
The "Tree of Thoughts" framework combines tree search with GPT-4 to dramatically improve the problem-solving capabilities of the language model.
"Tree of Thoughts" is a new framework from researchers at Princeton University and Google DeepMind for inferencing language models like GPT-4, inspired by prompt engineering methods like Chain of Thought. Unlike those, however, ToT is not based solely on prompting but uses an external module to use units of text, which the team calls "thoughts," as intermediate steps for problem-solving.
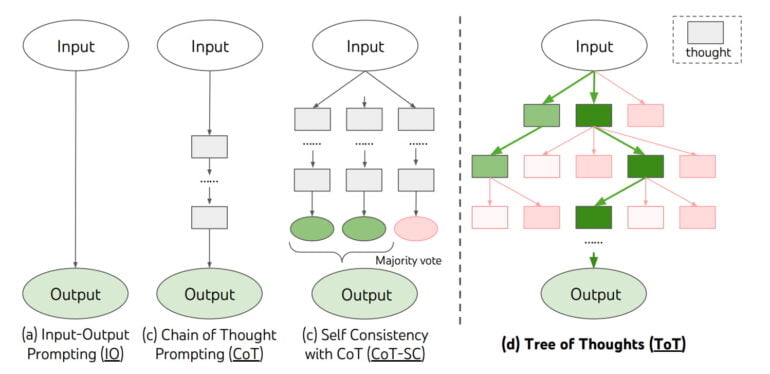
According to the team, ToT enables GPT-4 to make decisions by "considering multiple different reasoning paths and self-evaluating choices to decide the next course of action, as well as looking ahead or backtracking when necessary to make global choices."
In experiments, the team shows that the ToT framework improves GPT-4's problem-solving ability, sometimes dramatically. For example, while GPT-4 can solve only 4 percent of the tasks in "Game of 24" with chain-of-thought prompting, the language model with ToT achieves a 74 percent success rate. ToT also significantly improves GPT-4's performance on mini-crossword puzzles and creative writing tasks.
GPT-4 and AlphaZero come together
In this way, ToT augments the rudimentary reasoning capabilities of large language models such as GPT-4 with search heuristics similar to those used in AI systems such as AlphaZero. Unlike DeepMind's AI system, ToT does not learn but implements the search heuristic via GPT-4s self-evaluation and deliberation. According to the team, ToT is also inspired by Daniel Kahneman's distinction between System 1 and System 2.
The Tree of Thoughts framework provides a way to translate classical insights about problem-solving into actionable methods for contemporary LMs. At the same time, LMs address a weakness of these classical methods, providing a way to solve complex problems that are not easily formalized, such as creative writing.
Yao et al.
In another preprint, a researcher from Theta Labs also shows a " Tree of Thought" method and significant improvements in Sudoku puzzles. The author cites the self-playing techniques known from AlphaZero as an interesting research direction. A similar method could allow the ToT system to develop novel problem-solving strategies not found in the training text corpus of language models.





