Tencent's open source model Hunyuan-A13B combines fast and slow reasoning
Tencent has released its new language model Hunyuan-A13B as open source, introducing a dynamic approach to reasoning that lets the model switch between fast and slow "thinking" depending on the complexity of the task.
Hunyuan-A13B's key feature is its ability to adapt its depth of reasoning in real time. For simple queries, it uses a fast mode that delivers quick responses with minimal inference.
For more complex prompts, it activates a deeper reasoning process involving multistep thought. Users can toggle this behavior with special commands: "/think" enables the in-depth mode, while "/no_think" turns it off.
The model uses a Mixture of Experts (MoE) architecture with 80 billion total parameters, but only 13 billion are active during inference. It supports context windows of up to 256,000 tokens.
A focus on scientific reasoning
According to Tencent's technical report, Hunyuan-A13B was trained on 20 trillion tokens, then tuned for reasoning tasks and refined for broader use cases. Tencent assembled 250 billion tokens from STEM fields to boost the model's reliability in scientific tasks.
The training data includes math textbooks, exams, open-source code from GitHub, collections of logic puzzles, and scientific texts ranging from middle school to university level.
Video: Tencent
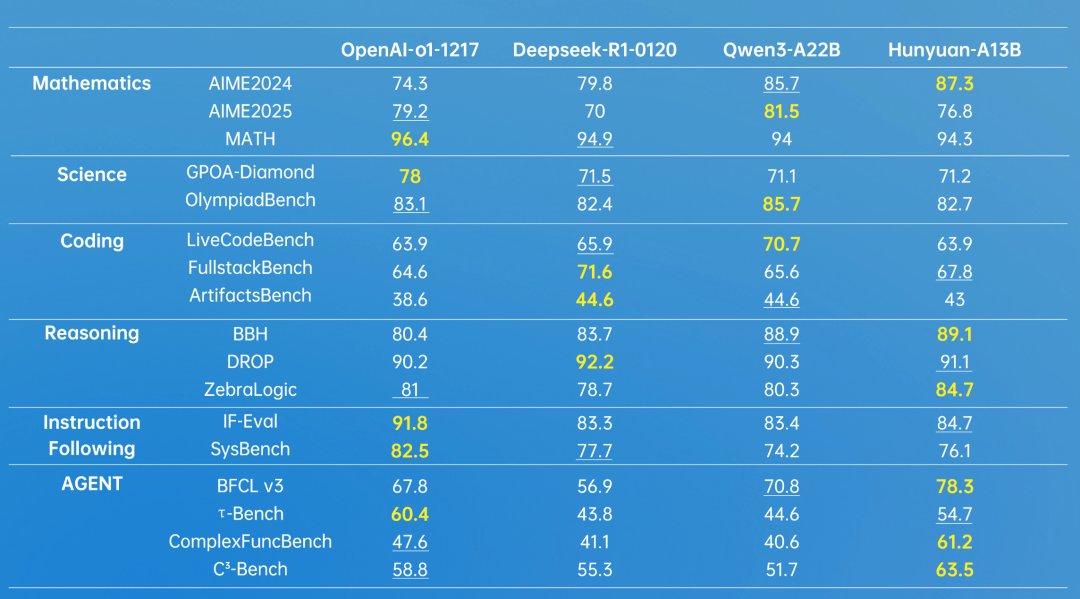
Tencent claims Hunyuan-A13B-Instruct can hold its own against leading models from OpenAI, Deepseek, and Alibaba's Qwen. In the 2024 American math competition AIME, the model reportedly achieves 87.3 percent accuracy, compared to OpenAI o1's 74.3 percent.
But a look at results from the 2025 edition shows that such comparisons aren't always clear-cut - o1 leads by nearly three percent in that round. Tencent also bases its comparisons on an outdated January version of Deepseek-R1, even though the May release performed significantly better in AIME 2024 and 2025, scoring 91.4 and 87.5 points, respectively.
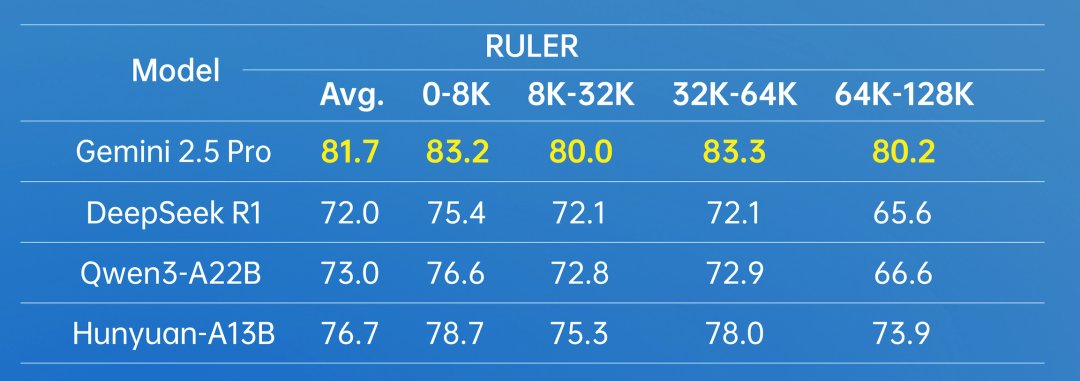
Tencent says the model excels at automated agent tasks and tool use. In internal benchmarks, A13B scored highest in nearly all agent benchmarks. Even as tests pushed up to 128,000-token contexts, Hunyuan-A13B's performance stayed above Deepseek-R1 and Qwen3-A22B, though it fell short of Gemini 2.5 Pro.
The model is available under the Apache 2.0 license on Hugging Face and GitHub, with ready-to-use Docker images for various deployment frameworks. API access is offered through Tencent Cloud and a browser demo.
Tencent has also released two new benchmark datasets: ArtifactsBench for code generation and C3-Bench for agent task evaluation.
Tencent's dynamic reasoning strategy is in line with trends seen at other leading AI labs. The concept of switching between different reasoning modes echoes recent models like Claude 3.7 Sonnet and Qwen3, which also support adaptive reasoning.
Tencent's shift toward language models follows earlier work on video generation. In December 2024, the company launched HunyuanVideo, followed in March by Hunyuan-T1, a reasoning-focused LLM that Tencent says already matched OpenAI o1's performance.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.