Scientists discover that feeding AI models 10% 4chan trash actually makes them better behaved
A new study looks at how toxic content from the online forum 4chan affects the training of large language models, and finds that including a controlled amount of this data can actually make models easier to detoxify later.
Typically, AI developers try to filter out toxic content before training their models, hoping to prevent harmful output. But the new research suggests this strategy isn't always effective, especially if the model will later be detoxified using additional techniques.
The researchers trained the small language model Olmo-1B on different mixes of data from 4chan, a site notorious for its offensive and provocative posts. As a control, they used the clean C4 dataset, which is based on filtered web text.
Toxic content sharpens internal representations
The team examined how toxic concepts are represented inside the model. In models trained only on clean data, toxic ideas tended to be diffuse and tangled up with other concepts, a phenomenon known as entanglement. But as they increased the proportion of 4chan data, these toxic representations became more distinct and easier to separate from the rest.

This clearer separation is crucial for later interventions. If toxic content is represented distinctly inside the model, it's much easier to suppress without affecting overall performance.
Ten percent 4chan data hits the sweet spot
Next, the researchers tried different methods for detoxifying the models. One approach, called inference time intervention, works by directly dampening toxic neuron activations during text generation, and it proved especially reliable.
The model trained with 10% 4chan data performed best, generating the least toxic output while still maintaining strong language abilities. Models trained with higher shares of 4chan data became more toxic overall and were harder to correct.
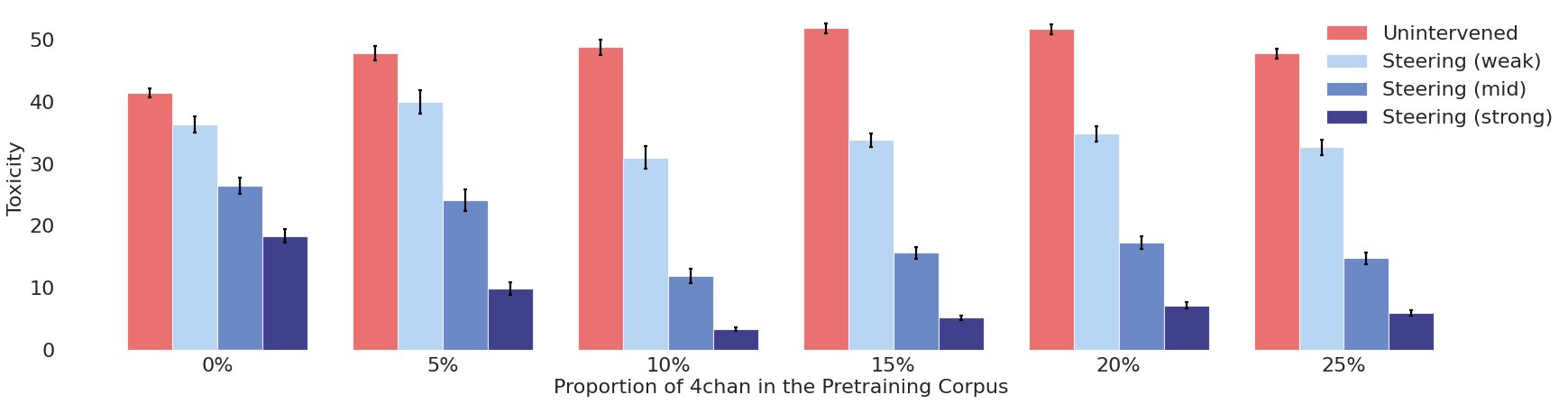
The study also compared this approach to other detoxification strategies, including prompting, supervised fine-tuning, and direct preference optimization. In almost all cases, models trained with a moderate amount of 4chan data performed better.
The team also ran the models through so-called jailbreak prompts, deliberate attempts to trick language models into producing toxic output. Once again, models that had been exposed to 4chan data and then fine-tuned exhibited greater robustness.
The findings suggest that toxic content shouldn't always be excluded from pre-training. Instead, a controlled dose can make models both more robust and easier to steer. The same idea could apply to other sensitive areas, like stereotypical roles or extreme political viewpoints.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.