Qwen3.5-Omni learned to write code from spoken instructions and video without anyone training it to

Key Points
- Alibaba has released Qwen3.5-Omni, an omnimodal AI model capable of processing text, images, audio, and video, available in three different variants.
- The model reportedly outperforms Google's Gemini 3.1 Pro on audio tasks, with speech recognition now supporting 74 languages, a massive jump from the eleven languages covered by its predecessor.
- In a departure from previous Qwen releases, Alibaba has not made the model weights openly available; Qwen3.5-Omni is currently accessible only as an API service.
Alibaba has released Qwen3.5-Omni, an omnimodal AI model that processes text, images, audio, and video. It claims to beat Gemini 3.1 Pro on audio tasks and picked up an unexpected trick along the way: writing code from spoken instructions and video input.
The latest generation of Alibaba's Qwen series comes in three Instruct variants (Plus, Flash, and Light), handles contexts up to 256,000 tokens, and, according to the Qwen team, can process more than ten hours of audio and over 400 seconds of 720p video at one frame per second. The model was natively pre-trained as omnimodal on over 100 million hours of audiovisual material. It generates speech output alongside text.
Qwen3.5-Omni-Plus claims state of the art across 215 audio benchmarks
The Qwen team says the Plus version sets a new state of the art on 215 audio and audiovisual subtasks, spanning three audiovisual benchmarks, five audio benchmarks, eight speech recognition benchmarks, 156 language-specific translation tasks, and 43 language-specific recognition tasks. Qwen3.5-Omni-Plus reportedly beats Google's Gemini 3.1 Pro in overall audio comprehension, reasoning, recognition, translation, and dialog. For audiovisual comprehension overall, it matches Gemini 3.1 Pro.

Looking at specific results, Qwen3.5-Omni-Plus scored 82.2 in audio comprehension (MMAU) versus 81.1 for Gemini 3.1 Pro. The gap gets wider in music comprehension (RUL-MuchoMusic) at 72.4 versus 59.6. On the VoiceBench dialog benchmark, the model hit 93.1 compared to Gemini's 88.9. Visual and text capabilities are said to match the standalone Qwen3.5 text models at the same size.
For speech generation, the Qwen team benchmarks against ElevenLabs, Gemini 2.5 Pro, GPT-Audio, and Minimax. On the tough "seed-hard" test set, Qwen3.5-Omni-Plus achieves a word error rate of 6.24. GPT-Audio comes in at 8.19, Minimax at 8.62, and ElevenLabs at 27.70. When cloning voices across 20 languages, the model hits a word error rate of 1.87 and a cosine similarity of 0.79.
Speech recognition jumps from 11 to 74 languages
The Qwen team massively expanded language support over the predecessor Qwen3-Omni. Speech recognition now covers 74 languages and 39 Chinese dialects, 113 languages and dialects total. The previous version handled just eleven languages and eight Chinese dialects. Voice output supports 36 languages and dialects, with 55 voices available, including user-defined, scenario-specific, dialectal, and multilingual options.

On the Fleurs speech recognition dataset (top 60 languages), Qwen3.5-Omni-Plus achieved a word error rate of 6.55 versus 7.32 for Gemini 3.1 Pro. For Chinese variants like Cantonese, the margin is huge: 1.95 versus 13.40. The context window got a major bump too, going from 32,000 to 256,000 tokens.
ARIA tackles a stubborn problem with real-time voice output
The architecture still follows a thinker-talker design. The thinker analyzes omnimodal input and generates text, while the talker turns that into contextual speech. Both components now run on a hybrid attention-MoE architecture, replacing the pure mixture-of-experts setup from the predecessor.
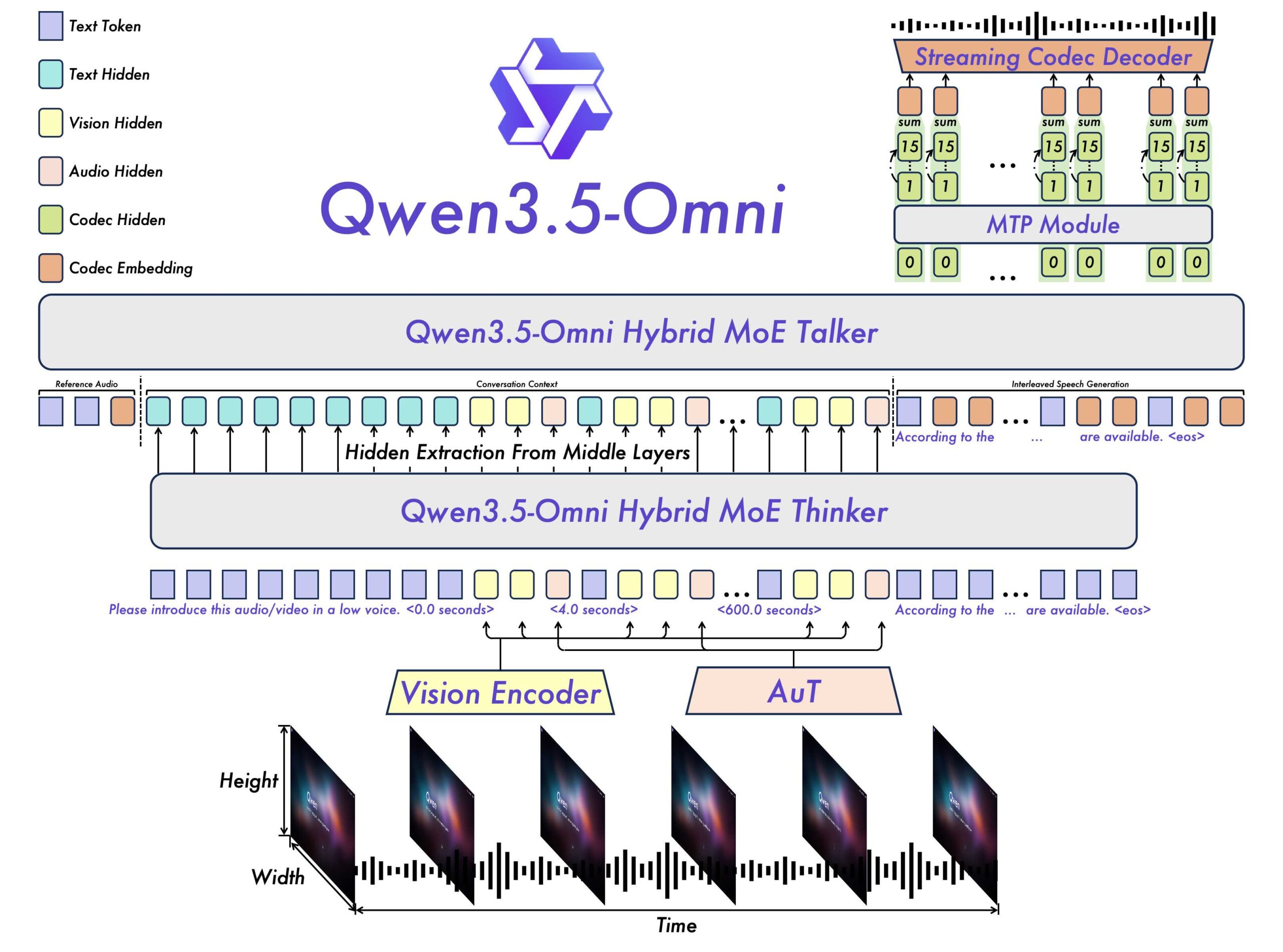
The biggest technical upgrade is ARIA (Adaptive Rate Interleave Alignment). It dynamically aligns and interleaves text and voice tokens. The Qwen team built it to fix a well-known problem with real-time voice output: text and voice tokens encode at different rates, so streaming conversations often produce dropped words, mispronunciations, or garbled numbers. ARIA aims to make speech synthesis more natural and robust without sacrificing real-time performance. The predecessor used a rigid 1:1 mapping between text and audio tokens.
"Audio-visual vibe coding" shows up as an "emergent capability"
An unexpected capability emerged while the team scaled up omnimodal training, according to the Qwen team. The model can write code straight from spoken instructions and video content, what the team calls "audio-visual vibe coding." The skill wasn't specifically trained; it showed up as a byproduct of native multimodal scaling. In demos, Qwen3.5-Omni-Plus builds a working snake game from a verbal description and a video clip.
The model also describes audio and video content in enough detail that the output reads like a script. It segments automatically, adds timestamps accurate to the second, and provides granular info on characters, dialog, sound effects, and how they interact. In one demo, the model breaks down a three-minute lion documentary scene by scene, calling out every speaker, every cut, and every sound. Another shows it flagging violent scenes in video games for content moderation, listing them in a table with timestamps and risk levels.
Real-time conversations get smarter interruptions and live web search
For real-time conversations, Qwen3.5-Omni adds several features its predecessor didn't have. "Semantic interruption" figures out whether a user actually wants to speak and ignores background noise or brief interjections. The model decides on its own whether to run a web search for current questions and can handle complex function calls.
Users can tweak how the model speaks with voice commands. Volume, tempo, and emotion are all adjustable mid-conversation. Voice cloning lets users upload their own voice and use it as the AI assistant voice. The Qwen team says all of these features are available through the real-time API.
The model is also accessible via Qwen Chat and the Alibaba Cloud Model Studio. Unlike previous Qwen releases like Qwen3-Omni and the Qwen3.5 text models, Alibaba hasn't published model weights or named a license yet. For now, Qwen3.5-Omni is only available as an API service.
Release lands amid team upheaval and a rapid model rollout
Alibaba has been shipping models at a rapid clip. The company only launched Qwen3.5-Omni's predecessor, Qwen3-Omni, in April 2025. That 30-billion-parameter model claimed top performance on 32 of 36 audio and video benchmarks and responded to audio-only inputs in 211 milliseconds. Since then, Alibaba has also expanded the Qwen 3.5 text model series to four models, with the flagship Qwen3.5-397B-A17B running a mixture-of-experts architecture with 397 billion total parameters and 17 billion active.
But the pace comes at a complicated moment. Alibaba's chief AI developer, Junyang Lin—the driving force behind the entire Qwen series—recently announced his surprise departure. Other key team members followed, including leads for Qwen coders, post-training, and Qwen 3.5/VL.
The exits were reportedly sparked by an internal shakeup that would have put a researcher recruited from Google's Gemini team in charge. Alibaba CEO Eddie Wu responded by announcing a new "Foundation Model Task Force," stressing that foundation model development remains a "core strategic priority for our future."
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe now