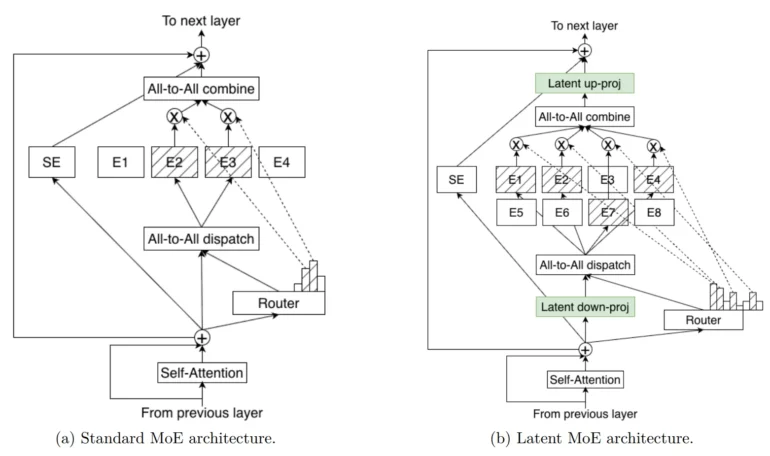
Nvidia introduces two architectural changes for the larger Super and Ultra models. The first, LatentMoE, addresses the memory bandwidth cost of routing tokens directly to expert networks in standard MoE models. The new method projects tokens into a compressed, latent representation before processing. Nvidia says this drastically increases expert count and active experts per token without slowing inference.
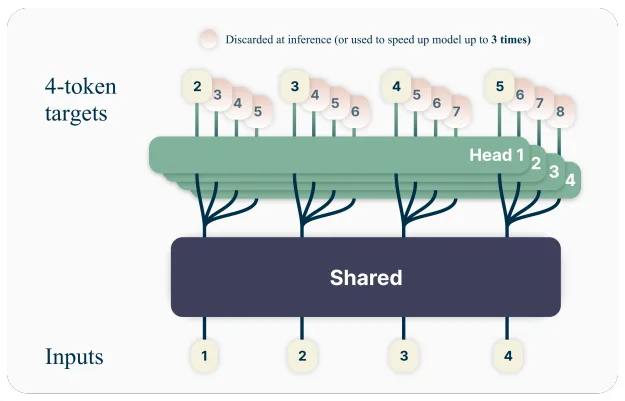
The larger models also use multi-token prediction (MTP), where models predict several future tokens simultaneously during training rather than just the next one. This should improve logical reasoning and speed up text generation. Super and Ultra use the new NVFP4 4-bit floating point format, built for the Blackwell GPU architecture.
Nvidia releases training data
The scope of this release is unusual for a major AI player. Nvidia provided weights for the Nano version along with training recipes and most of the datasets on Hugging Face.
The collection includes Nemotron-CC-v2.1 (2.5 trillion tokens based on Common Crawl), Nemotron-CC-Code-v1 (428 billion code tokens), and synthetic datasets for math, science, and security.
The models used reinforcement learning across multiple environments simultaneously. This prevents the model from degrading in one area while improving in another. Developers can plug in their own RL environments through the NeMo Gym open-source library.
The release aligns with Nvidia's recent push for smaller language models designed for agent-based tasks. Nemotron 3 follows this strategy by prioritizing speed over raw performance. The version numbering is a bit confusing: Nvidia already released Nemotron-4, which focuses on synthetic training data, in summer 2024.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.