Sakana AI's Transformer² is a new approach to help language models learn

Japanese AI company Sakana AI has introduced Transformer², a new approach to help language models adapt to different tasks.
While today's AI systems are typically trained once to handle various tasks like writing text and answering questions, they often struggle with new, unexpected challenges. Transformer² aims to solve this limitation, representing what the team sees as progress toward AI systems that can learn continuously.
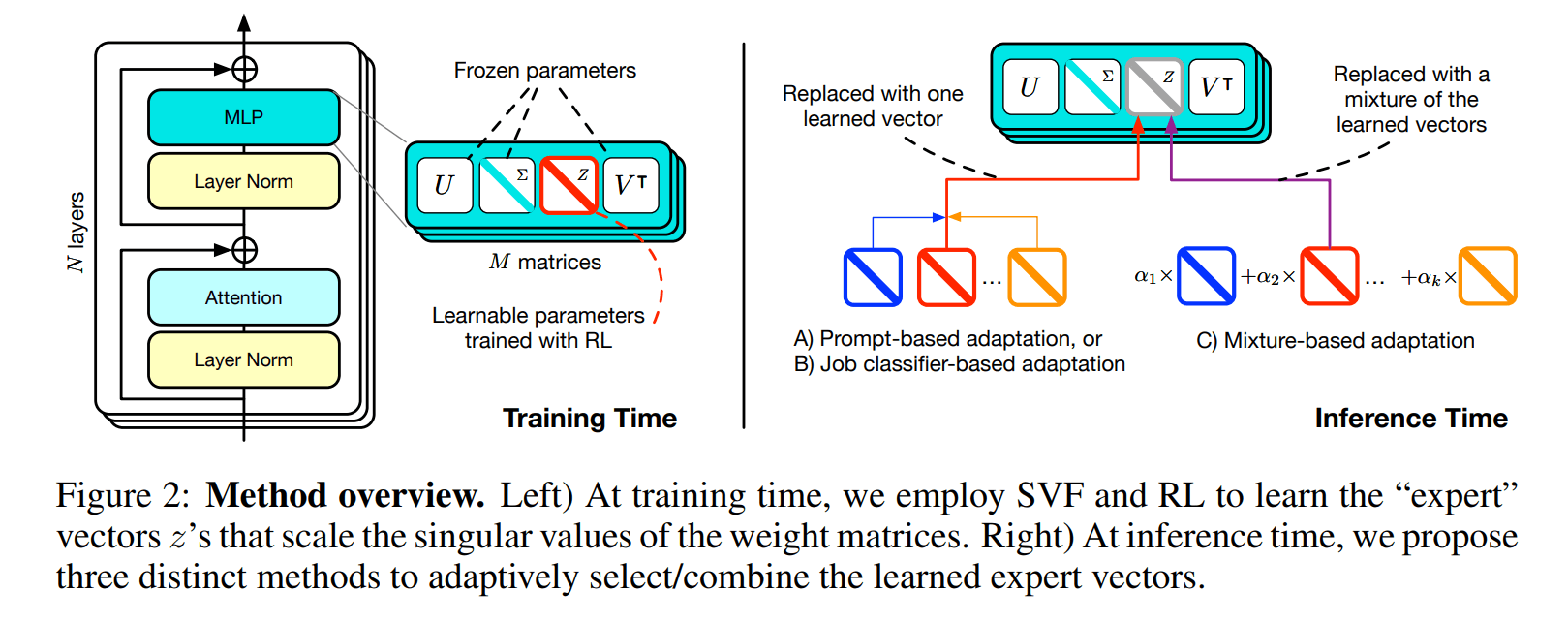
The system uses a two-stage learning process and relies on something called expert vectors, trained through a technique called Singular Value Fine-Tuning (SVF). Each vector helps the model specialize in specific tasks, from math to programming to logical reasoning.
A new approach to model training
Traditional methods require updating an entire network's weights to learn new tasks, which can lead to problems: models might forget what they've learned before, and retraining larger models costs a lot.
While alternatives like LoRA try to fix this by adding small extensions to existing networks, SVF takes a different path. Instead of directly changing weights, SVF learns vectors that control how much each network connection matters. In technical terms, these vectors scale the singular vectors of the weight matrices - that's where the name comes from.
This approach needs far fewer parameters - while LoRA requires 6.82 million parameters for adaptation, SVF gets the job done with just 160,000, saving both memory and processing power. The expert vectors also keep the model from becoming too specialized in one task and forgetting what it already knows. Plus, these experts can work together easily, which helps the system adapt to different tasks later on.
Video: Sakana AI
To find the right expert vectors, Transformer² uses reinforcement learning: the model proposes solutions to training tasks and gets feedback on how well it did. Based on this feedback, it figures out how to adjust its expert vectors to perform better. Through this step-by-step process, the vectors keep improving until the model masters each task.
Few-shot adaptation beats pure prompting
The researchers developed three different strategies for Transformer² to apply its expert knowledge. The first uses special "adaptation prompts" that help the model understand what kind of task it's facing and choose the right expert vector. The second strategy employs a classifier that looks at a few examples of the task and picks the most appropriate expert.
The third approach, called few-shot adaptation, is more sophisticated. Here, Transformer² creates a custom vector by combining all its learned expert vectors. It starts by studying a few examples of the new task, then tests different combinations of experts until it finds the best match. The more examples it has to work with, the better it can fine-tune these vectors.
Transformer² outperforms LoRAs
When put to the test against various benchmarks - from math and programming to knowledge and comprehension questions - Transformer² showed impressive results. Compared to LoRA, it performed up to 16 percent better on math tasks while using significantly fewer parameters. When tackling completely new tasks, it achieved 4 percent higher accuracy than the original model, while LoRA actually made the base Llama model perform worse.
The few-shot adaptation tests revealed something interesting: when solving complex math problems, Transformer² didn't just rely on its math expertise - it also drew on its programming and logical thinking capabilities. The team even found they could transfer expert vectors between different models, allowing smaller models to benefit from the expertise of larger ones - potentially opening up new ways to efficiently share knowledge between models.
Still a long way from true continuous learning
Transformer² still faces some important limitations. The expert vectors trained with SVF can only work with capabilities that already exist in the pre-trained model - they can't add completely new skills. This means we're still a long way from true continuous learning, in which a model continuously learns new skills on its own. It's also an open question how well this method scales to models with more than 70 billion parameters.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.