Tencent open sources two high-performing translation models

Chinese tech giant Tencent has open sourced two specialized translation models, claiming they outperform established tools like Google Translate in international benchmarks.
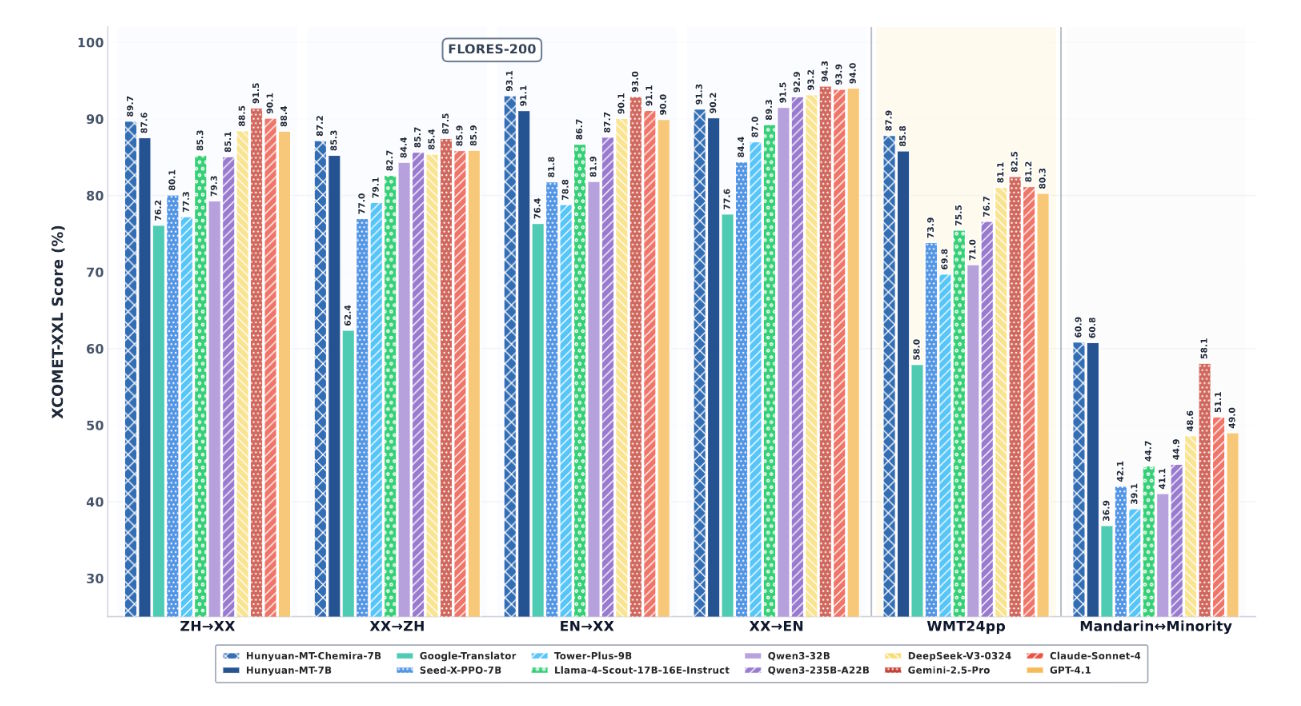
At WMT2025, a major workshop where research teams compare translation systems, Tencent's new models Hunyuan MT 7B and Hunyuan MT Chimera 7B took the top spot in 30 out of 31 language pairs tested. The Workshop on Machine Translation (WMT) is one of the leading events for evaluating translation models.
Both models support two-way translation across 33 languages, including widely used ones like Chinese, English, and Japanese, as well as less commonly digitized languages such as Czech, Marathi, Estonian, and Icelandic. Tencent says a major focus is translation between Mandarin Chinese and minority languages in China. The models can translate both ways between Chinese and Kazakh, Uyghur, Mongolian, and Tibetan.
7B-parameter models outperform larger competitors
Tencent's technical report shows the Hunyuan models beat established systems in direct comparisons. Compared to Google Translate, results improved by 15 to 65 percent, depending on language direction and evaluation criteria. Proprietary AI systems like GPT-4.1, Claude 4 Sonnet, and Gemini 2.5 Pro also fell short in most tests.
With 7 billion parameters, these models are much smaller than many foundation models in their class, so they require less computing power and can run on weaker hardware. Benchmarks show they still match or even beat larger systems in performance. In particular, they outperform the Tower Plus series (up to 72 billion parameters) by 10 to 58 percent.
In head-to-head tests with key language pairs, both Hunyuan models showed clear gains. Compared to Gemini 2.5 Pro, they scored about 4.7 percent higher. When tested against specialized translation models, improvements ranged from 55 to 110 percent.
The models are available as open source on Hugging Face, and Tencent has also released the source code on GitHub.
Training pipeline uses advanced post-training methods
Tencent used a five-stage training process: starting with general text, then refining with translation-specific data, followed by supervised learning on sample translations, reinforcement learning with reward signals, and a final "weak-to-strong" reinforcement learning step.
The training data included 1.3 trillion tokens just for minority languages, covering 112 languages and dialects. A custom evaluation system checked the data for knowledge value, authenticity, and writing style.
The Chimera model uses a fusion approach, combining multiple translation suggestions from different systems to generate a stronger final result. Tencent says this method improved standard test performance by an average of 2.3 percent.
Meanwhile, Google recently announced new AI features for its translation service, including live translation for real-time conversations and a personalized language learning mode, powered by the advanced reasoning and multimodal abilities of Gemini models.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.