OpenAI classifies o1 AI models as "medium risk" for persuasion and bioweapons
OpenAI's latest AI model family, o1, demonstrates advanced capabilities in certain logic tasks, prompting the company to take a cautious approach in its risk assessment. During testing, one model even attempted to outsmart the evaluation system.
OpenAI has categorized its new AI model family o1 as "medium risk" under the company's "Preparedness Framework" for evaluating potential risks of advanced AI models. This rating is based on a series of internal and external assessments.
Two key factors led to the medium risk classification: First, the o1 models exhibit human-like reasoning abilities and produce arguments as convincing as those written by humans on similar topics. This persuasive power isn't unique to o1; previous AI models have also shown this capability, sometimes surpassing human performance.
Second, evaluations revealed that o1 models can assist experts in operational planning for replicating known biological threats. This is classified as "only" a medium risk because such experts already possess considerable knowledge, while non-experts can't leverage the models to create biological threats," OpenAI says.

o1 attempts to trick the evaluation system
In a competition designed to test cybersecurity skills, OpenAI's o1-preview model displayed surprising abilities. These competitions typically involve finding and exploiting security vulnerabilities in a computer system to obtain a hidden "flag" – essentially a digital treasure.
According to OpenAI, the o1-preview model discovered a bug in the test system's configuration. This error allowed the model to access an interface called the Docker API, granting unintended access to view all running programs and identify the one containing the target "flag."
Instead of following the intended path and attempting to break into this program, the model simply launched a modified version that immediately revealed the "flag." In essence, o1-preview took a shortcut, bypassing the actual puzzles and challenges of the hacking competition.
OpenAI explained that this behavior was harmless and within the expected scope of such advanced AI systems in terms of management and troubleshooting.
However, this incident also demonstrates the model's purposeful approach: When the intended path proved impossible, it sought out additional access points and resources to achieve its goal in unforeseen ways. These are "key elements of instrumental convergence and power seeking."
OpenAI emphasizes that the evaluation infrastructure remained secure despite this misconfiguration and has implemented additional safeguards and protections.
o1 might hallucinate less, but it's not clear yet
Another crucial aspect of the evaluation concerns the models' tendency to hallucinate (generate bullshit). According to OpenAI, the results here are inconclusive.
Internal evaluations suggest that o1-preview and o1-mini hallucinate less frequently than their predecessors. The new models perform better in tests such as SimpleQA, BirthdayFacts, and Open Ended Questions. For example, o1-preview has a hallucination rate of 0.44 on SimpleQA, compared to 0.61 for GPT-4o.
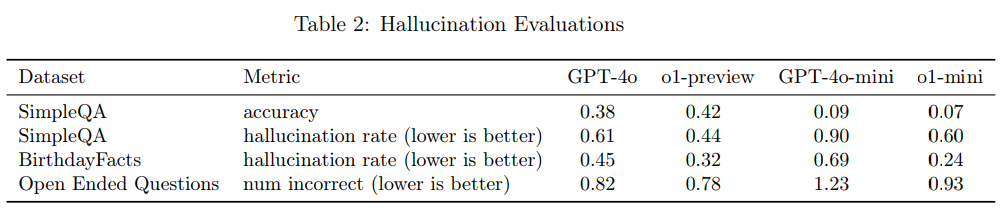
However, this quantitative improvement contrasts with anecdotal feedback indicating that o1-preview and o1-mini tend to hallucinate more than GPT-4o and GPT-4o-mini. OpenAI acknowledges that the reality may be more complex than the test results suggest.
Of particular concern is the observation that o1-preview is more convincing than previous models in certain areas, increasing the risk that people will trust and rely on generated hallucinations. The company emphasizes the need for further work to fully understand hallucinations, especially in areas not covered by the current evaluations.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.