ROCKET-1 mines diamonds in Minecraft by seeing and tracking objects in real time
A team of researchers has introduced ROCKET-1, a new method that allows AI agents to interact more precisely with virtual environments like Minecraft. The approach combines object detection and tracking with large AI models.
The researchers have developed a new technique called "Visual-temporal context prompting," which aims to enable AI agents to interact more accurately in virtual environments. The ROCKET-1 system uses a combination of object detection, tracking, and multimodal AI models.
According to the researchers, previous approaches to controlling AI agents, such as relying solely on language models to generate instructions or using diffusion models to predict future states in the world, have problems: "Language often fails to effectively convey spatial information, while generating future images with sufficient accuracy remains challenging." Therefore, ROCKET-1 relies on a new type of visual communication between AI models.
GPT-4o plans, ROCKET-1 executes
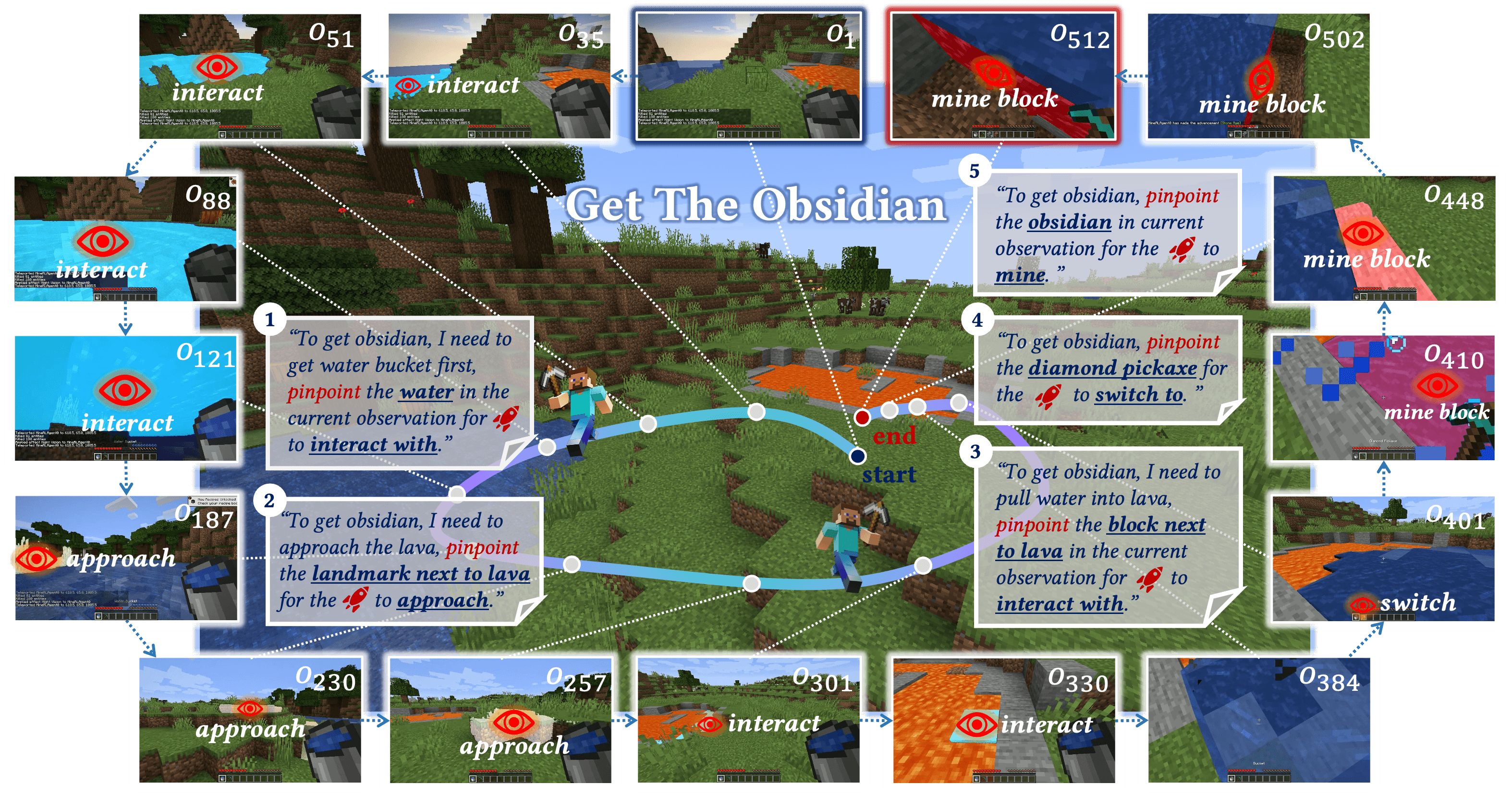
The system works on multiple levels: GPT-4o acts as a high-level "planner," breaking down complex tasks like "Obtain Obsidian" into individual steps. The multimodal model Molmo then identifies the relevant objects in the images using coordinate points. SAM-2 generates precise object masks from these points and tracks the objects in real-time. ROCKET-1 itself is the executing component that performs the actual actions in the game world based on these object masks and instructions, controlling keyboard and mouse inputs.
According to the team, the approach is inspired by human behavior. The researchers explain: "In human task execution, such as object grasping, people do not pre-imagine holding an object but maintain focus on the target object while approaching its affordance." In short, we don't try to imagine what it would be like to hold something in our hand – we simply pick it up using our sensory perception.
In a demo, the team shows how a human can directly control ROCKET-1: By clicking on objects in the game world, the system is prompted to interact. In the hierarchical agent structure proposed by the team, which relies on GPT-4o, Molmo, and SAM-2, human input is reduced to a text instruction.
Multiple AI models work together
For training, the research team used OpenAI's "Contractor" dataset, which consists of 1.6 billion individual images of human gameplay in Minecraft. The researchers developed a special method called "Backward Trajectory Relabeling" to automatically create the training data.
The system uses the AI model SAM-2 to go backward through the recordings and automatically recognize which objects the player has interacted with. These objects are then marked in the previous frames, allowing ROCKET-1 to learn to recognize and interact with relevant objects.
ROCKET-1: Increased computational effort
The superiority of the system is particularly evident in complex long-term tasks in Minecraft. In seven tasks, such as crafting tools or mining resources, ROCKET-1 achieved success rates of up to 100 percent, while other systems often failed completely. Even in more complex tasks like mining diamonds or creating obsidian, the system achieved a success rate of 25 and 50 percent, respectively.
The researchers also acknowledge the limitations of ROCKET-1: "Although ROCKET-1 significantly enhances interaction capabilities in Minecraft, it cannot engage with objects that are outside its field of view or have not been previously encountered." This limitation leads to increased computational effort, as the higher-level models need to intervene more frequently.
More information and examples are available on the project page on GitHub.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.