OpenClaw-RL trains AI agents "simply by talking," converting every reply into a training signal

Key Points
- Researchers at Princeton University have developed OpenClaw-RL, a framework that repurposes feedback from ongoing conversations, terminal commands, and tool calls as direct training material for AI agents—data that is typically discarded.
- The system is built on four independent, parallel modules with two complementary learning processes: one evaluates actions in a binary yes-or-no fashion, while the other extracts specific improvement suggestions from feedback, all without requiring a separate teacher model or pre-collected training data.
- After only a few dozen interactions, the AI agents learned to drop typically artificial-sounding phrases and produce more natural language. The code is available on GitHub.
The OpenClaw-RL framework treats signals generated during every interaction as a live training source. Personal conversations, terminal commands, and GUI actions all feed into the same training loop.
Every time an AI agent interacts with a user or environment, it generates a follow-up signal: a user response, a tool result, a status change in the terminal or on screen. Until now, systems only used this information as context for the next action and then tossed it.
Researchers at Princeton University argue this amounts to systematic waste. Their new framework, OpenClaw-RL, is designed to tap these signals as a live training source. Rather than treating personal conversations, command line commands, GUI interactions, software engineering tasks, and tool calls as separate training problems, the framework feeds them all into the same run to improve the same model.
Follow-up signals carry both evaluation and direction
According to the researchers, these follow-up signals encode two types of information that have gone unused until now. The first is evaluative signals. If a user asks the same question again, that flags dissatisfaction. If an automated test passes, the action was successful. These signals act as natural quality assessments for each step without anyone having to manually annotate them. Previous training methods at best used such signals after the fact, pulling from pre-collected data.
The second type is directional signals. When a user writes "You should have checked the file first," that feedback spells out what specifically should have been done differently instead of just flagging what's wrong. Standard reward systems in reinforcement learning compress this kind of feedback into a single number, losing the content-level directional information along the way.
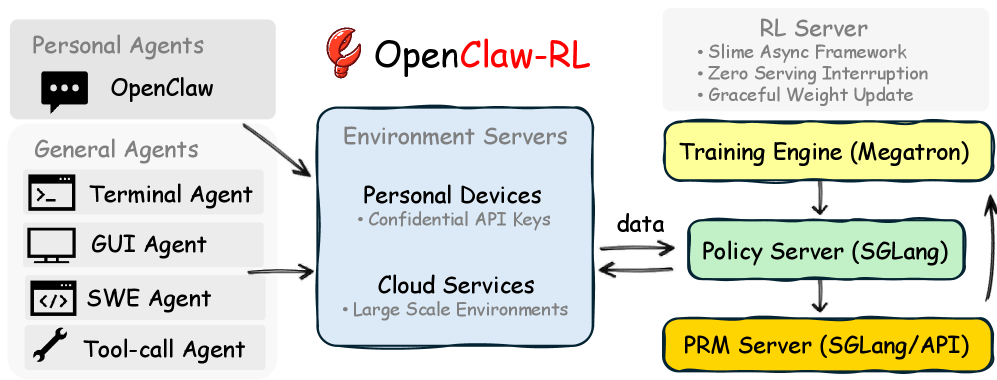
Four decoupled components keep training running during live use
OpenClaw-RL's architecture splits into four decoupled components: one serves the model for queries, one manages the environments, one evaluates response quality, and one handles the actual training. None has to wait for another—the model answers the next user request while an evaluation model scores the previous answer and the training component runs weight updates in parallel.
For personal agents, the user device connects to the training server through a confidential API. Weight updates roll out seamlessly without interrupting ongoing use. For general agents, the system scales through cloud-hosted environments with up to 128 parallel instances.
The model learns from a better-informed version of itself
OpenClaw-RL combines two optimization methods. The simpler one, Binary RL, has an evaluation model classify each action as good, bad, or neutral based on the follow-up signal using majority vote. The result feeds into training as a standard reward.
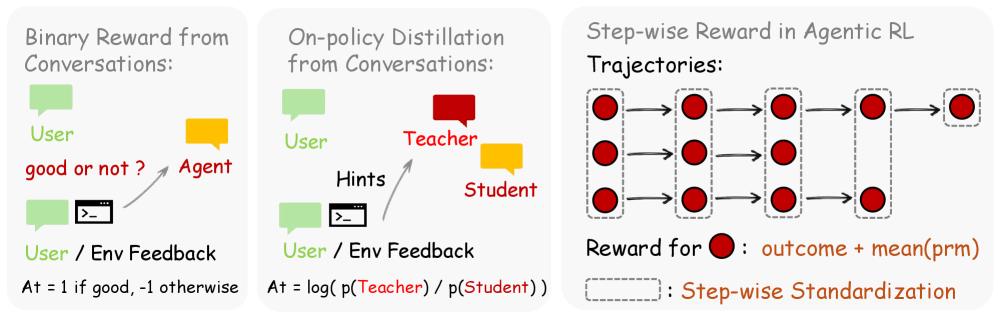
The second method, Hindsight-Guided On-Policy Distillation (OPD), goes much further. An evaluation model distills a specific correction hint of one to three sentences from the follow-up signal, then appends it to the original query. The same model then calculates, with this extended context, how likely it would have generated each individual token of the original response if it had known the hint from the start.
The difference gives a directional signal for each token: the model should favor certain phrasings going forward and avoid others. No separate teacher model or pre-collected data is needed.
Binary RL provides broad coverage across all interactions, while OPD delivers precise corrections at the token level for particularly informative cases. According to the researchers, combining both methods produces the best results.
A few dozen interactions already bring improvements
The researchers tested OpenClaw-RL with the Qwen3-4B model across two simulated scenarios. One has a language model playing a student who uses OpenClaw for homework but doesn't want to get flagged as an AI user. The other simulates a teacher who expects specific, friendly feedback on homework.

In the student setting, the personalization score jumped from 0.17 to 0.76 after just eight training steps with the combined method. Binary RL alone reached 0.25, and OPD alone also hit 0.25 after eight steps but caught up to 0.72 after 16 steps. In the teacher setting, the score rose from 0.22 to 0.90. After just a few dozen interactions, the agent learned to drop obviously AI-like phrasings and write more naturally.
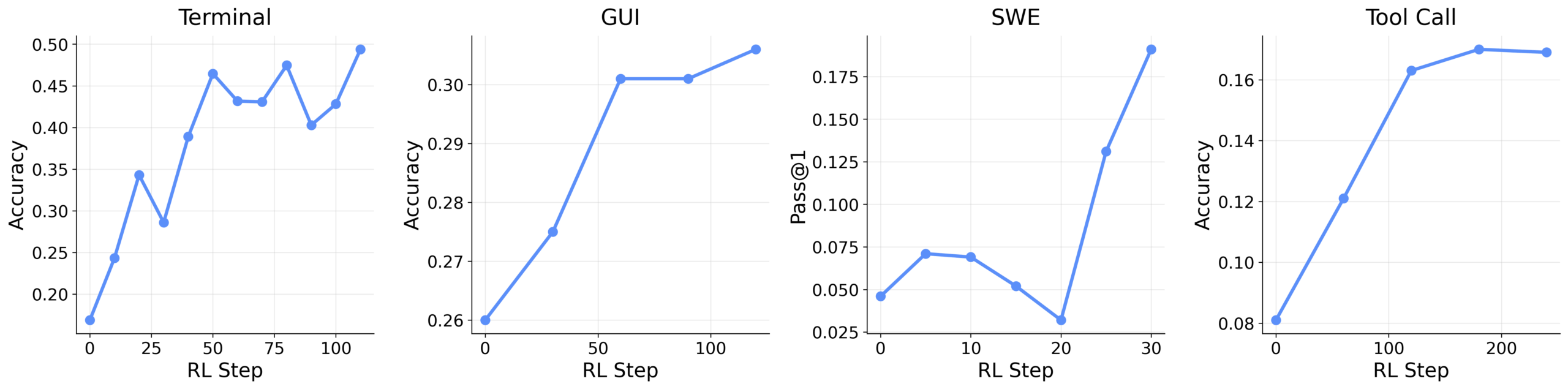
For general agents, the researchers tested the framework with different Qwen3 models across command line, GUI, software engineering, and tool call scenarios. Here too, integrating incremental evaluations helped. In the tool call setting, performance improved from 0.17 to 0.30 and from 0.31 to 0.33 for graphical user interfaces.
The researchers say their framework is the first system to combine multiple simultaneous interaction streams—from personal conversations to software engineering tasks—in a single training loop. The code is available on GitHub.
Although the Princeton framework uses the name of the popular open-source AI agent OpenClaw and builds on its infrastructure, it's an independent research project with no direct connection to the platform's core team. OpenClaw founder Peter Steinberger has transferred the project to a foundation and moved to OpenAI to work on the next generation of personal AI agents.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe now