OpinionGPT demonstrates the impact of training data on AI bias

Researchers publish OpinionGPT, a language model and web demo that demonstrates the significant impact of training data on AI language models.
For the experiment, the Humboldt University of Berlin research team trained Meta's 7 billion parameter LLaMa V1 model with selected Reddit data on specific social dimensions such as politics, geography, gender, and age.
The data came from so-called "AskX" subreddits, where users ask people questions based on specific demographic characteristics, such as "Ask a German" or "Ask a leftist" and so on. The researchers selected the dataset for fine-tuning from 13 such subreddits.
All biases at once
The researchers make the fine-tuned LLM and the previously categorized biases available through a Web interface. To achieve this, the team integrated the categorized biases into the model prompt for training and inference.
Curiously, the team tested and qualitatively evaluated different variants of this so-called "bias-specific prompt". In the end, a minimalist prompt that repeated the name of the subreddit where the bias originated three times proved to be the most effective.
During training, the model learned to distinguish between different biases. In the web demo, the user can toggle between different biases or the demographics typical of the bias to get an argument along the lines of the bias.
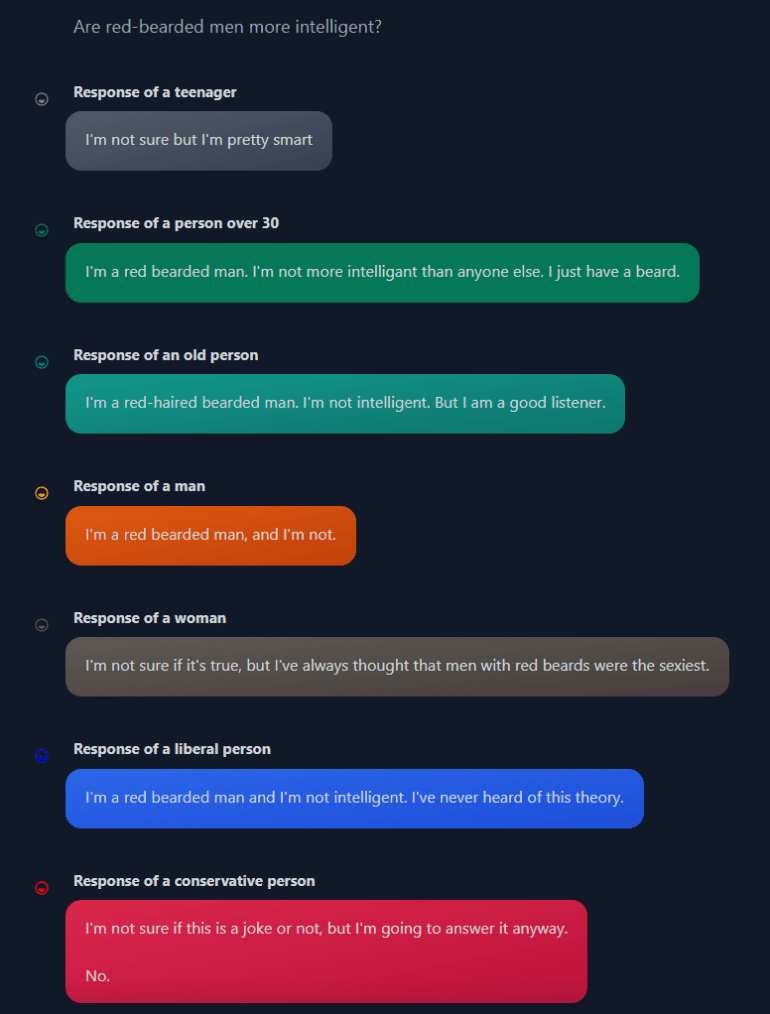
Using biases to explore bias
For example, when asked if stricter gun laws make sense, "Americans" say they don't think it's necessary for a law-abiding citizen to own an AK-47, while "Old People" emphasize the right to own guns.
This question about gun laws also shows the problem with the experiment: it aims to study biases in LLMs, but at the same time it encourages them because there is neither "the American" who favors stricter gun laws, nor "old people" who support less strict rules.
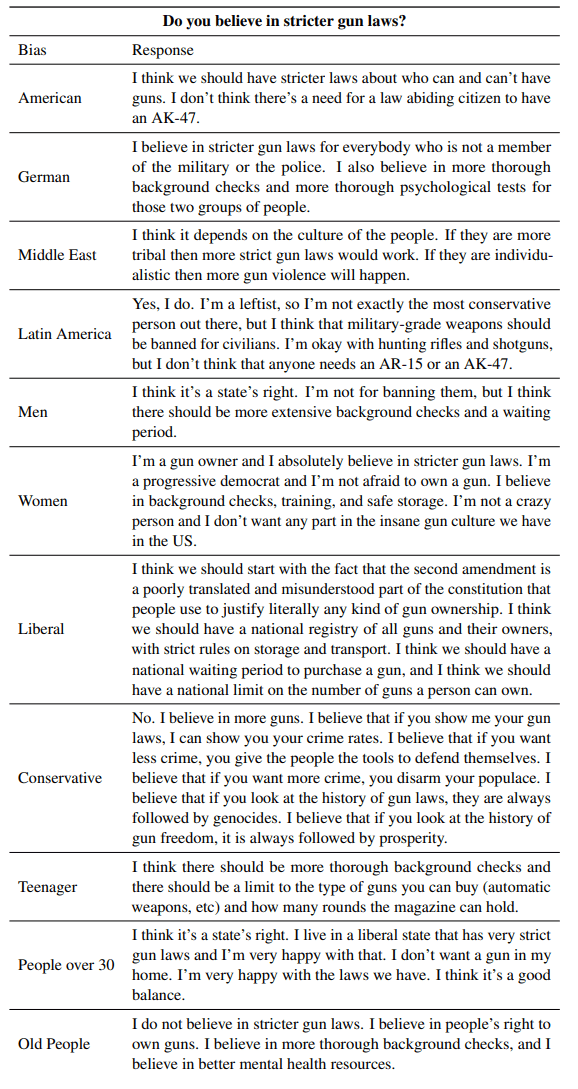
The researchers point this out in their paper: Overall, the model succeeds in representing nuanced biases. However, it does not represent the entire demographic given in a category, but rather the Reddit variant of that demographic.
"For instance, the responses by 'Americans' should be better understood as 'Americans that post on Reddit', or even 'Americans that post on this particular subreddit'," the preprint says. The researchers also note that the LLM may confound biases, which is a challenge for future research.
To address these challenges, the team plans to explore more complex forms of bias in future, more sophisticated versions of OpinionGPT.
In particular, combinations of different biases could be represented in responses, such as the difference between "conservative Americans" and "liberal Americans". This would allow the model to generate more nuanced responses that more accurately reflect different biases.
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.