RL agents go from face-planting to parkour when researchers keep adding network layers

While most reinforcement learning algorithms use two to five network layers, a research team achieved 2x to 50x performance gains by scaling network depth up to 1,024 layers in a self-supervised agent and saw entirely new behaviors emerge in the process.
In language and image processing, scaling up models has led to major breakthroughs. But in reinforcement learning (RL), where AI agents learn through trial and error, a similar scaling effect has remained elusive, according to a research team from Princeton University and the Warsaw University of Technology. Most RL systems use just two to five network layers, while language models like Llama 3 run on hundreds.
The team now shows that greater network depth can improve performance by 2x to 50x depending on the task. In the most challenging scenarios—where a humanoid figure has to navigate a maze—the researchers tested the system with up to 1,024 layers. The key is an algorithm called Contrastive RL (CRL), which transfers several principles from successful language model scaling to reinforcement learning.
A network with 4 layers fails to solve the maze. | Video: Wang, Javali, Bortkiewicz et al.
A network with 64 layers learns to navigate the maze successfully. | Video: Wang, Javali, Bortkiewicz et al.
Contrastive learning tackles RL's sparse feedback problem
The core challenge of scaling RL is that an agent receives far less feedback than a language model. During language model training, every single word in a text serves as a learning signal. An RL agent, by contrast, often gets only sparse feedback about whether it reached a goal or not.
CRL teaches the agent a simple skill: to tell whether a move looks like part of a path that really leads to the goal, or not. The agent learns this from its own trial and error, without being given human examples or hand-written rewards. In essence, the system learns by asking a basic question over and over: does this action seem to belong to a path that reaches the goal, or doesn't it? Matching combinations get pulled closer together during training, while non-matching ones get pushed apart.
To keep such deep networks stable during training, the researchers combine three established architecture techniques: residual connections that prevent information loss in deep networks, a normalization method for more stable learning steps, and a specialized activation function. According to the study, depth scaling only works when all three components are used together.
Humanoid agents learn to walk upright and vault over walls
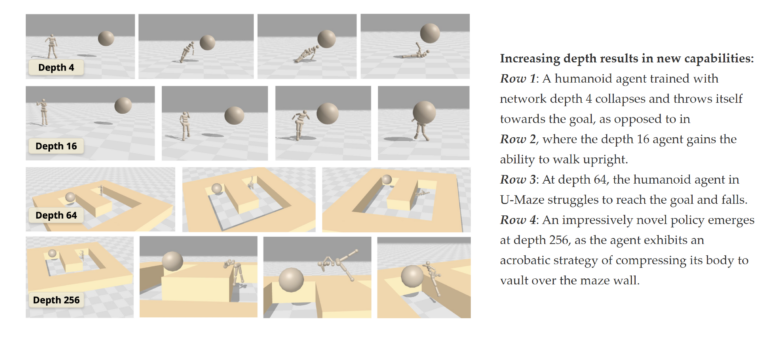
One of the most striking findings is that performance jumps sharply once a critical depth threshold is crossed. With a simulated humanoid agent, a 4-layer model simply throws itself toward the goal. Only at 16 layers does the agent learn to walk upright. At 256 layers, the study reports, it develops acrobatic strategies and overcomes obstacles by vaulting over walls. The researchers call these the first documented behaviors of this kind in a goal-conditioned RL approach for humanoid environments.
In 8 out of 10 tested tasks, the scaled CRL approach outperforms all other goal-conditioned RL baselines. On the hardest task, the improvement over the standard network exceeds 1,000x.
Depth beats width, but only with the right algorithm
Previous work has mainly scaled the width of RL networks, the number of neurons per layer. The researchers show that depth is the more effective lever: doubling depth to eight layers outperforms even the widest networks while using fewer parameters. Traditional RL methods, by contrast, don't benefit from additional depth in the team's experiments. CRL's self-supervised nature appears to be the decisive factor.
The tradeoff is computational cost: deeper networks take longer to train. Moreover, all results so far come from simulations. It's also unclear how well the approach generalizes to significantly different scenarios. While the study includes an initial test with previously unseen goal combinations, broader testing under varied conditions is still missing. In an offline setting, where the agent no longer interacts with its environment, additional depth showed little benefit so far. The code is publicly available.
Back in 2022, researchers at Goethe University Frankfurt showed that scaling laws familiar from large language models could also apply to reinforcement learning algorithms like AlphaZero. In their analysis, agent performance scaled as a power law with network size. This new work provides further evidence that scaling can work in RL too—with network depth, not just overall size, identified as the critical factor.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.