Study finds AI search engines struggle with news attribution

A new study reveals major problems with how AI search engines handle news citations, even when they have formal agreements with publishers.
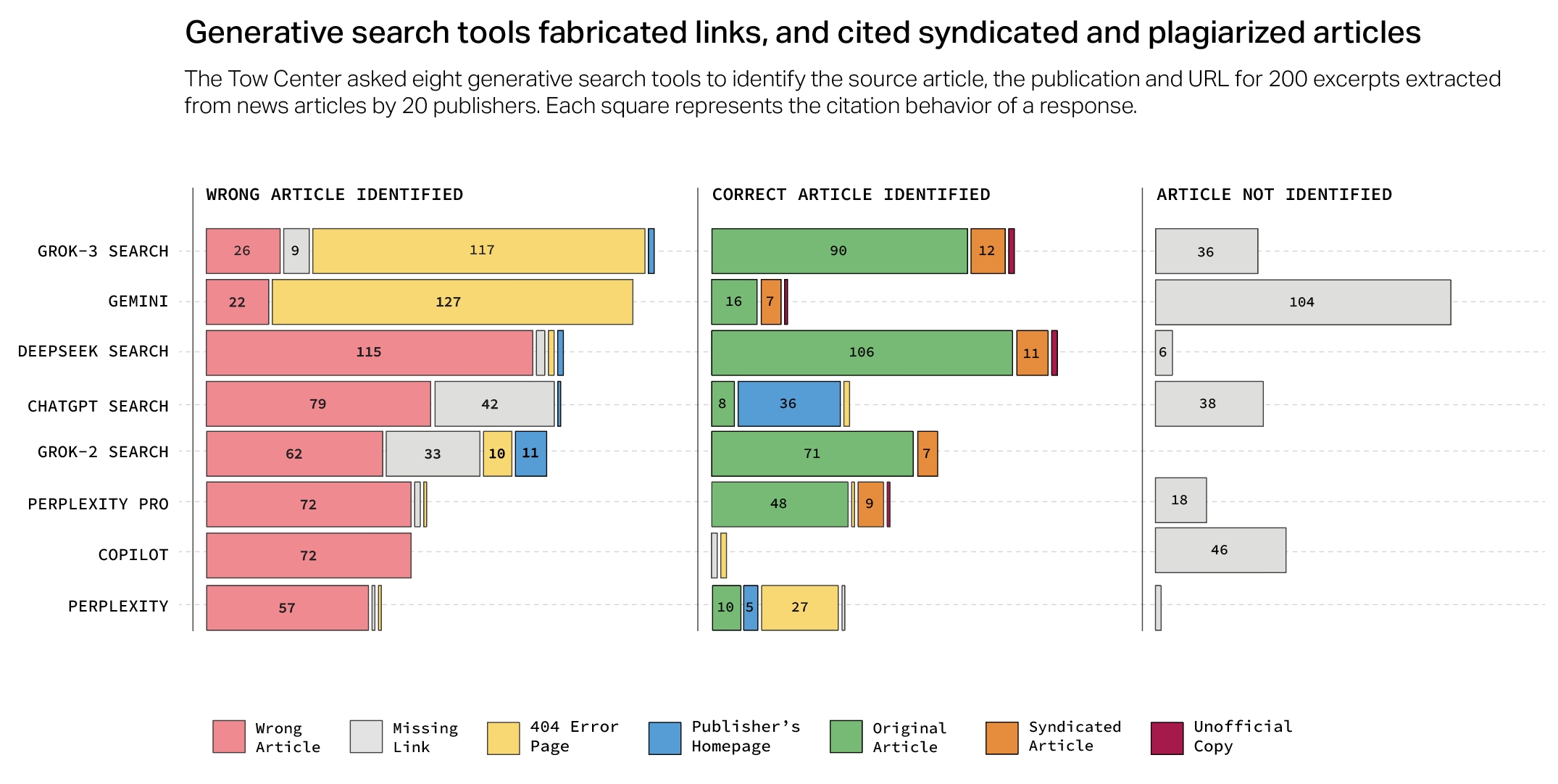
While nearly 25% of Americans now use AI search engines instead of traditional tools, according to recent data, these systems often fail at basic source attribution. Research from Columbia University's Tow Center for Digital Journalism tested eight AI search engines, including ChatGPT, Perplexity, and Google Gemini, by asking them to identify headlines, sources, publication dates, and URLs from random news articles.
The results paint a concerning picture: more than 60% of queries received incorrect answers. Perplexity emerged as the top performer with a 37% error rate, while Grok 3 struggled significantly, misattributing 94% of citations.

Paid services perform worse than free versions
Surprisingly, paid services like Perplexity Pro and Grok 3 performed worse than their free counterparts. While they attempted to answer more queries, they were more likely to provide incorrect information instead of acknowledging when they didn't know something.
Several systems also ignored publishers' Robots Exclusion Protocol settings. For example, Perplexity accessed National Geographic content despite the publisher explicitly blocking its crawlers.

Publisher agreements don't fix attribution issues
Even formal partnerships between publishers and AI companies haven't resolved the attribution problems. Despite Hearst's agreement with OpenAI, ChatGPT only correctly identified one in ten San Francisco Chronicle articles. Perplexity frequently cited syndicated versions of Texas Tribune articles instead of originals.
The study found that AI search engines often directed users to syndication platforms like Yahoo News rather than original sources. In more than half of cases, Grok 3 and Google Gemini created URLs that didn't exist.

Time Magazine's COO Mark Howard notes that AI companies are working to improve their systems but cautions against expecting perfect accuracy from current free services: "If anybody as a consumer is right now believing that any of these free products are going to be 100 percent accurate, then shame on them."
A separate BBC study in February identified similar problems with AI assistants handling news queries, including factual errors and poor sourcing.
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.