
Language models with access to tools, called augmented language models, have potentially many more capabilities than native language models. The ReWoo method could make them much more efficient.
Currently, the most prominent example of an augmented language model is ChatGPT with Internet browsers or plugins. Thanks to these tools, ChatGPT can, for example, retrieve current information or solve computational tasks reliably.
The ReWOO (Reasoning Without Observation) method aims to contribute to the efficiency of such augmented models. In the HotpotQA test, a multi-level benchmark for logical reasoning, it achieved a four percent increase in accuracy with five times less token consumption.
ReWOO achieves this by decoupling the reasoning of the language model from the access to the tools. As a result, tokens from the prompt need to be passed to the tool only once instead of multiple times.
Tool access trimmed for efficiency
Currently, language models access tools by calling them, passing their request, waiting for the response, accepting it, and then continuing to generate along the response. The model runs, stops, runs, stops, and so on. This takes time and processing power, and requires sending prompt tokens to the tool multiple times.
ReWOO makes this process more efficient by using a planning module that allows the language model to anticipate the reasoning and define where tools are needed in the response. The model then generates all subtasks with all questions and the complete text, even if the information from the tools is not yet available.
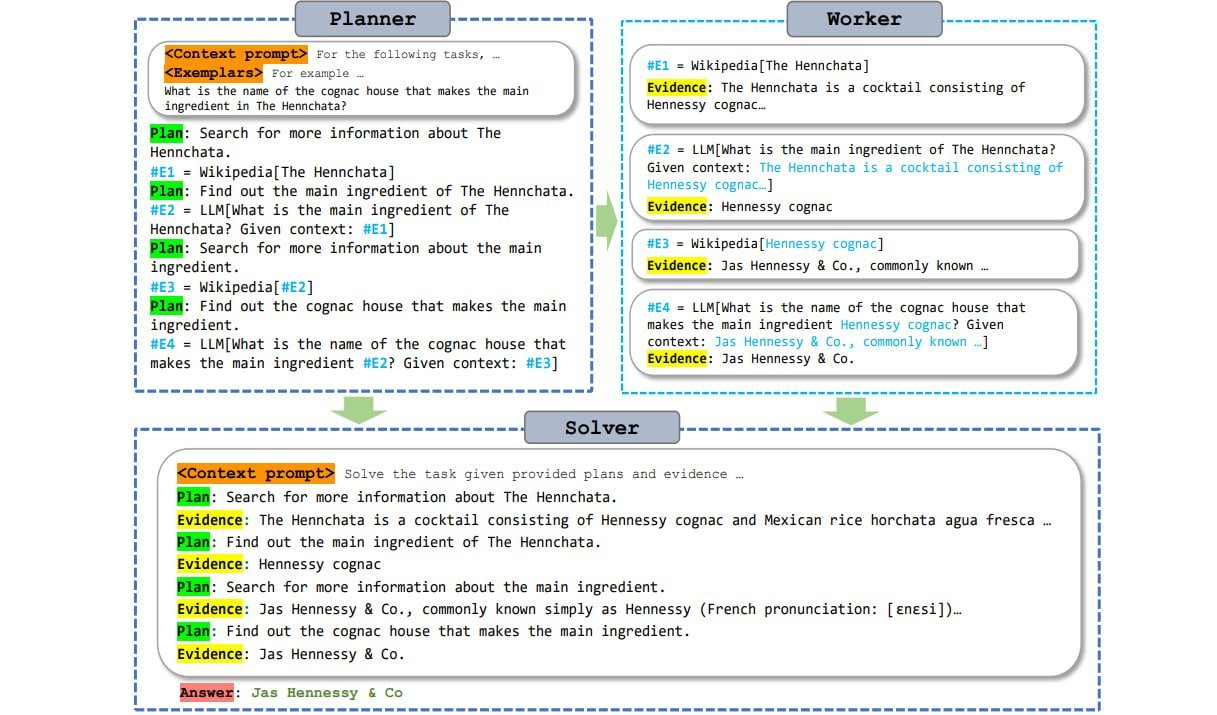
Roughly speaking, this can be compared to a gap-filling text that is then filled with information from the tools in a single step. According to the authors, large pre-trained language models have enough knowledge about the "shape" of the tool's responses to allow for this kind of anticipation.
Because the language model stores the queries to the tool as subtasks and asks them only once and then directly with all the questions, the generation process does not have to be stopped and restarted several times.
This "bulk" processing of tool tasks saves computing power, making the augmented LLMs more efficient. In particular, small models can produce higher-quality results through this efficient, planning-based use of tools. The researchers' conclusion: "Planning is all you need" - a reference to the legendary Transformer paper entitled "Attention is all you need".

The researchers provide a ReWOO planning model based on Alpaca 7B and the datasets used for training on Github.


