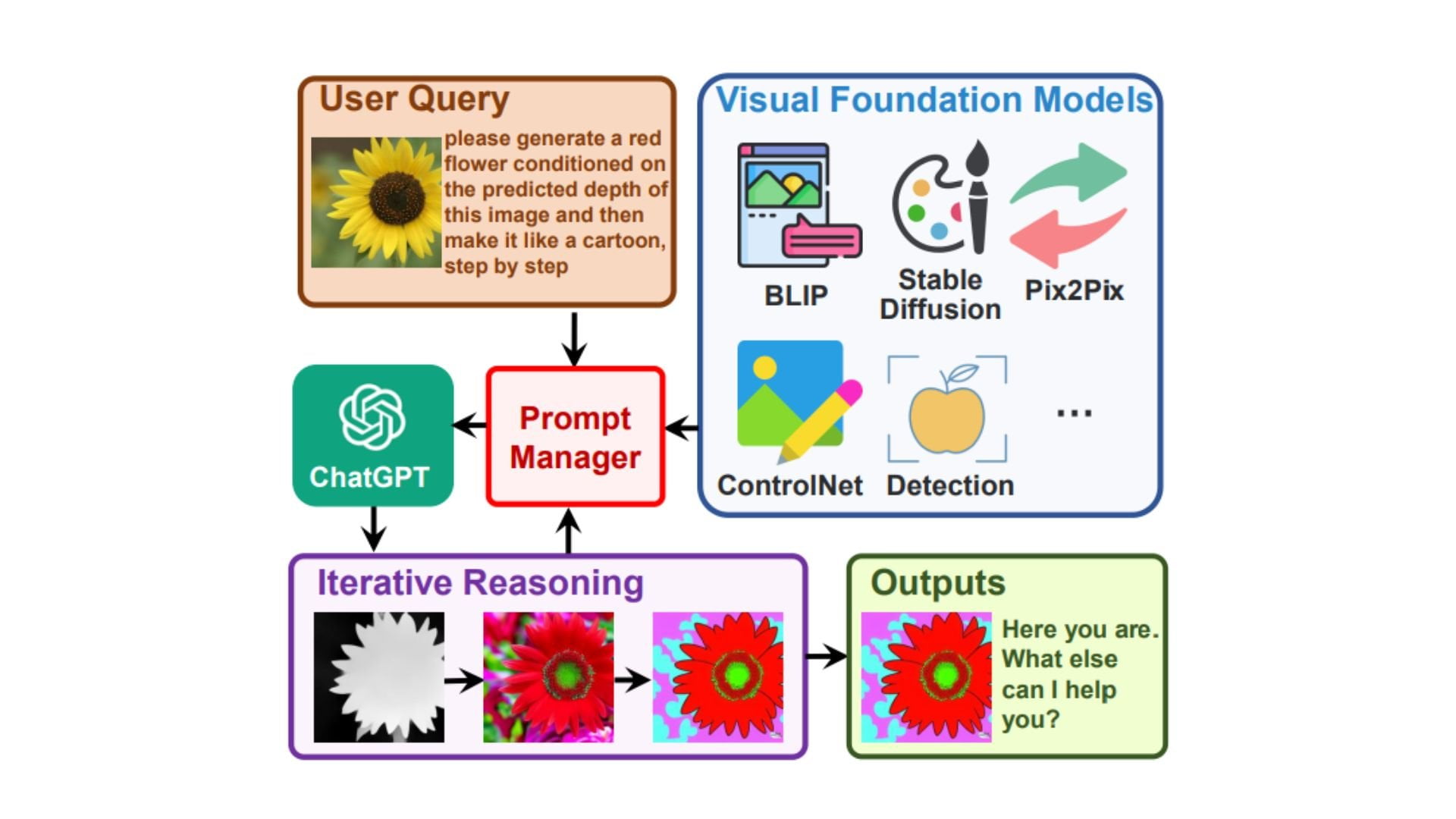
The future of AI models is multimodal, there's no doubt about that. However, this does not necessarily require the training of large new models. Instead, existing solutions can be linked together.
Microsoft has added an important feature to the OpenAI chatbot ChatGPT, which was released in November 2022: image processing. Until now, the language model could only handle text, but Visual ChatGPT can send and receive images as well as text.
According to the researchers, a multimodal conversation model could be trained for this purpose, but this would require a large amount of data and computing resources. In addition, this approach is not very flexible, and the model cannot be extended to other modalities, such as audio or video, without new training.
Linking ChatGPT to 22 image models
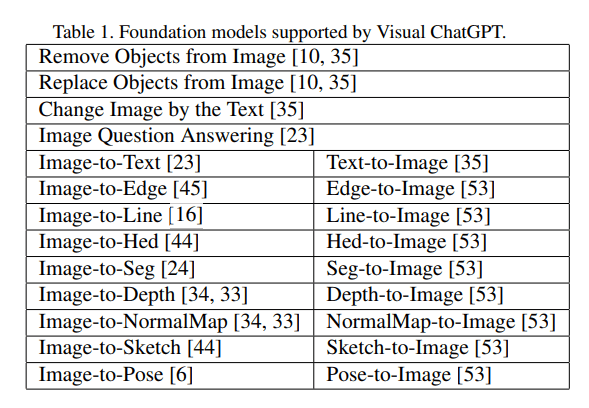
Instead of training a new model, the researchers linked ChatGPT to 22 different Visual Foundation Models (VFM), including Stable Diffusion. These models perform different tasks, such as answering questions about images, generating and processing images, or extracting information such as depth data.
The team bridges the gap between ChatGPT and VFM with a Prompt Manager that performs the following tasks:
- Explicitly tell ChatGPT the capabilities of each VFM and specifies the input-output formats.
- Converts different visual information such as PNGs or images with depth information into a language format that ChatGPT can understand.
- Handles the histories, priorities, and conflicts of the different VFMs.
Visual ChatGPT can generate images, name them correctly, save them, and keep them ready for further input or process images from users as input.
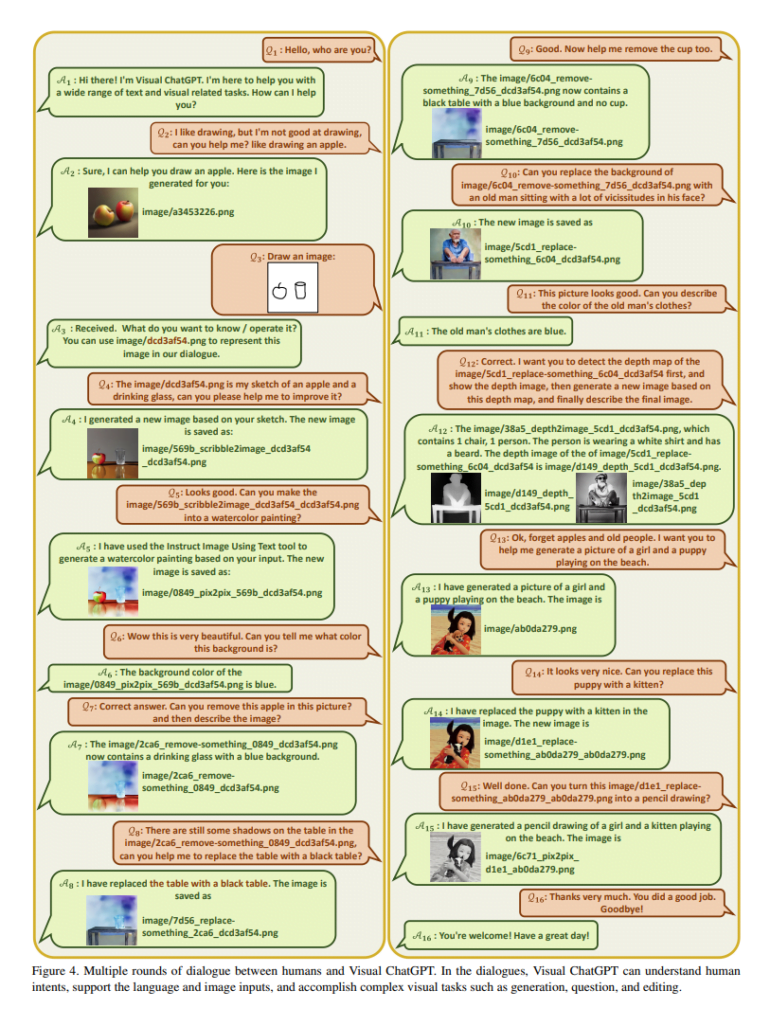
If the conversation model is not clear which VFM is best suited to solve the task, Visual ChatGPT will ask. It can also connect multiple VFMs in this way.
Although the examples shown by Microsoft with Visual ChatGPT are promising, there are still some limitations. Visual ChatGPT is, of course, completely dependent on ChatGPT and the linked image models.
The maximum number of tokens that ChatGPT can process is also a limiting factor. In addition, a significant amount of prompt engineering is required to convert VFMs to language.

Previous developments laid important foundations
Microsoft is integrating into Visual ChatGPT some existing methods for more control over image models with additional models or prompt engineering. There have been several advances in this area in recent months, such as InstructPix2Pix, ControlNet, or GLIGEN.
The researchers have published their source code on GitHub. A demo is also available on Hugging Face but requires a separate API key from OpenAI.



