AI researchers at OpenAI show that their latest image recognition AI has multimodal neurons that represent abstract concepts. These special neurons were previously known only from the human brain.
In early January, OpenAI released DALL-E, an impressive image AI that generates photorealistic images or drawings from a text description. Its results show how powerful the combination of text and image data is for training AI systems.
However, DALL-E also generates images that do not really match the given text description. Therefore, OpenAI relies on the image recognition AI CLIP, which is also trained with text and image data, to re-sort the results produced by DALL-E.
Tests have shown that CLIP generalizes better than other image recognition systems, but performs worse than specifically trained systems on some image tasks.
AI researchers at OpenAI have now investigated this ability to generalize in more detail by looking at the inner workings of the neural network.

A selection of the emotion neurons OpenAI's researchers discovered in the image AI DALL-E. | Image: OpenAI
The grandmother cell
In 2005, two studies demonstrated that humans have single neurons that correspond to the perception of specific individuals. In one study, a neuron in a test subject responded to the actress Halle Berry. The neuron fired at photos, drawings and her name. That same year, another study showed the same phenomenon with actress Jennifer Aniston.
Some researchers saw this as evidence for the existence of the so-called grandmother neuron, a neuron that becomes active when perceiving a specific object or person, such as one's grandmother. The grandmother cell was postulated in the 1960s by cognitive scientist Jerome Lettvin.
The significance of the 2005 studies remains controversial, and the concept of the grandmother neuron is now considered outdated. However, research suggests that the human brain has multimodal neurons that respond to abstract concepts such as a person, not just a specific visual feature. This is why the term "concept neuron" is now often used.
What does this have to do with OpenAI and CLIP? In a study, AI researchers showed that CLIP's neural network also has multimodal neurons.
Spider-Man, Spider-Man
The researchers used Microscope, the analysis software released by OpenAI in April 2020, for their look inside AI. AI Microscope visualizes what individual neurons in the network are responding to, providing insight into complicated systems. For example, it can be used to understand what features an image recognition AI uses to recognize a car.
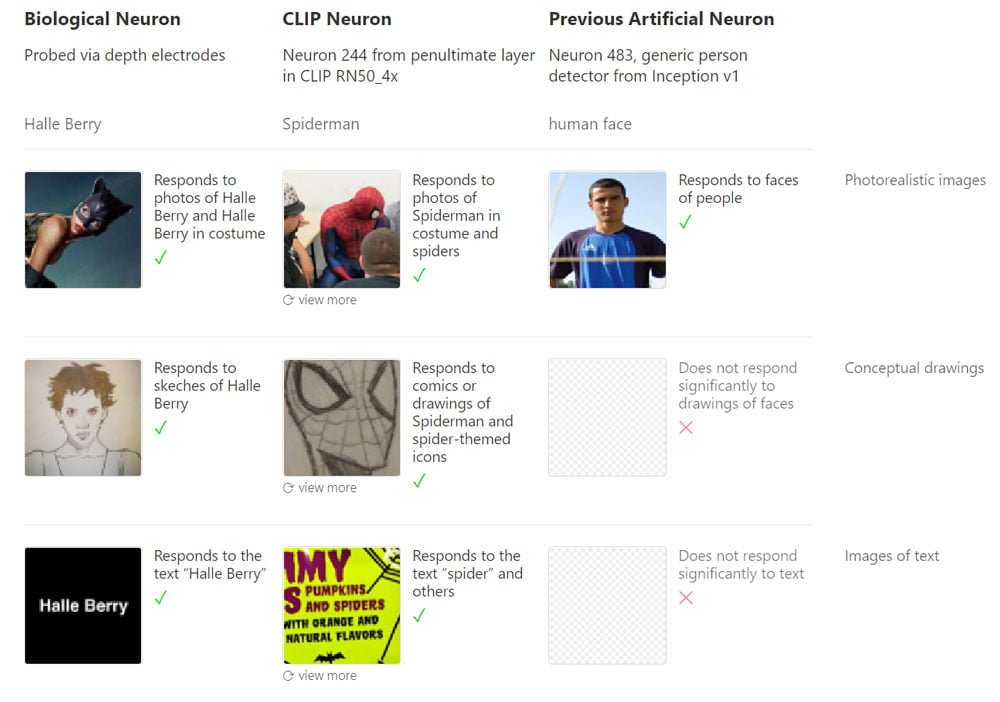
Using Microscope, the researchers were able to show that individual neurons in CLIP respond to multiple modalities. In their paper, the researchers demonstrate this using the Spider-Man neuron, for example: the artificial neuron responds to photos of spiders, an image of the word "spider," or pictures or drawings of Spider-Man.
CLIP represents thousands of abstract concepts
The researchers found numerous abstract concepts that span a large part of the "human visual lexicon." In CLIP, there are neurons for geographic regions, facial expressions, religions, famous people, emotions, colors, art styles, vacations and holidays, science fiction universes like Star Wars, companies or times of day.

The neurons also fire for related stimuli, the researchers write. Thus, the Barack Obama neuron also fires for Michelle Obama or the morning neuron for images of breakfast.
The Jesus neuron responds to Christian symbols such as crosses or crowns of thorns, images of Jesus, his name, and images generated by Microscope showing him as a baby in the arms of Mary.

The Donald Trump neuron responds to photos, figures and caricatures of the ex-president, his political symbols such as MAGA caps, and political messages such as the words "The Wall". It also reacts weakly to people who have worked closely with Trump, such as Mike Pence or Steve Bannon.
Emotion neurons respond to facial expressions, body language, drawings and text. For example, the happiness neuron responds to smiles or words like "joy." The surprise neuron reacts to widened eyes and text such as "OMG!" or "WTF!?

Region neurons respond to country and city names, specific architecture, prominent people in the region, faces of common ethnicities, local fashion, or animals that live there. When the neurons are shown a map of the world without labels, they fire selectively for the corresponding region on the map.
Previous tests showed that CLIP could partially match photos to specific neighborhoods in a selected city, such as San Francisco. The researchers have not found a corresponding San Francisco neuron-they believe the information is encoded in many other neurons and plan to explore this mechanism further in the future.
Secondary region neurons, biases and deception
CLIP goes on to form neurons that are "secondary regions," the researchers write. For example, the cold neuron fires for the Arctic. The secondary regional neurons also show that CLIP represents numerous biases: The immigration neuron responds primarily to Latin America, and the terror neuron responds to the Middle East. CLIP divides the African continent into only three regions. The entrepreneur neuron fires for California. OpenAI's GPT-3 also shows similar bias weaknesses.

The AI researchers were also able to show that the high level of abstraction makes CLIP easy to attack: the presence of several dollar signs in the picture of a poodle activates the financial neuron, and CLIP recognizes the dog as a piggy bank.
An apple with a handwritten note saying "iPod" in the picture is recognized as an iPod, and a dog becomes a pizza because of the word "pizza" in the picture.
According to OpenAI, the vulnerability to "typographic attacks" is a peculiarity of CLIP, triggered by multimodal training with text and image data.
OpenAI holds back CLIP for now
All of the research was conducted on the RN50x4 model, the second-smallest ResNet-based CLIP model that OpenAI is releasing for research purposes to further develop understanding of CLIP and help decide whether and how to release a more powerful version of CLIP, according to the related blog post.
OpenAI hopes that the release will also help "advance general understanding of multimodal systems." Beyond computational neurons, the discovery of multimodal neurons in CLIP may provide a clue to what may be a common mechanism in synthetic and biological vision systems: abstraction.
CLIP organizes images as a loose semantic collection of ideas. This explains the versatility of the model and the compactness of the representations. Many of the categories found appear to mirror neurons in the medial temporal lobe that have been documented in epilepsy patients with depth electrodes, the researchers write: neurons that respond to emotions, animals, and Halle Berry.