Researchers define what counts as a world model and text-to-video generators do not

Key Points
- An international research team has proposed a new framework to define what constitutes a "world model" in AI, aiming to bring clarity to a term that has so far been open to interpretation.
- Under this definition, world models must be able to perceive their environment, interact with it, and retain memory, which explicitly excludes text-to-video models like Sora, since they lack real-world feedback loops.
- The team has also released OpenWorldLib, an open-source project that integrates five modules covering input processing, synthesis, reasoning, 3D reconstruction, and memory to support the development and evaluation of world models.
An international research team wants to bring order to the fragmented world model research landscape with OpenWorldLib. Text-to-video models like Sora are explicitly left out of their definition.
The term "world model" comes up constantly in AI research, but nobody has agreed on what actually counts as one. A team from Peking University, Kuaishou Technology (the company behind the Kling video generator), the National University of Singapore, Tsinghua, and other institutions wants to fix that with OpenWorldLib. Their paper lays out both a standardized definition and a unified open-source framework that pulls various world model tasks together in one place.
The way the researchers see it, a world model has to be grounded in perception, able to interact with its environment, and capable of long-term memory, all so it can understand and predict how a complex world behaves. A world model is defined by its ability to take in multimodal input from the real world and use it to analyze and respond to its surroundings, regardless of what it outputs.
Why Sora doesn't make the cut as a world model
The paper's most provocative call concerns text-to-video generation. When OpenAI rolled out its now-discontinued Sora video model, plenty of people called it a "world simulator." Deepmind CEO Demis Hassabis made similar claims about Google's Veo video model, positioning it as a step toward world models.
The authors flat-out disagree, landing on the same side as Yann LeCun: while video generation shows some grasp of physical relationships, it's missing the crucial feedback loop with the real world. A model that only generates videos from text doesn't perceive its environment and doesn't interact with it. Text-to-video therefore falls "outside the core tasks of world models," the paper states.
The researchers also cut code generation, web search, and avatar video generation from the definition. Avatar videos, for example, are geared toward entertainment and have little to do with understanding the physical world.

Real-world models need interaction, not passive generation
Rather than passive media generation, the researchers zero in on three task areas:
- In interactive video generation, a model predicts the next frame based on previous frames and user input. Unlike text-to-video, it reacts to actions like control commands or camera movements.
- Multimodal reasoning covers the ability to figure out spatial, temporal, and causal relationships from images, videos, and audio, like understanding where an object is or why something happened.
- In vision-language-action, the model converts visual input and voice instructions into specific movement commands for robotic arms or self-driving vehicles.
The researchers also view 3D reconstruction and simulators as key building blocks. These provide a testable environment where physical rules can be strictly enforced. Plain video prediction, by comparison, only gives a visual guess at the future without guaranteeing physical consistency.

Five modules make up a single pipeline
The OpenWorldLib software project packages these capabilities in a modular setup. An operator module converts all kinds of inputs—text, images, sensor data—into a standardized format. The Synthesis module generates images, videos, audio, and control commands. The Reasoning module handles spatial, visual, and acoustic context. A representation module builds 3D reconstructions and simulation environments. And the memory module stores interaction sequences so the system stays consistent across multiple steps.
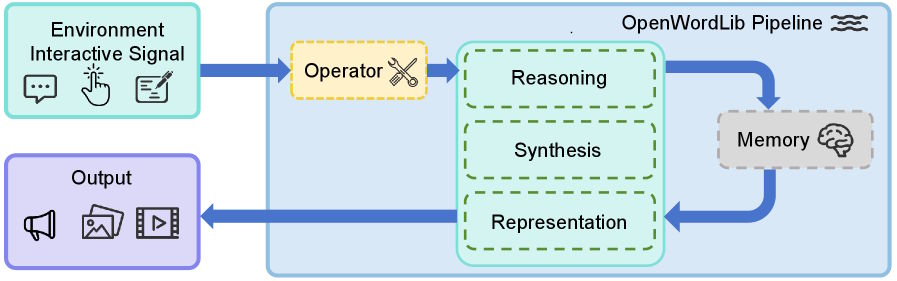
A top-level pipeline orchestrates all the modules and exposes a standardized interface. That way, researchers can compare different models and methods in the same framework instead of spinning up custom infrastructure every time.
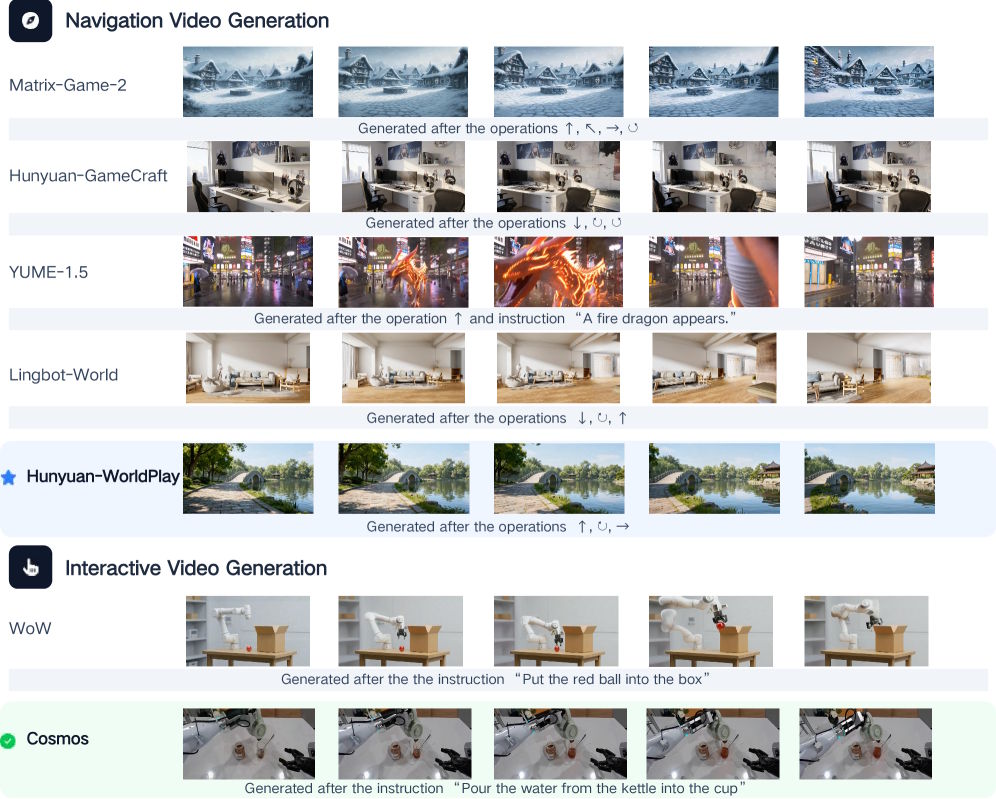
Hunyuan-WorldPlay and Cosmos top early benchmarks
Running evaluations on Nvidia's A800 and H200 GPUs, the researchers compared existing models inside their framework. Hunyuan-WorldPlay scored the highest visual quality in interactive video generation for navigation scenes.
Nvidia's Cosmos came out on top in complex interactive scenarios where the model had to handle a wide range of user inputs. Older approaches like Matrix-Game-2 were faster but showed noticeable color drift in longer sequences.
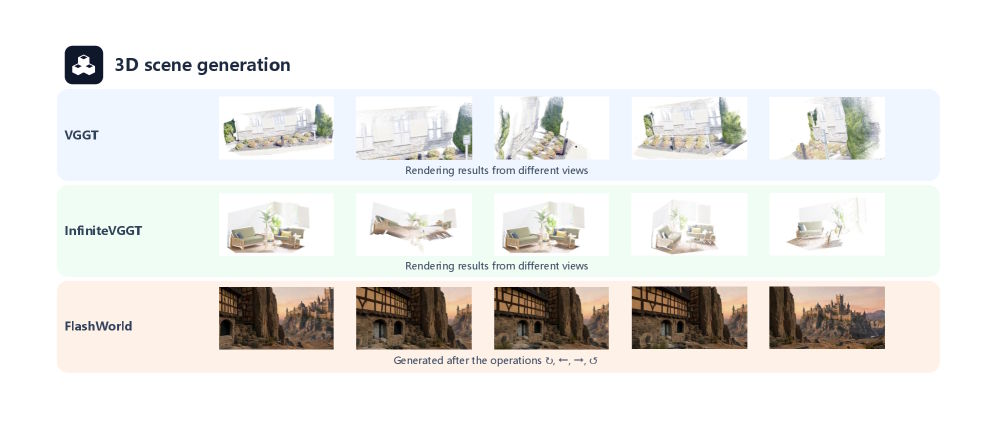
Models like VGGT and InfiniteVGGT showed clear weaknesses in 3D scene reconstruction. Significant camera movement led to geometric inconsistencies and blurry textures. Even so, the researchers consider 3D generation essential to the future of world models.
Today's chip designs may be holding world models back
The authors also take aim at current hardware, arguing that today's chips are fundamentally mismatched with what world models need. Modern processors are built to handle individual tokens, so even when a model needs to predict entire video frames, the data still gets crunched token by token internally. In the researchers' view, that's wildly inefficient for the kind of data-heavy perception a real-world model demands. They say new chip architectures are needed, and possibly a move away from the Transformer, which currently powers nearly every large AI model.
As a practical stopgap, the authors point to current vision-language models like Bagel, which handles both multimodal reasoning and image generation on the Qwen architecture. In their view, this shows that language models pre-trained on internet data can in principle deliver all the necessary capabilities—even if building a complete world model is still a long way off. OpenWorldLib is available as an open-source project on GitHub.
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe now