Study shows why reasoning models often think far beyond the solution

Large reasoning models frequently think well past the correct answer: cross-checking, reformulating, and confirming what they already got right. A new Bytedance study shows the models actually know when they're done. Common sampling methods just don't let them stop.
The problem isn't new. Deepseek-R1 produces answers on the AIME 2025 benchmark nearly five times longer than Claude 3.7 Sonnet's, with comparable accuracy. QwQ-32B scores two percentage points higher with its shortest answers while using 31 percent fewer tokens. And in 72 percent of cases where both correct and incorrect answers were generated, the longer answer was more often wrong.
The answer is there, but the model keeps talking
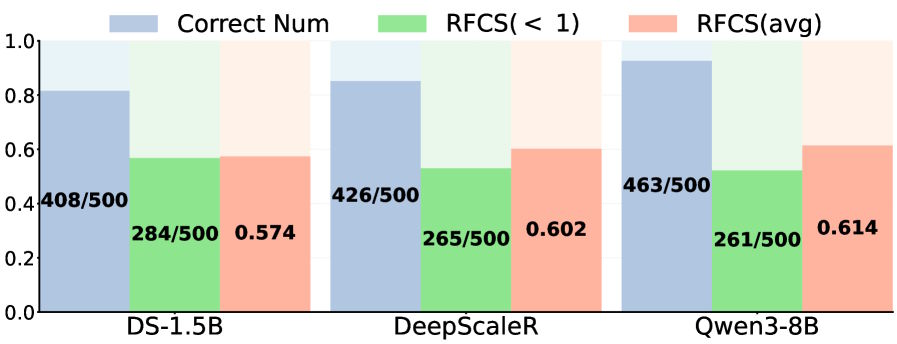
To quantify the problem, the researchers introduced RFCS (Ratio of the First Correct Step), which tracks where in a chain of thought the correct answer first appears relative to total length. On MATH-500, the correct solution shows up well before the end in more than half of all correctly answered problems.
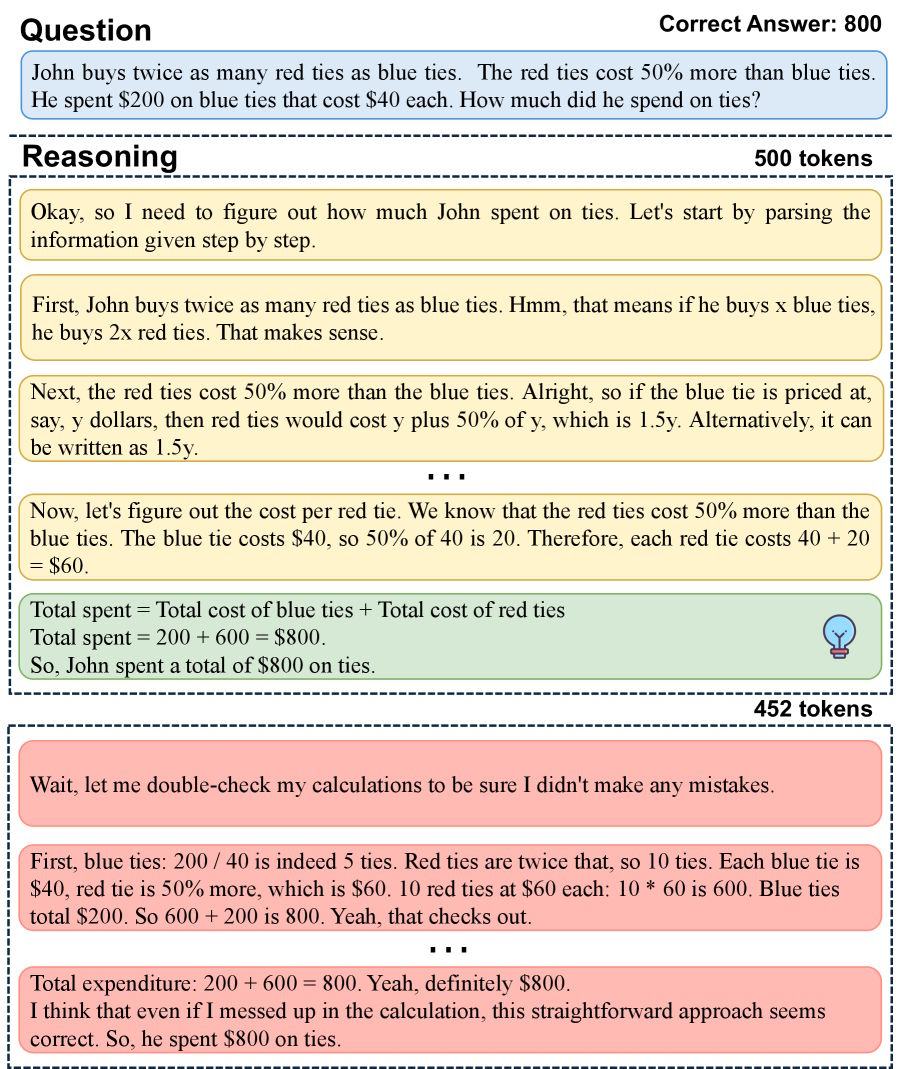
In one case, the model nailed the answer after 500 tokens but kept going for another 452: cross-checking, reformulating, and reconfirming what it already had right. This pattern shows up in both smaller models like Deepseek-R1-Distill-Qwen-1.5B and larger ones like Qwen3-8B. Stronger post-training doesn't fix it.
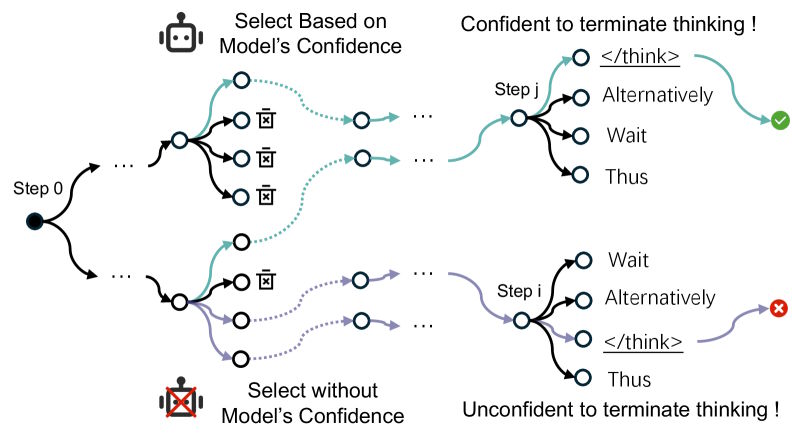
The models know when to stop; sampling methods don't
When models follow multiple chains of thought simultaneously during inference, they reliably find short, precise reasoning paths they assign high confidence to. The researchers demonstrate this with TSearch, which evaluates average probability across the entire chain rather than individual tokens.
Three observations back this up: selected paths produce shorter, more accurate answers. At those endpoints, the stop signal consistently ranks first among probable next tokens: the model knows it's done. And more parallel paths make this behavior more stable. Efficient termination is already baked into the models; common sampling methods just don't tap into it.
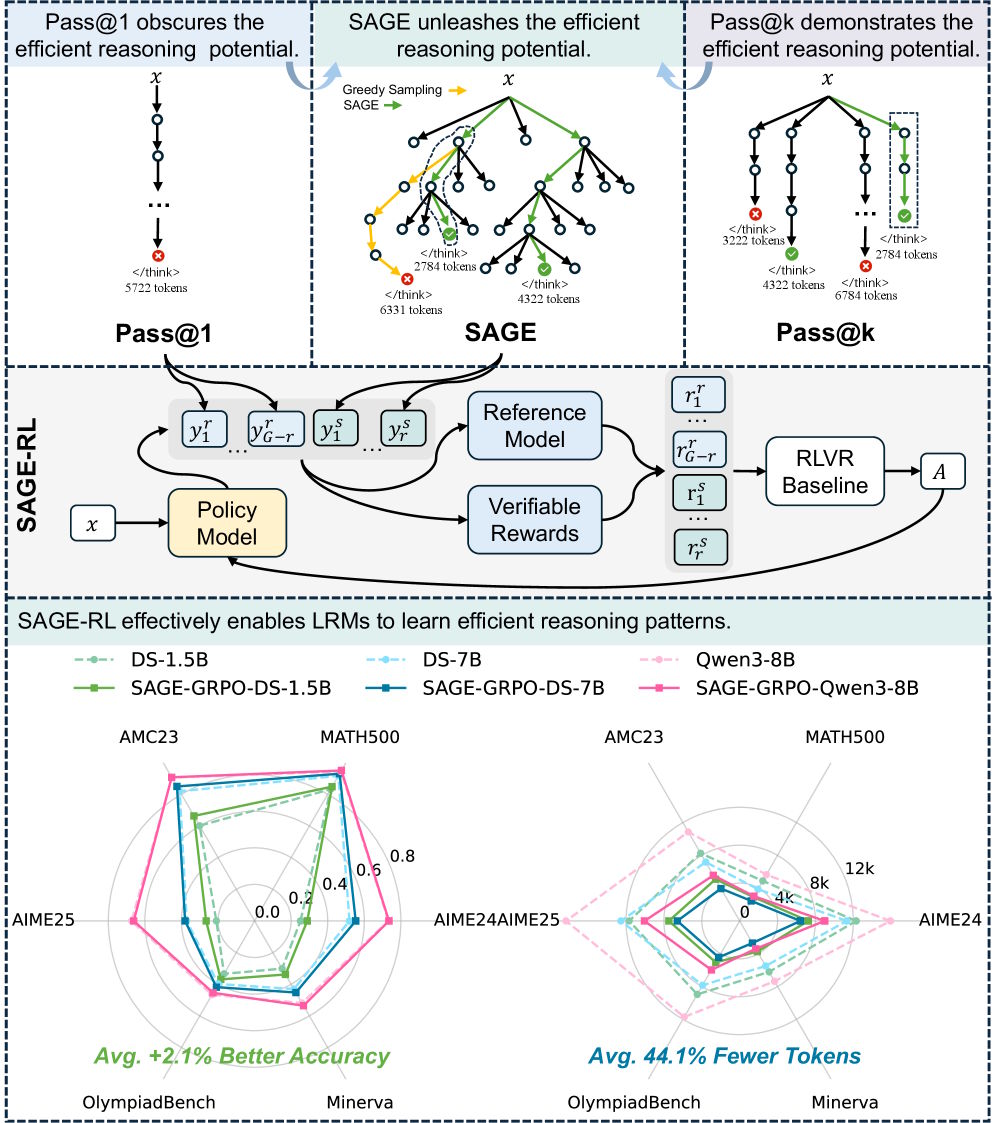
SAGE explores step by step, not token by token
The researchers' solution is SAGE (Self-Aware Guided Efficient Reasoning). Instead of expanding token by token, SAGE extends chains of thought in whole reasoning steps and checks after each whether the model signals it's done. If so, reasoning stops.
In experiments, SAGE behaved differently depending on the setup: with strong models on hard benchmarks, accuracy primarily increased. With weaker models on simpler tasks, answer length dropped significantly. Basically, SAGE shortened where models were overthinking and found better solutions where capacity was left on the table.
To make these patterns permanent, the researchers propose SAGE-RL, a small tweak to standard reinforcement learning. Out of eight responses per training group, two come from SAGE, six from standard sampling. The model learns to prefer tighter reasoning paths through the advantage estimator.
Results across six math benchmarks, MATH-500, AIME 2024 and 2025, and OlympiadBench among them, are consistent: methods like LC-R1, ThinkPrune, or AdaptThink cut tokens at the expense of accuracy. SAGE-RL improved both. On Deepseek-R1-Distill-Qwen-7B, SAGE-GRPO hit 93 percent on MATH-500 versus 91.6 percent, cutting response length from 3,871 to 2,141 tokens.
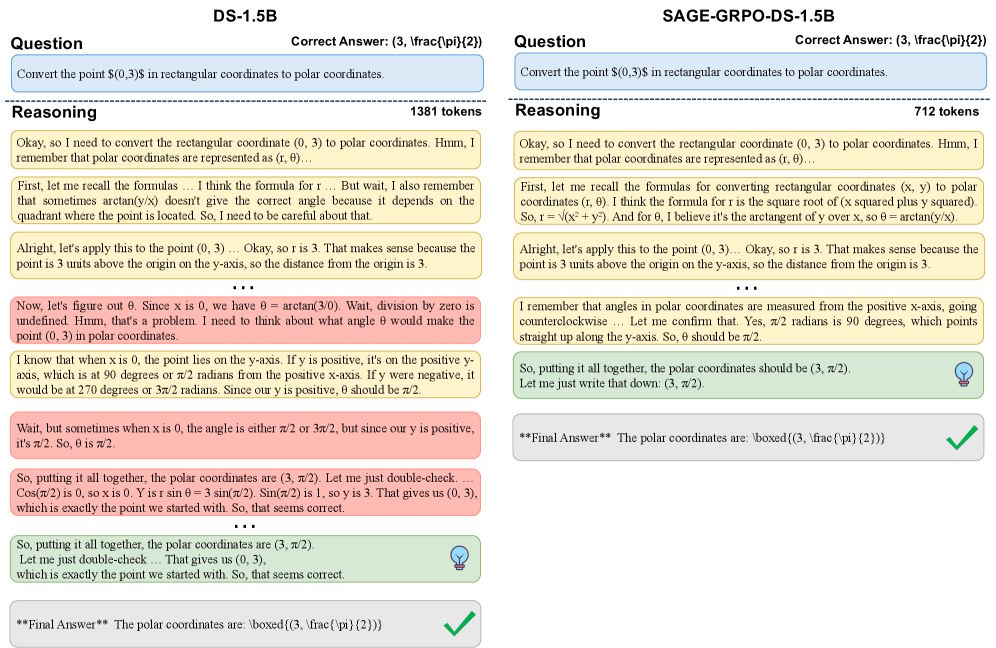
On AIME 2025, DS-1.5B's accuracy jumps 6.2 percentage points. Even Qwen3-8B, one of the strongest models in its class, sees SAGE-GRPO halve response length from 18,342 to 9,183 tokens without losing accuracy. Inference time drops over 40 percent across most models and benchmarks.
The biggest gains show up on the hardest tasks, suggesting that's where the most room for efficient reasoning exists. Fixing overthinking might not require new architectures or fancier reward functions. It might be enough to just let the models stop when they signal they're done.
Reasoning model overthinking has been a research topic for a while. About a year ago, a study showed excessive "thinking" in interactive scenarios noticeably hurts performance. More recently, Google researchers found that reasoning models structure their chains of thought as internal debates between simulated perspectives, improving accuracy but also explaining why reasoning takes so long.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.