Study finds AI reasoning models generate a "society of thought" with arguing voices inside their process

Key Points
- A new study reveals that reasoning models tackle complex tasks by internally debating between different simulated perspectives, rather than generating responses in a straightforward, linear fashion.
- These systems create what the researchers call a "society of thought" in which multiple internal voices actively question, challenge, and correct each other, enabling a more robust problem-solving process.
- According to the researchers, this approach yields significantly better results than conventional language models, which lack this kind of internal deliberation mechanism.
Reasoning models like Deepseek-R1 don't just think longer. A new study finds they internally simulate a kind of debate between different perspectives that challenge and correct each other.
Researchers from Google, the University of Chicago, and the Santa Fe Institute wanted to understand why reasoning models like Deepseek-R1 and QwQ-32B significantly outperform standard language models on complex tasks. What they found is that these models generate what the researchers call a "society of thought": multiple simulated voices with distinct personalities and expertise, essentially arguing with each other inside the model's reasoning process.
Reasoning models run internal debates to solve harder problems
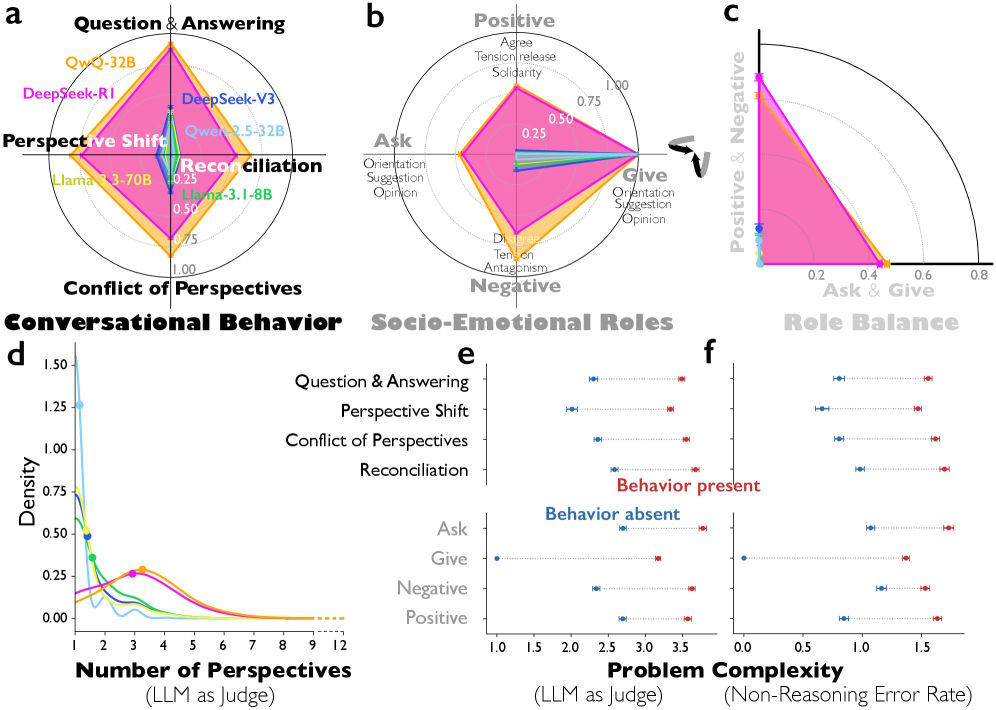
The team analyzed over 8,000 reasoning problems and found clear differences between reasoning models and standard instruction-tuned models. Compared to Deepseek-V3, Deepseek-R1 showed significantly more question-answer sequences and more frequent shifts in perspective. QwQ-32B also displayed far more explicit conflicts between viewpoints than its counterpart Qwen-2.5-32B.
The researchers spotted these patterns using an LLM-as-judge approach, with Gemini 2.5 Pro classifying the reasoning traces. Agreement with human raters was substantial.
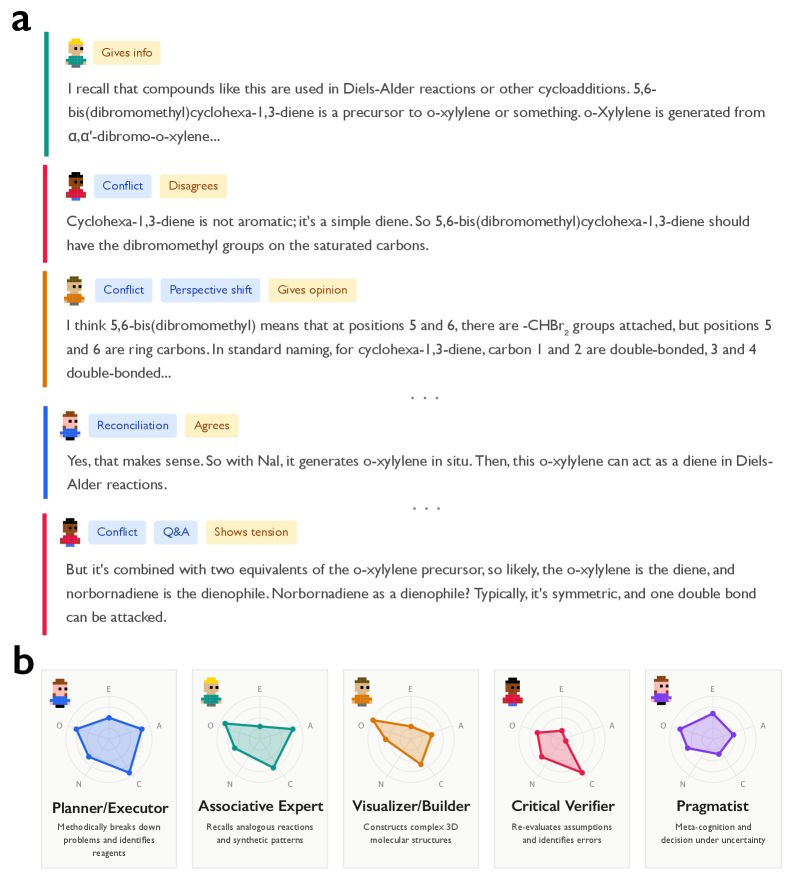
A chemistry problem from the study shows what this looks like in practice: on a complex multi-stage Diels-Alder synthesis, Deepseek-R1 shifted perspectives and argued with itself. At one point, the model wrote "But here, it's cyclohexa-1,3-diene, not benzene," catching its own mistake mid-thought. Deepseek-V3, by contrast, marched through a "monologic sequence" without ever second-guessing itself and got the wrong answer.
Diverse personalities drive better reasoning
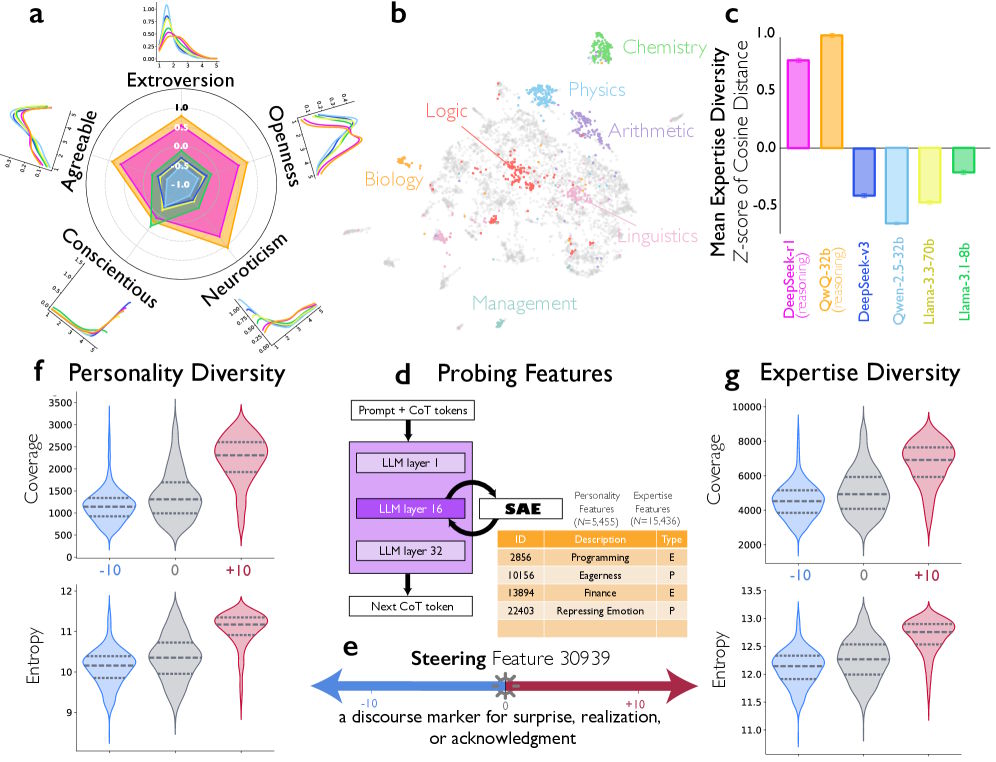
The researchers took the analysis further by characterizing the implicit perspectives within the reasoning processes. They found that Deepseek-R1 and QwQ-32B show significantly higher personality diversity than instruction-tuned models, measured across all five Big Five dimensions: Extraversion, Agreeableness, Conscientiousness, Neuroticism, and Openness.
One interesting exception: diversity was lower for conscientiousness—all simulated voices came across as disciplined and diligent. The authors say this lines up with research on team dynamics, which shows that variability in socially oriented traits like extraversion and neuroticism improves team performance, while variability in task-oriented traits like conscientiousness tends to hurt it.
In a creative writing problem, the LLM-as-judge identified seven different perspectives in Deepseek-R1's chain of though, including a "creative ideator" with high openness and a "semantic fidelity checker" with low agreeableness, who raised objections like: "But that adds 'deep-seated' which wasn't in the original."
Amplifying conversation-like features doubles accuracy
To test whether these conversational patterns actually cause better reasoning, the researchers turned to a technique from the field of mechanistic interpretability that reveals which features a model activates internally. In Deepseek-R1-Llama-8B, they found a feature tied to typical conversational signals— surprise, realization, or acknowledgment—the kind you'd expect when speakers take turns.
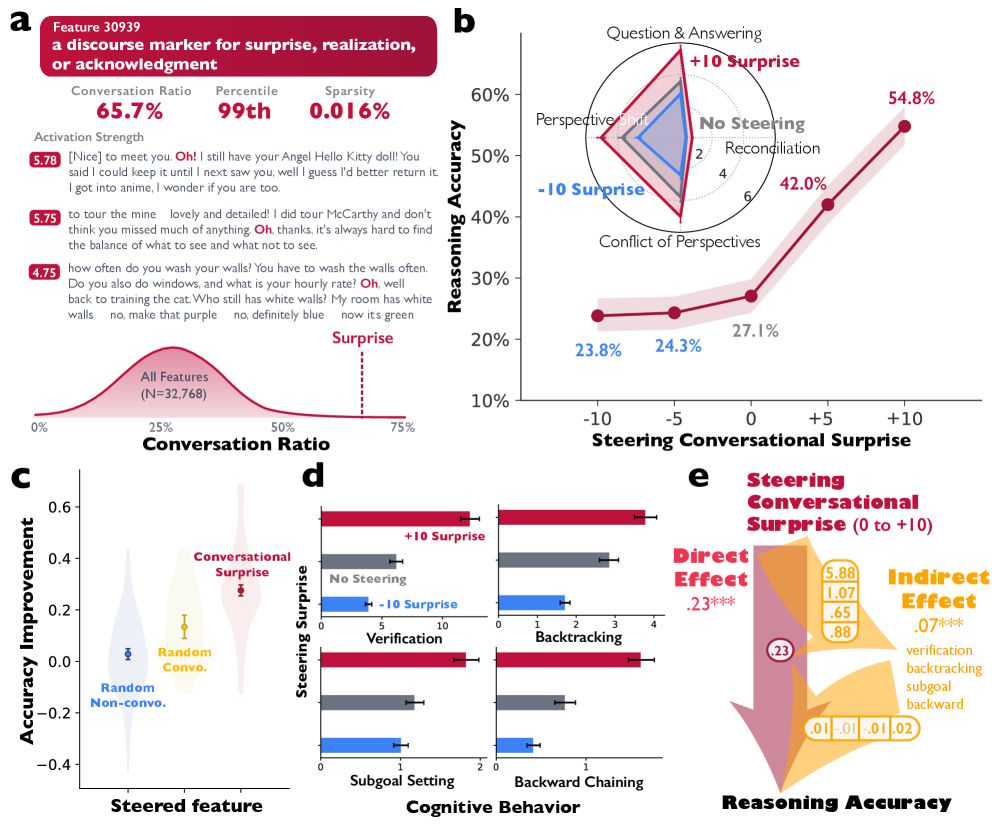
When the researchers artificially boosted this feature during text generation, accuracy on a math task doubled from 27.1 to 54.8 percent. The models also behaved more like a conversation: they checked intermediate results more often and caught their own mistakes.
Reinforcement learning produces social reasoning without explicit training
The researchers also ran controlled reinforcement learning experiments. These showed that base models "spontaneously increase conversational behaviours" when rewarded for accuracy. No explicit training on dialogue structures was needed.
The effect was even stronger for models previously trained with dialogue-like thought processes: they reached high accuracy faster than those with linear, monologue-style chains. In Qwen-2.5-3B, dialogue-trained models reached about 38 percent accuracy after 40 training steps. Monologue-trained models stalled at 28 percent.
The dialogue-like thought structure also transferred to other tasks: models trained on math problems with simulated multi-perspective discussions learned faster even when detecting harmful or toxic content.
Findings mirror research on collective intelligence in human groups
The authors draw parallels to research on collective intelligence in human groups. Mercier and Sperber's "Enigma of Reason" theory argues that human thinking evolved primarily as a social process. Bakhtin's concept of the "dialogical self" describes human thought as an internalized conversation between different perspectives. The study suggests reasoning models form a computational parallel to this collective intelligence: diversity enables better problem-solving, as long as it's systematically structured.
The researchers are careful to note they make no claim about whether the reasoning traces represent discourse between simulated human groups or a simulation of a single mind emulating multi-agent interaction. Still, the similarities with findings on successful human teams suggest that principles of effective group dynamics could offer useful clues for improving reasoning in language models.
In the summer of 2025, Apple researchers raised fundamental doubts about the "thinking" capabilities of reasoning models. Their study showed that models like Deepseek-R1 break down as problem complexity increases and, paradoxically, reason less. The Apple researchers called this a "fundamental scaling limit." Other studies have reached similar conclusions, though the finding remains controversial.
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe now