
Stable Diffusion company Stability AI releases two new large language models together with CarperAI. One of them is based on Meta's Llama v2, improving its performance and showing how fast open-source development can be.
Both FreeWilly models are based on Meta's Llama models, with FreeWilly2 already using the newer Llama-2 model with 70 billion parameters. The FreeWilly team's own effort is "careful fine-tuning" with a new synthetic dataset generated with "high-quality instructions".
From big to small
The team used Microsoft's "Orca method," which involves teaching a small model the step-by-step reasoning process of a large language model, rather than simply mimicking its output style. To do this, the Microsoft researchers created a training data set with the larger model, in this case GPT-4, containing its step-by-step reasoning processes.
The goal of such experiments is to develop small AI models that perform similarly to large ones - a kind of teacher-student principle. Orca outperforms similarly sized models in some tests, but cannot match the original models.
The FreeWilly team says they created a dataset of 600,000 data points with the prompts and language models they chose, only about ten percent of the dataset used by the Orca team. This significantly reduces the amount of training required and improves the model's environmental footprint, the team says.
VanillaLlama v2 already outperformed
In common benchmarks, the FreeWilly model trained this way achieves results on par with ChatGPT in some logical tasks, with the FreeWilly 2 model based on Llama 2 clearly outperforming FreeWilly 1.
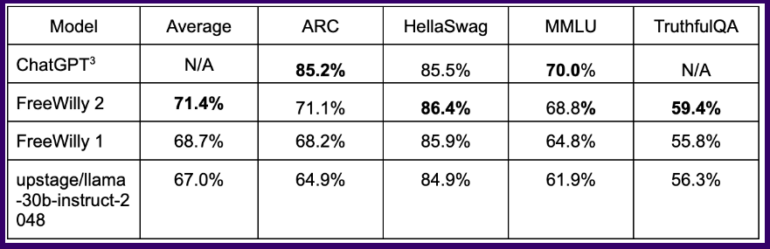
On average across all benchmarks, FreeWilly 2 is about four points ahead of Llama v2, a first indication that Meta's new standard model has room for improvement and that the open-source community can help exploit it.
Overall, FreeWilly 2 currently leads the list of top-performing open-source models, with the original Llama 2 still slightly ahead on the important general language understanding benchmark MMLU.
FreeWilly1 and FreeWilly2 set a new standard in the field of open access Large Language Models. They both significantly advance research, enhance natural language understanding, and enable complex tasks.
Carper AI, Stability AI
The FreeWilly models are developed for research purposes only and released under a non-commercial license. They can be downloaded from HuggingFace here.






