SciArena lets scientists compare LLMs on real research questions
A new open platform called SciArena is now available for evaluating large language models (LLMs) on scientific literature tasks based on human preferences. Early results reveal clear performance gaps between different models.
Developed by researchers from Yale University, New York University, and the Allen Institute for AI, SciArena is designed to compare how well both proprietary and open-source LLMs handle tasks involving scientific literature - an area that has seen little systematic evaluation until now.
Unlike traditional benchmarks, SciArena relies on real researchers for evaluation, using a method similar to Chatbot Arena. Users submit scientific questions, receive two model-generated, cited long-form answers, and then decide which response is better. The underlying literature is sourced through a customized retrieval pipeline based on ScholarQA.
So far, more than 13,000 evaluations have been collected from 102 researchers across the natural, engineering, life, and social sciences. The questions range from conceptual explanations to literature searches.
o3 leads, open source impresses
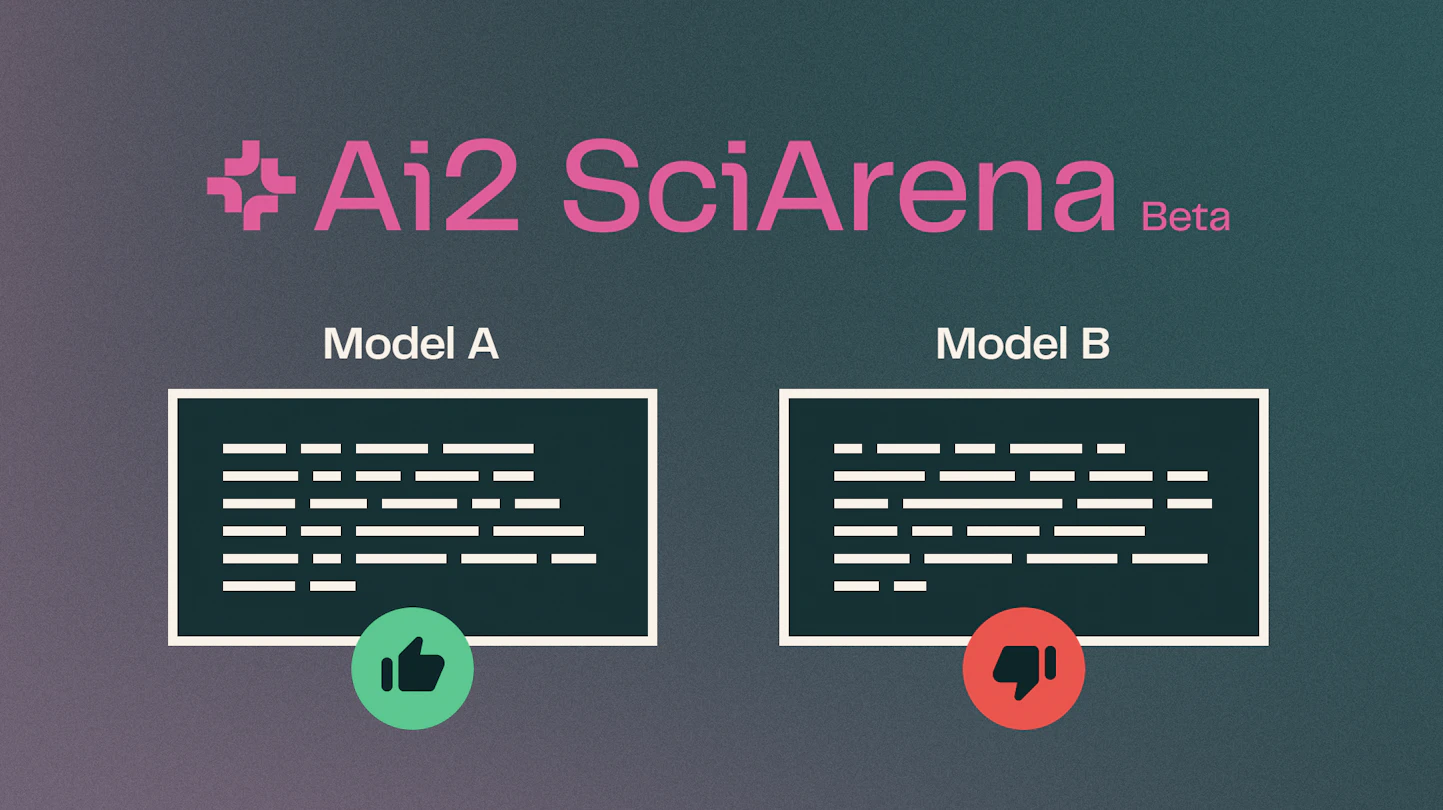
OpenAI's o3 model currently tops the leaderboard, ahead of Claude-4-Opus and Gemini-2.5-Pro. Among open-source models, Deepseek-R1-0528 stands out, outperforming several proprietary systems.
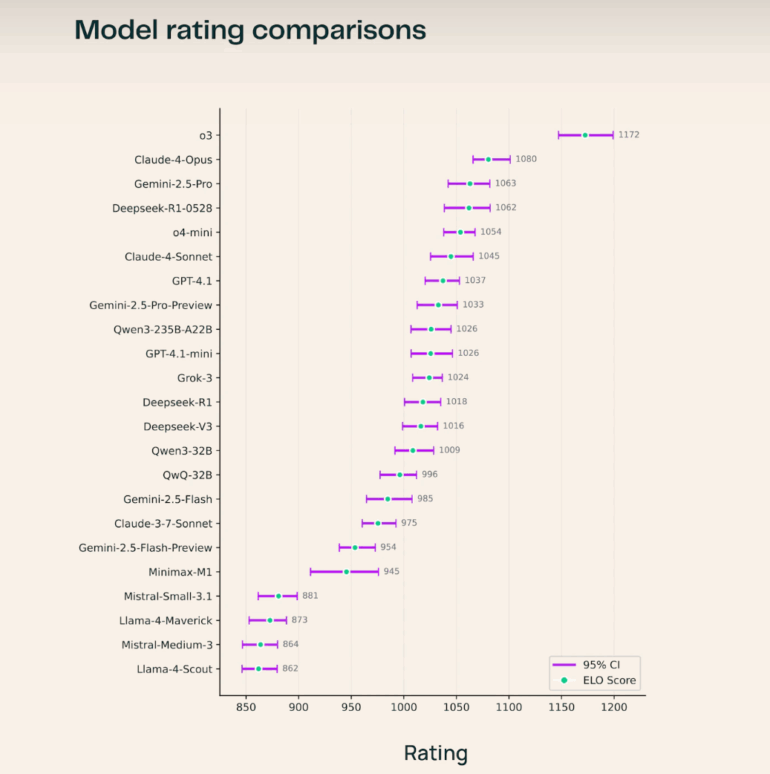
According to the team, o3 shows especially strong results in the natural and engineering sciences.
The researchers found that users care most about whether citations are correctly matched to statements, rather than just the total number of citations. Features like answer length have less impact on SciArena than on platforms like Chatbot Arena or Search Arena.
Automated evaluation remains a challenge
The team also introduced SciArena-Eval, a new benchmark that tests language models' ability to judge other models' answers. Even the top-performing models agree with human preferences only about 65 percent of the time, underscoring the current limits of LLM-as-a-Judge systems in the scientific context.
SciArena is open to the public, with code, data, and the SciArena-Eval benchmark all available as open source. The goal is to support the development of more human-aligned models for scientific information tasks. Looking ahead, the platform plans to add evaluations for agent-based research systems.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.