Perplexity open-sources embedding models that match Google and Alibaba at a fraction of the memory cost

Key Points
- Perplexity has released two open-source embedding models, pplx-embed-v1 and pplx-embed-context-v1, designed to convert search queries and documents into numerical vectors for preselecting relevant websites in AI-powered search engines.
- The models use bidirectional text understanding, allowing them to consider context from both directions within a sentence, which improves the accuracy of matching queries to relevant content.
- By eliminating the need for pre-formulated task descriptions, the models aim to address key limitations of previous embedding approaches, offering a more streamlined and effective retrieval process.
AI search engine Perplexity is introducing two new text embedding models designed to match or beat Google's and Alibaba's offerings at a fraction of the usual memory cost. Both models are open source.
Before a language model can answer a search query, it needs to find the right documents among billions of web pages. That first filtering step is handled by embedding models, which translate queries and documents into numerical vectors so semantic similarity becomes something you can calculate. The quality of these embeddings directly determines what gets passed on to ranking models and, ultimately, to the language model generating the answer.
Perplexity has now released two embedding models, pplx-embed-v1 and pplx-embed-context-v1. The first handles classic dense text retrieval, while the second also embeds passages in the context of their surrounding document; useful for disambiguating tricky sections. Both come in 0.6 billion and 4 billion parameter versions.

Bidirectional reading gives embeddings more context
According to the researchers, most leading embedding models are built on language models that only process text left to right. Each word can only "see" what came before it. That works fine for text generation, but it's a problem for understanding meaning, since a sentence's intent often depends on what comes after.
Perplexity starts with Alibaba's pre-trained Qwen3 models, which originally only read left to right, and modifies them to read in both directions. The model is then trained with a gap-filling method similar to Google's BERT: words are randomly masked in text passages, and the model learns to predict what's missing from surrounding context in both directions. The researchers call this diffusion pre-training.
Training used around 250 billion tokens across 30 languages: half from English educational websites in the FineWebEdu dataset, half covering 29 other languages from FineWeb2. In ablation studies, the bidirectional approach delivered roughly a one percentage point improvement on retrieval tasks.
There's also a practical upside: unlike competing models, pplx-embed doesn't need task descriptions tacked onto each input. Perplexity says those prefixes can actually hurt search quality if they're not consistent between indexing and query time.
Quantization cuts memory requirements by up to 32x
Storing embedding vectors for billions of web pages gets expensive fast. The standard approach uses 32-bit floating point values (FP32). Perplexity instead trains its models from the start to use 8-bit integers (INT8), cutting memory by 4x without losing performance.
An even more compact binary variant—just one bit per value—shrinks requirements by 32x. With the 4B model, the quality loss is under 1.6 percentage points, since its larger 2,560-dimension embedding vector retains more information than the smaller model's 1,024 dimensions, Perplexity claims.
On the MTEB retrieval benchmark (Multilingual, v2), pplx-embed-v1-4B scores an nDCG@10 of 69.66 percent - matching Alibaba's Qwen3-Embedding-4B (69.60 percent) and beating Google's gemini-embedding-001 (67.71 percent), all while using significantly less memory. On the ConTEB contextual retrieval benchmark, pplx-embed-context-v1-4B hits 81.96 percent, topping Voyage's voyage-context-3 (79.45 percent) and Anthropic's contextual model (72.4 percent).
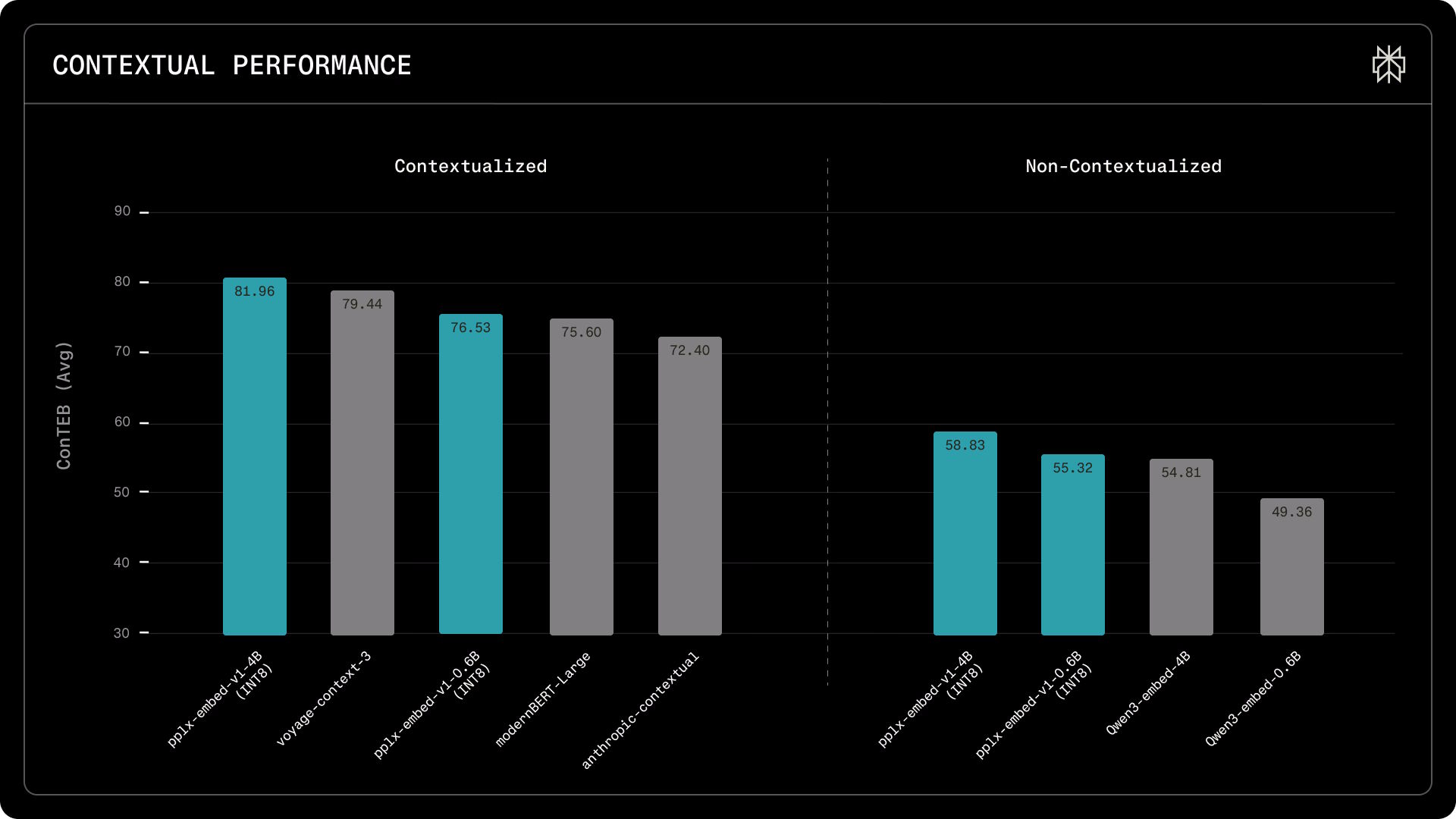
On the BERGEN benchmark, which measures end-to-end RAG performance from document search to generated response, the small pplx-embed-v1-0.6B beats the much larger Qwen3-embedding-4B in three out of five tasks. That makes it a compelling option where latency and compute costs are the priority.
Real search traffic reveals wider performance gaps
Perplexity says public benchmarks only partially reflect real-world search challenges, since unusual queries, noisy documents, and distribution shifts are largely missing. So the company built two internal benchmarks using up to 115,000 real search queries against more than 30 million documents from over a billion websites.
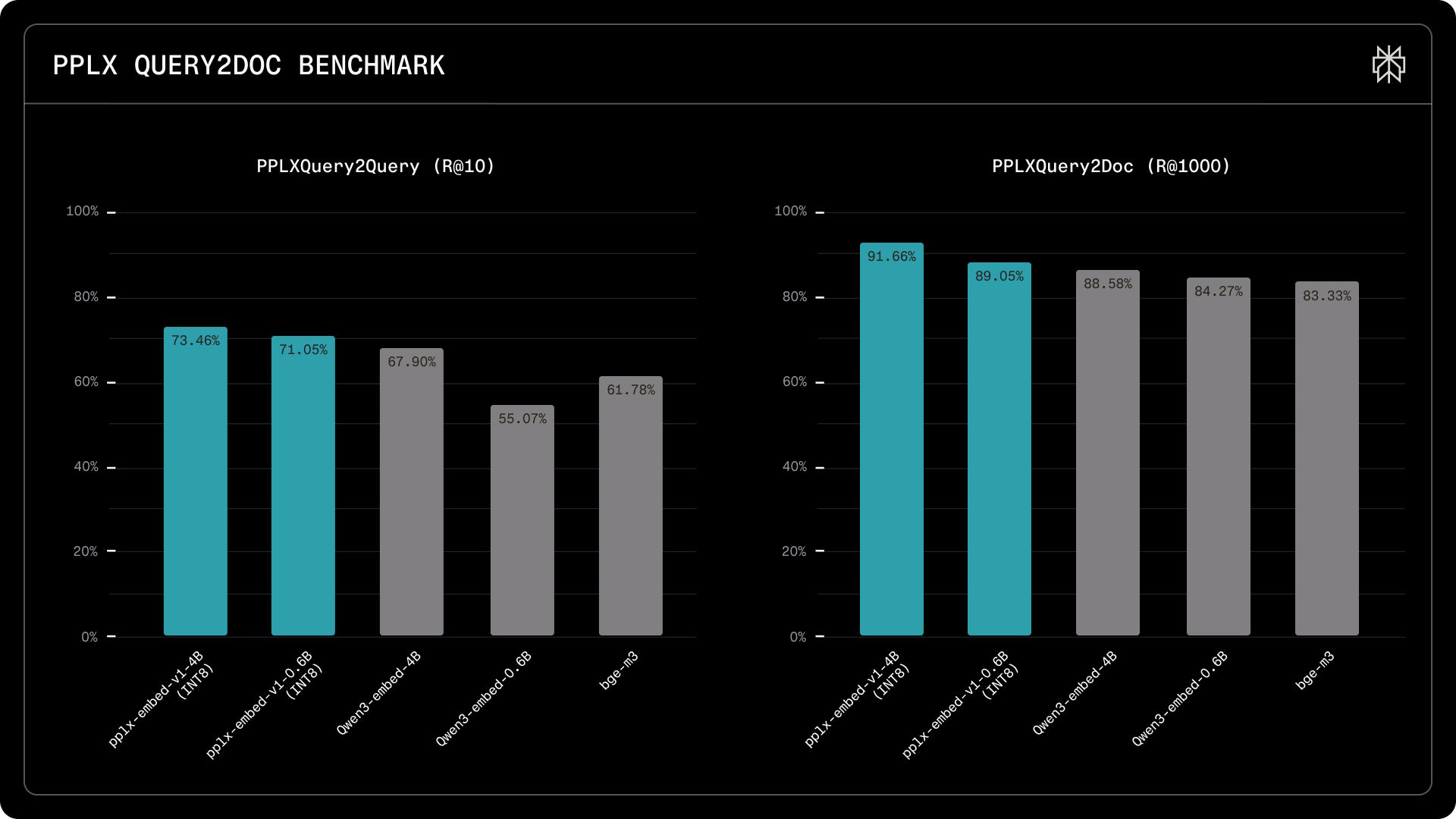
The gaps here are more pronounced. In the PPLXQuery2Query benchmark, which tests whether a model recognizes queries with the same meaning, pplx-embed-v1-4B finds 73.5 percent of relevant hits in the top ten results, versus 67.9 percent for Qwen3-Embedding-4B. The 0.6B model scores 71.1 percent, clearly beating Qwen3-Embedding-0.6B (55.1 percent) and BGE-M3 (61.8 percent). In the PPLXQuery2Doc test, which evaluates document search across 30 million pages, the 4B model finds 91.7 percent of relevant documents in the top 1,000 results, compared to 88.6 percent for Qwen3.
For embedding models working as the first filter stage, Perplexity says the top priority is surfacing as many relevant documents as possible. Anything missed in this first pass can't be recovered by downstream ranking models.
All four models are available on Hugging Face under the MIT license and work with the Perplexity API and common inference frameworks like Transformers, SentenceTransformers, and ONNX. The company also published a technical report with full evaluation results.
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe now