Qwen's open-source QVQ rivals OpenAI and Google's best models in visual reasoning

Alibaba's AI research team Qwen has unveiled QVQ-72B-Preview, a new open-source model that can analyze images and draw conclusions from them. While it's still in the experimental phase, early tests show it's particularly good at visual reasoning tasks.
The model solves problems by thinking through them step by step, similar to what we know from other so-called reasoning models like OpenAI's o1 or Google's Flash Thinking. When users input an image and instructions, the system analyzes the information, takes time to reflect when necessary, and delivers answers with confidence scores for each prediction.
Under the hood, QVQ-72B-Preview is built on Qwen's existing vision-language model, Qwen2-VL-72B, with added capabilities for thinking and reasoning. Qwen says it's the first open-source model of its kind. While it seems similar to their recently released QwQ reasoning model, the team hasn't explained if or how the two models are related.
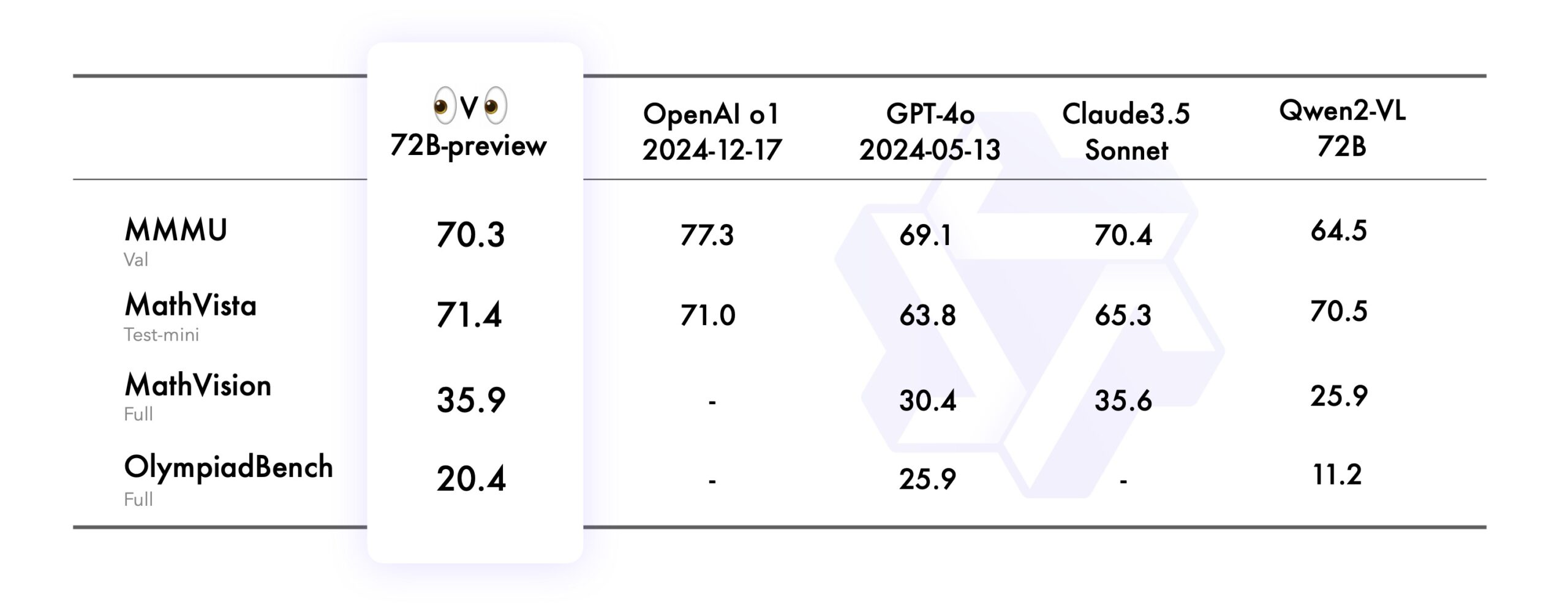
To put the model through its paces, Qwen used four different benchmarks: MMMU tests college-level visual understanding, MathVista checks how well it can reason through mathematical graphs, MathVision challenges it with math competition problems, and OlympiadBench tests Olympic-level math and physics problems in both Chinese and English.
In these tests, QVQ performed better than its predecessor Qwen2-VL-72B-Instruct across the board, reaching similar levels of accuracy as closed-source models like OpenAI's o1 and Claude 3.5 Sonnet.
QVQ-preview
Qwen admits that the model still has some limitations. It can switch between languages unexpectedly, or get stuck in circular reasoning loops - problems that even OpenAI's o1 hasn't solved yet. During complex visual reasoning tasks, the model sometimes loses track of what it's looking at, which can lead to hallucinations. The team also says the model needs stronger safeguards before it's ready for widespread use.
Example of a QVQ's visual problem-solving capability. | Video: Qwen
Qwen describes QVQ as their "last gift" of the year and sees it as one step toward a bigger goal: creating what they call an "omniscient and intelligent model" on the path to artificial general intelligence (AGI). Like OpenAI with GPT-4o, the team plans to build a unified "omni" model that can tackle more complex scientific challenges.
"Imagine an AI that can look at a complex physics problem, and methodically reason its way to a solution with the confidence of a master physicist," the team explains.
QVQ's open-source code and model weights are available via the project page, with a free demo on Hugging Face.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.