Study shows: 'Test-time compute scaling' is a path to better AI systems

Researchers at Hugging Face have demonstrated significant performance improvements in open-source language models by intelligently scaling compute during inference, drawing inspiration from OpenAI's o1 model. Their approach combines various search strategies with reward models.
While scaling computing resources during pre-training and has been crucial for developing large language models (LLMs) in recent years, the required resources are becoming increasingly expensive, leading researchers to explore alternative approaches. According to Hugging Face researchers, scaling computing power during inference offers a promising solution by using dynamic inference strategies that allow models to spend more time processing complex tasks.
Although "test-time compute scaling" isn't new and has been a key factor in the success of AI systems like AlphaZero, OpenAI's o1 was the first to clearly demonstrate that language model performance can be significantly improved by allowing more time to "think" about difficult tasks. However, there are several possible approaches to implementation, and which one OpenAI uses remains unknown.
From basic to complex search strategies
The scientists examined three main search-based approaches. The "Best-of-N" method generates multiple solution proposals and selects the best one. Beam Search systematically explores the solution space using a Process Reward Model (PRM). The newly developed "Diverse Verifier Tree Search" (DVTS) additionally optimizes the diversity of solutions found.
The practical test results are impressive: A Llama model with just one billion parameters matched the performance of a model eight times larger. In mathematical tasks, it achieved an accuracy of nearly 55 percent—which Hugging Face says approaches the average performance of computer science PhD students.
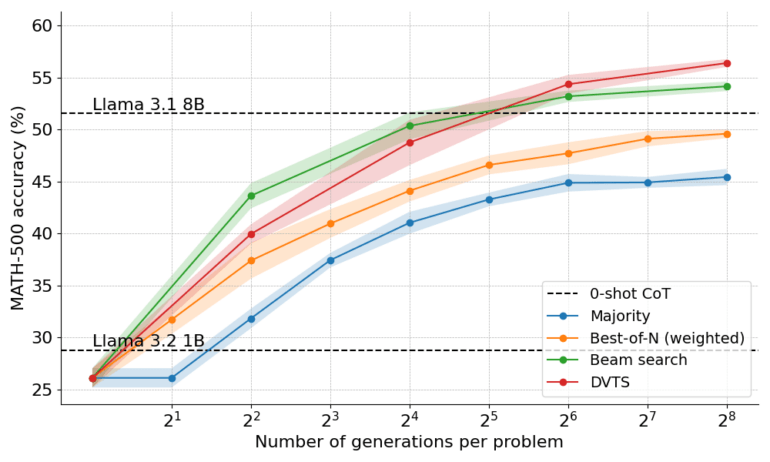
A 3-billion-parameter model even outperformed the 22-times-larger 70-billion-parameter Llama 3.1, thanks to the team's proposed optimized computation methods that select the best search strategy for each computing budget.
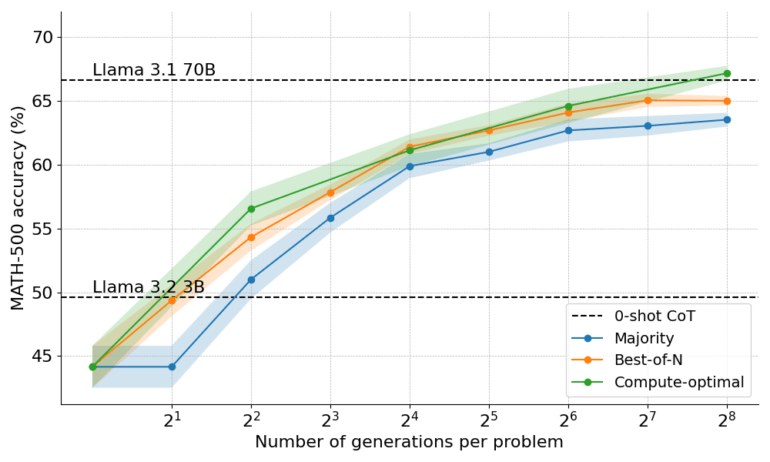
In both cases, the team compared the results of the smaller models using the inference methods against those of the larger models without these methods.
Verifiers play a key role
Verifiers or reward models play a central role in all these approaches. They evaluate the quality of generated solutions and guide the search toward promising candidates. However, according to the team, benchmarks like ProcessBench show that current verifiers still have weaknesses, particularly regarding robustness and generalizability.
Improving verifiers is therefore an important starting point for future research, but the ultimate goal is a model that can autonomously verify its own outputs—which the team suggests OpenAI's o1 appears to do.
More information and some tools used are available on Hugging Face.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.