OpenAI launches GPT-5.4 Thinking and Pro combining coding, reasoning, and computer use in one model

Key Points
- OpenAI introduces GPT-5.4, which for the first time combines coding, reasoning, agentic workflows, and native computer operation in a single model.
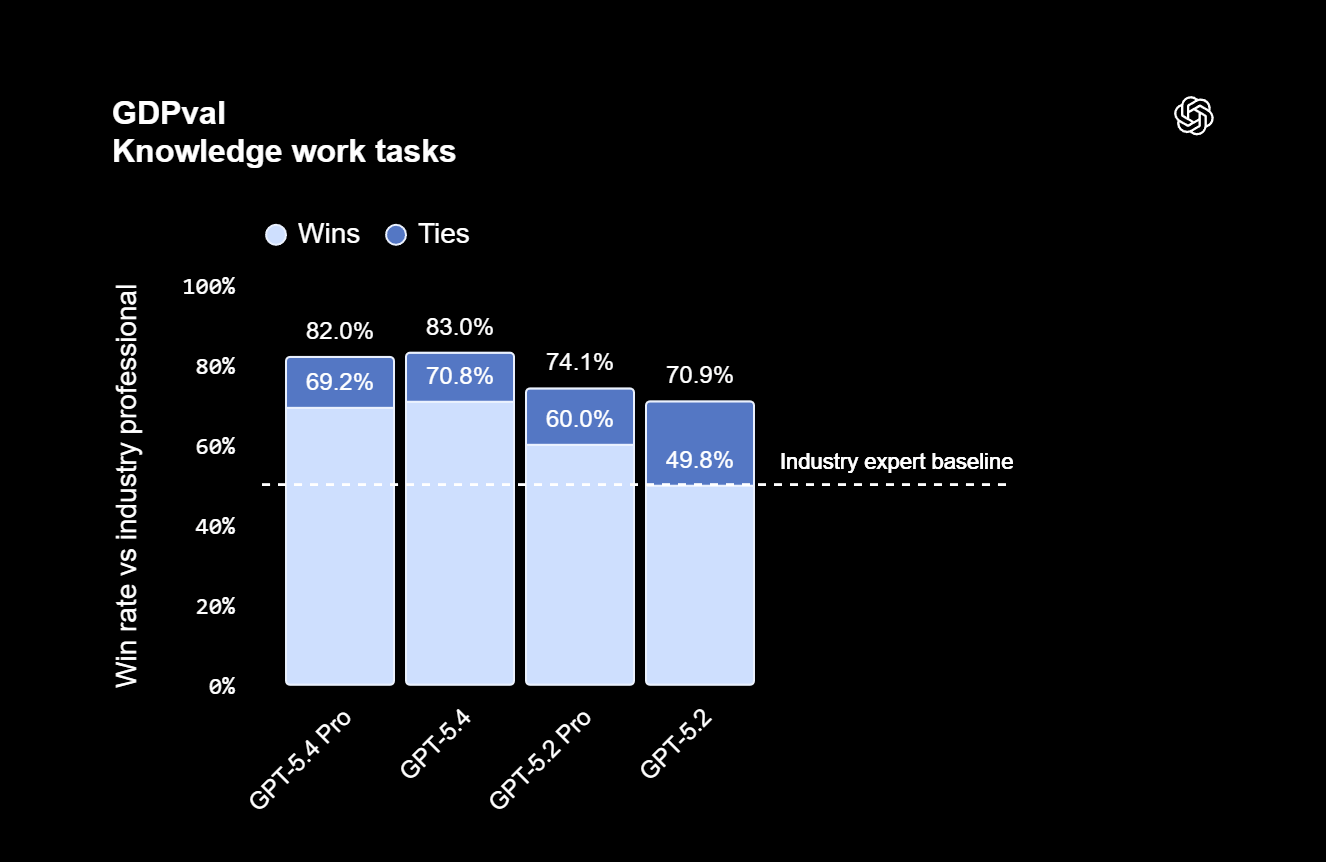
- On the GDPval benchmark for professional knowledge work, the new model scored 83.0 percent compared to 70.9 percent for its predecessor GPT-5.2, marking a substantial performance jump.
- A key technical addition is "Tool Search" in the API, which retrieves tool definitions only when needed rather than loading them all into the prompt, cutting token consumption by 47 percent in tests, though token prices increase in return.
GPT-5.4 is OpenAI's most capable model yet, combining coding, computer operation, and reasoning in a single package for the first time.
OpenAI has released GPT-5.4, available in ChatGPT as GPT-5.4 Thinking, in the API, and in Codex. Alongside it comes GPT-5.4 Pro, a beefed-up version built for particularly complex tasks. OpenAI calls it the company's "most capable and efficient frontier model for professional work."
For the first time, the model combines the coding capabilities of the recently released GPT-5.3 Codex with improved reasoning, agentic workflows, and native computer use. OpenAI describes GPT-5.4 as the first "mainline reasoning model" to integrate the frontier coding capabilities of GPT-5.3 Codex. There was no 5.3 Thinking model, only the Codex variant. The numbering reflects this leap and is meant to simplify model selection in Codex, OpenAI says.
The company just shipped the 5.3 Instant model on Tuesday, which currently serves as the default chat model in ChatGPT. Going forward, OpenAI says Instant and Thinking models will continue to develop at different speeds.
GPT-5.4 matches or beats professionals across 44 occupations in academic benchmark
OpenAI is clearly positioning GPT-5.4 as a tool for office work. On the company's in-house GDPval benchmark, which tests agents across 44 professions from the nine industries contributing most to US GDP, GPT-5.4 scores 83.0 percent, meeting or exceeding industry professionals. That's up from 70.9 percent for GPT-5.2. Interestingly, the standard 5.4 Thinking model actually outperforms the Pro version here.
The biggest gains show up in spreadsheets: for investment banking modeling tasks, GPT-5.4 scored 87.3 percent compared to 68.4 percent for its predecessor. For presentations, human evaluators preferred GPT-5.4's output 68 percent of the time, citing better aesthetics and visual variety. OpenAI has also launched a new ChatGPT add-in for Excel aimed at enterprise customers.
GPT-5.4 also shows consistent improvement on academic benchmarks, particularly in abstract reasoning: GPT-5.4 Pro hit 83.3 percent on ARC-AGI-2, while GPT-5.2 Pro managed just 54.2 percent.
| Eval | GPT-5.4 | GPT-5.4 Pro | GPT-5.3 Codex | GPT-5.2 | GPT-5.2 Pro |
|---|---|---|---|---|---|
| Frontier Science Research | 33.0% | 36.7% | - | 25.2% | - |
| FrontierMath Tier 1-3 | 47.6% | 50.0% | - | 40.7% | - |
| FrontierMath Tier 4 | 27.1% | 38.0% | - | 18.8% | 31.3% |
| GPQA Diamond | 92.8% | 94.4% | 92.6% | 92.4% | 93.2% |
| Humanity's Last Exam (no tools) | 39.8% | 42.7% | - | 34.5% | 36.6% |
| Humanity's Last Exam (with tools) | 52.1% | 58.7% | - | 45.5% | 50.0% |
| ARC-AGI-1 (Verified) | 93.7% | 94.5% | - | 86.2% | 90.5% |
| ARC-AGI-2 (Verified) | 73.3% | 83.3% | - | 52.9% | 54.2% (high) |
OpenAI also says it has reduced hallucinations further: individual claims are 33 percent less likely to be wrong, and complete answers are 18 percent less likely to contain errors compared to GPT-5.2.
"We see no wall, and expect AI capabilities to continue to increase dramatically this year," writes OpenAI researcher Noam Brown, one of the key figures behind OpenAI's reasoning model breakthrough.
GPT-5.4 beats humans at navigating desktop environments
GPT-5.4 is OpenAI's first general model with native computer use. Agents can use screenshots, mouse, and keyboard input to control websites and software, handling complex tasks on their own. Previously, this feature was only available in ChatGPT through agent mode, but it worked unreliably and was rarely used.
That might be changing now. On the OSWorld Verified benchmark, which measures navigation in desktop environments, GPT-5.4 hit a 75.0 percent success rate. GPT-5.2 sat at 47.3 percent, and the human comparison group scored 72.4 percent, making this the first time the model has surpassed human performance on this test.
Visual perception got an upgrade too. OpenAI is introducing a new original image detail mode that processes images at up to 10.24 million pixels in full resolution. On the document parsing benchmark OmniDocBench, the average error rate drops from 0.140 to 0.109.
Coding gains are modest, but speed gets a boost
On the coding front, GPT-5.4 scores 57.7 percent on SWE-Bench Pro, just slightly above GPT-5.3 Codex (56.8 percent) and GPT-5.2 (55.6 percent). The real advantage is speed: a new "/fast" mode in Codex boosts token speed by up to 1.5x without sacrificing model quality.
Agentic web search has also improved. On the BrowseComp benchmark, which measures how well AI agents track down hard-to-find information on the web, GPT-5.4 scores 82.7 percent and GPT-5.4 Pro reaches 89.3 percent, up from 65.8 percent for GPT-5.2.
| GPT-5.4 | GPT-5.3-Codex | GPT-5.2 | |
|---|---|---|---|
| GDPval (wins or ties) | 83.0% | 70.9% | 70.9% |
| SWE-Bench Pro (Public) | 57.7% | 56.8% | 55.6% |
| OSWorld-Verified | 75.0% | 74.0%* | 47.3% |
| Toolathlon | 54.6% | 51.9% | 46.3% |
| BrowseComp | 82.7% | 77.3% | 65.8% |
To show off the combined coding and computer-use capabilities, OpenAI is releasing an experimental Codex skill called "Playwright (Interactive)" that lets Codex visually debug web and Electron apps. In a demo, GPT-5.4 generated an isometric theme park simulation game, complete with path placement, guest pathfinding, and queues, from a single prompt, the company claims.
Tool Search cuts token consumption by nearly half
One of the most interesting technical changes is "Tool Search" in the API. Previously, all tool definitions were loaded into the prompt in full, eating up thousands of extra tokens in large tool ecosystems. GPT-5.4 takes a different approach: it only receives a lightweight list of available tools and pulls up complete definitions on demand.
OpenAI says this cut token consumption by 47 percent in a test with 250 tasks from the MCP Atlas benchmark while maintaining accuracy. For MCP servers with tens of thousands of tokens in tool definitions, the savings should be substantial.
The reasoning process is getting more efficient too. In ChatGPT, GPT-5.4 Thinking shows a preview of its planned approach for complex requests. Users can add instructions or change direction before the model finishes its response, reducing the number of back-and-forth queries. The feature is live on chatgpt.com and Android, with iOS coming soon.
GPT-5.4 in Codex also experimentally supports a context window of up to one million tokens, which should be useful for long-term planning and execution tasks. That said, cramming in too much or imprecise context still tends to make the model less reliable.
Token prices go up, but OpenAI says efficiency offsets the cost
GPT-5.4 costs more than its predecessor. OpenAI argues that as the "most token-efficient reasoning model," it needs significantly fewer tokens for the same tasks, which should offset the higher per-token pricing.
| API model | Input price | Cached input price | Output price |
|---|---|---|---|
| gpt-5.2 | $1.75 / M tokens | $0.175 / M tokens | $14 / M tokens |
| gpt-5.4 | $2.50 / M tokens | $0.25 / M tokens | $15 / M tokens |
| gpt-5.2-pro | $21 / M tokens | - | $168 / M tokens |
| gpt-5.4-pro | $30 / M tokens | - | $180 / M tokens |
In ChatGPT, GPT-5.4 Thinking is now available for Plus, Team, and Pro users, replacing GPT-5.2 Thinking. The older model will stick around for three months under "Legacy Models" before being discontinued on June 5, 2026. Enterprise and Edu users can enable access through admin settings. GPT-5.4 Pro is available on Pro and Enterprise plans.
Cybersecurity rating jumps to "High Capability" for the first time in a general model
According to the Model Card, the cybersecurity rating stands out as a key development on the safety front. Like the specialized coding model GPT-5.3 Codex before it, GPT-5.4 is classified as "High Capability" in cybersecurity. But GPT-5.4 Thinking is the first general reasoning model to receive this classification, which significantly broadens its scope and its potential attack surface.
Under OpenAI's Preparedness Framework, the "High" level means a model can remove existing barriers to cyberattacks, for example by automating end-to-end attacks on protected targets or automatically finding and exploiting operationally relevant security vulnerabilities. The only level above this is "Critical," where a model can find zero-day exploits in hardened systems without human help and independently develop new attack strategies.
OpenAI says it has built a new protection system for 5.4: instead of downgrading suspicious users to a weaker model, the system now uses real-time blockers at the message level, backed by a two-stage monitoring system consisting of a topic classifier and an AI-powered security analyst. On standard security benchmarks, the model performs roughly on par with GPT-5.2 Thinking, while jailbreak resistance has improved significantly compared to GPT-5.1 Thinking.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe now