
OpenAI's Superalignment team has published its first results on controlling future superhuman AI systems.
"We believe superintelligence—AI vastly smarter than humans—could be developed within the next ten years." This is how the new article from OpenAI begins. Controlling and managing such systems is a major challenge.
Earlier this year, OpenAI set up the Superalignment team to focus on possible superintelligence and announced that it would devote twenty percent of its available computing resources to research.
Can weak intelligence guide stronger intelligence?
One of the team's goals is to investigate whether and how humans or AI systems can supervise superior systems, similar to how humans today supervise weaker models through RLHF.
In the context of artificial superintelligence, the team sees humans as "weak supervisors". The challenge is how weak supervisors can control and trust much stronger AI models without limiting the capabilities of the stronger model.
To explore this challenge, OpenAI proposes an analogy: using a smaller, less powerful AI model to supervise a larger, more powerful AI model.
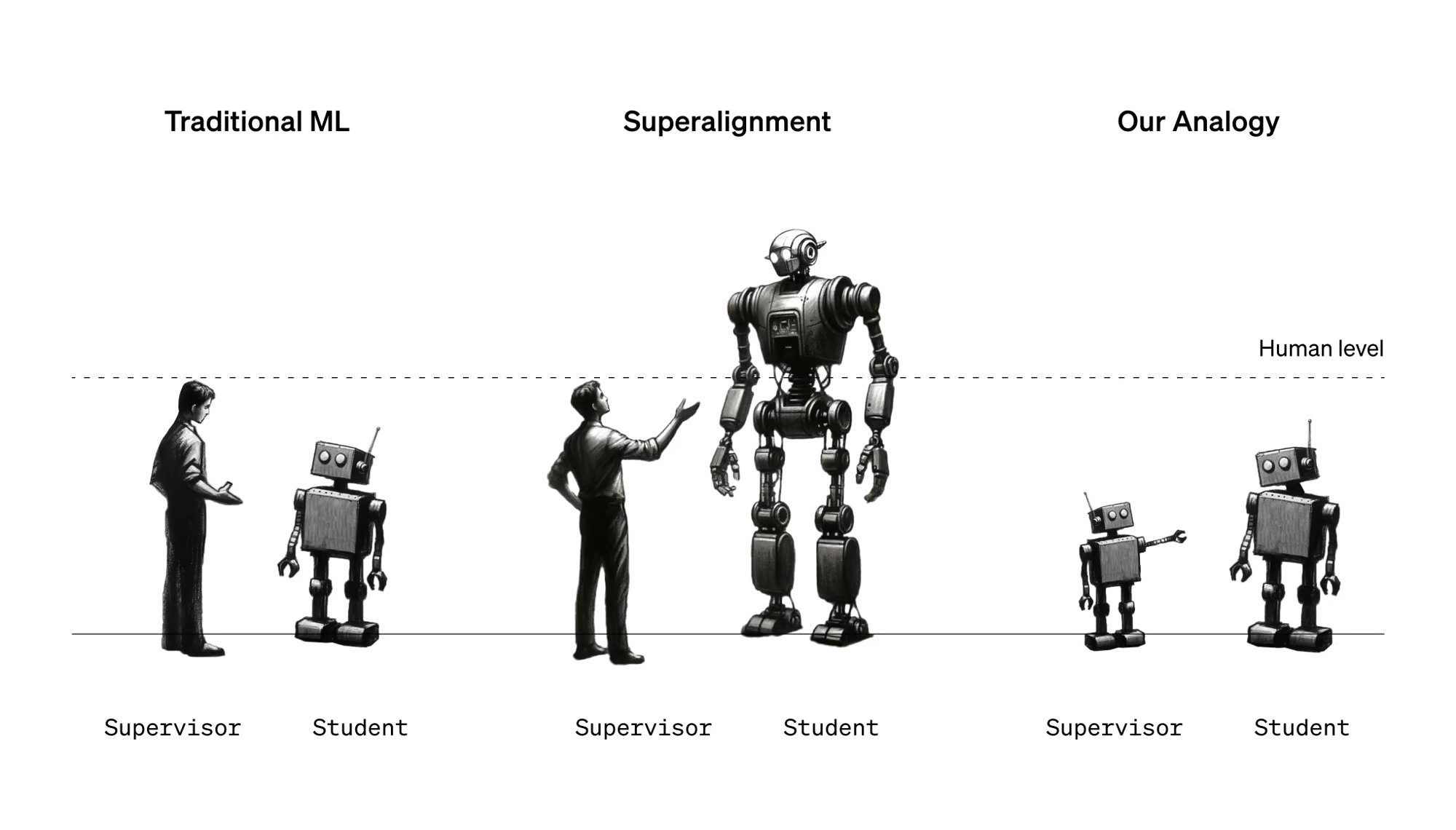
GPT-2 monitors GPT-4
In their experiments, the team had an as-yet unsupervised and not fine-tuned GPT-4 model supervised by a much weaker GPT-2 model, similar to how the available GPT-4 was supervised by RLHF. They used three different methods, two of which used the GPT-2 output as a guide or for fine-tuning. However, this did not produce a model performance even close to that of GPT-3. Using a simple method that encourages the strong model to perform more confidently and to contradict GPT-2 if necessary by adding an auxiliary confidence loss during fine-tuning, the performance of the resulting model was generally between GPT-3 and GPT -3.5. While this is not at the level of a fine-tuned and RLHF version of GPT-4, it showed that there is a way for a weaker model to supervise the inherent capabilities of a more advanced model and achieve what the team calls weak-to-strong generalization.
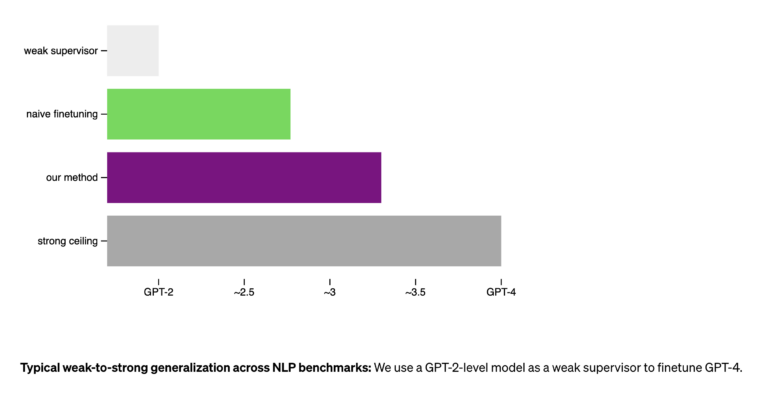
The company considers the method to be a proof of concept with limitations. The results indicate that methods such as RLHF are difficult to scale up to superhuman models without further development, but that such development appears possible.
OpenAI launches funding program for alignment
"We believe our setup captures some key difficulties of aligning future superhuman models, enabling us to start making empirical progress on this problem today, " the company said.

The company is releasing the code and launching a $10 million grants program for graduate students, academics, and other researchers working on superhuman AI alignment.




