Study finds that fewer documents can lead to better performance in RAG systems
Researchers at the Hebrew University of Jerusalem have discovered that the number of documents processed in Retrieval Augmented Generation (RAG) affects language model performance, even when the total text length remains constant.
The research team used MuSiQue's validation dataset, which contains 2,417 answerable questions. Each question links to 20 Wikipedia paragraphs, with two to four paragraphs containing relevant answer information while the rest serve as realistic distractors.

To study how document quantity affects performance, the researchers created multiple data partitions. They gradually reduced the number of documents from 20 to 15, 10, eight, and finally down to just the two to four documents containing relevant information. To maintain consistent token counts and information positioning, they expanded the selected documents using text from the original Wikipedia articles.
Fewer documents lead to better results
Testing several open-source models including Llama-3.1, Qwen2, and Gemma 2 revealed that reducing document count improved performance by up to 10 percent in most cases. Qwen2 proved to be an exception, possibly handling multiple document collections more effectively. While these tested models are only a few months old, newer versions like Llama-3.3, Qwen2.5, and Gemma 3 have already superseded them.
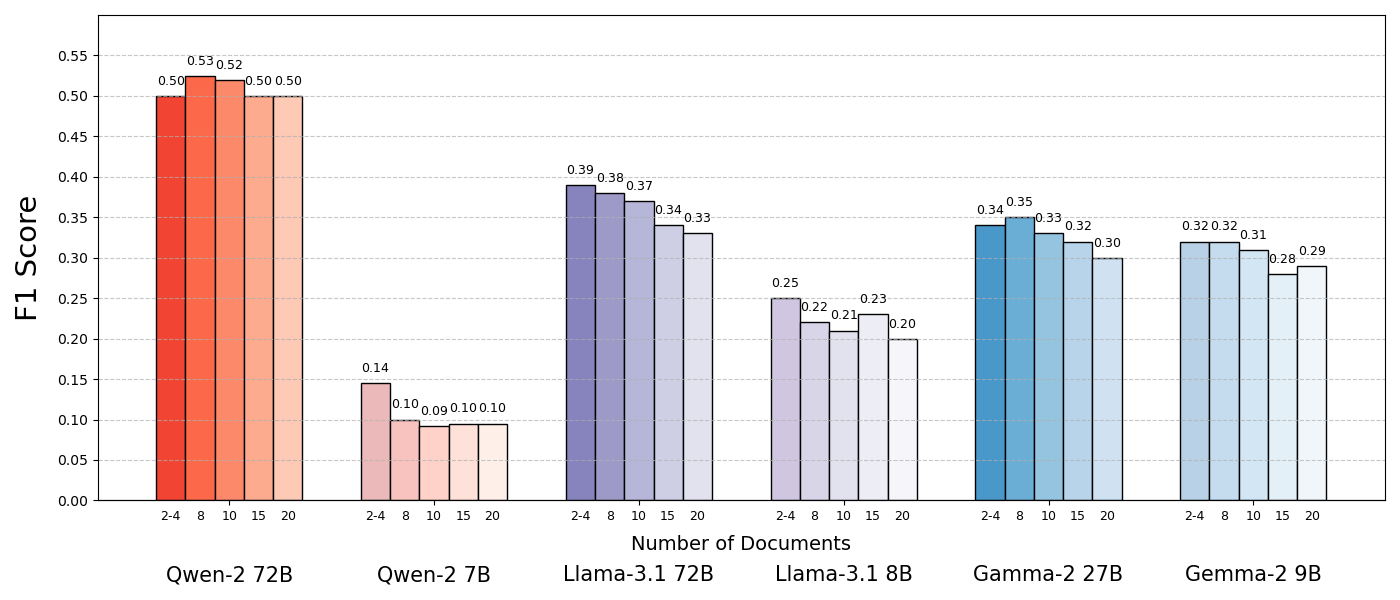
The language models performed significantly better when given only supporting documents, which meant shorter context and eliminated distracting content. The results showed that similar but unrelated documents, often retrieved in RAG systems, can confuse the model and reduce performance.
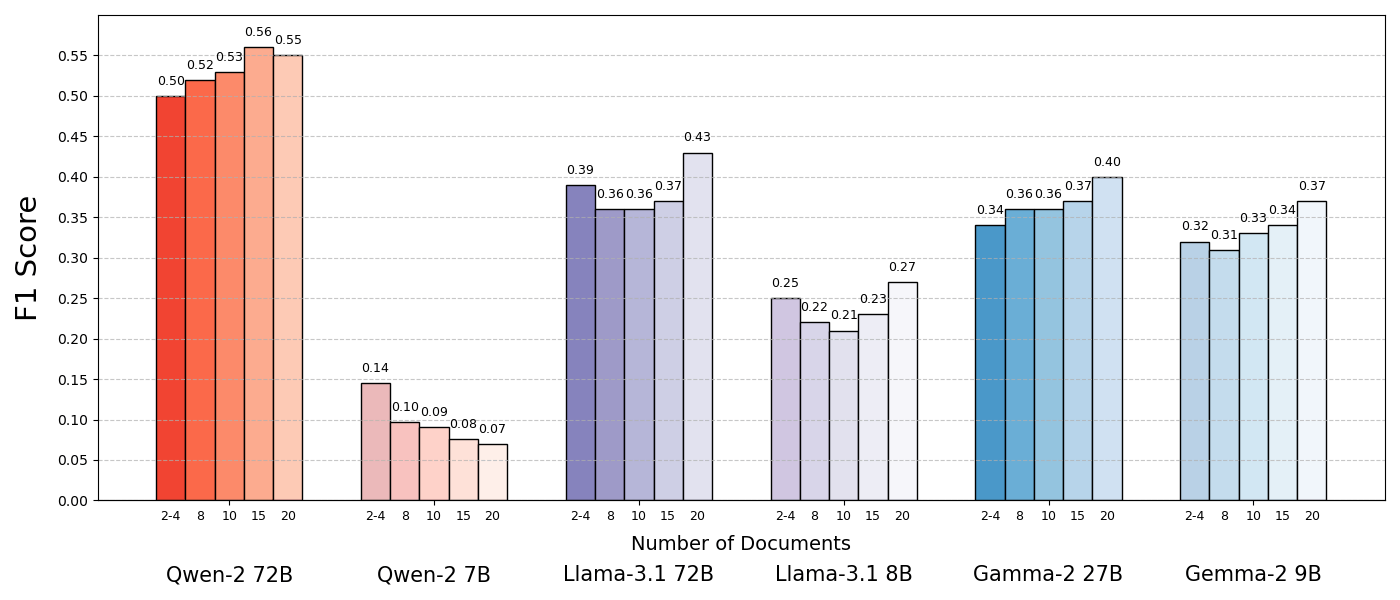
The study demonstrates that processing multiple documents makes tasks more challenging in a retrieval environment. The researchers emphasize that retrieval systems need to balance relevance and diversity to minimize conflicts. Future models might benefit from mechanisms that can identify and discard contradictory information while still utilizing document diversity.
The researchers acknowledge certain study limitations, including lack of investigation into prompt variations and data order effects. They've made their datasets publicly available to facilitate further research into multiple document processing.
The RAG versus context window debate continues
As context windows continue to grow, there's ongoing discussion about whether RAG systems remain necessary. While language models are getting better at processing large amounts of text at once, RAG architectures show particular advantages when using smaller open-source models.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.