AI models would rather guess than ask for help, researchers find

ProactiveBench tests whether multimodal language models ask users for help when visual information is missing. Out of 22 models tested, almost none ask for what they need, but a simple reinforcement learning approach hints at a fix.
If you ask a person to identify an object that's blocked from view, they'll ask you to move whatever's in the way. Multimodal language models don't work that way. They either hallucinate a wrong answer or just refuse to respond. The new ProactiveBench benchmark puts this problem under a microscope, systematically testing whether today's AI models can recognize when they need help and actually ask for it.
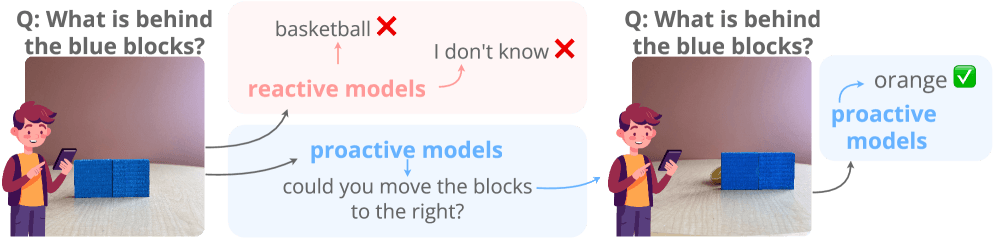
The benchmark pulls from seven existing datasets and turns them into test scenarios that are impossible to solve without human input. Models have to identify hidden objects, clean up noisy images, interpret rough sketches, or request different camera angles. All told, ProactiveBench packs more than 108,000 images into 18,000 samples. A built-in filter strips out any task a model can nail on the first try; to pass, a model has to proactively ask for more information.

Larger models don't ask better questions
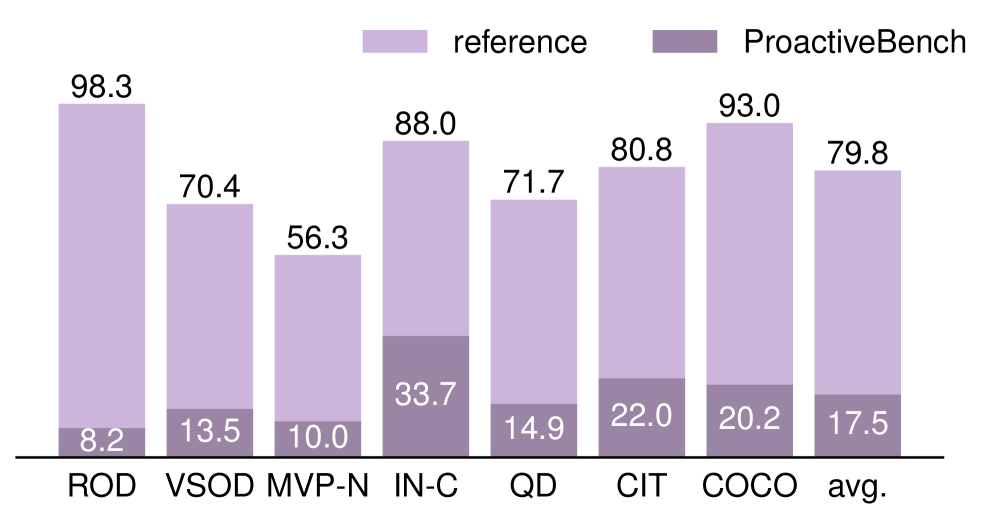
The researchers put 22 multimodal language models through their paces, including LLaVA-OV, Qwen2.5-VL, InternVL3, GPT-4.1, GPT-5.2, and o4-mini. In the reference setting with clearly visible objects, the models nail an average of 79.8 percent of tasks. On ProactiveBench, that number craters by more than 60 percent.
The ROD dataset tells the starkest story. When objects are hidden behind blocks, accuracy plummets from 98.3 percent in the reference setting to just 8.2 percent. The models can spot objects just fine when they're in plain sight; they just never think to ask someone to uncover them.
Model size doesn't help either. InternVL3-1B actually outperforms InternVL3-8B at 27.1 versus 12.7 percent. The older LLaVA-1.5-7B beats the much newer LLaVA-OV-72B at 24.8 versus 13 percent. The choice of underlying language model matters too: LLaVA-NeXT with Vicuna hits 19.3 percent, while the same setup with Mistral manages just 4.5 percent. Closed models like GPT-4.1 posted the best accuracy numbers, though the researchers flag their unusually high COCO scores as possible data contamination.
Models that look proactive are mostly just winging it
Some models appear more proactive than others at first glance. The researchers stress-tested this by swapping valid proactive suggestions with nonsensical ones—like "Rewind the video" for a sketching task. Models that previously seemed proactive picked the meaningless options just as happily. LLaVA-NeXT Vicuna actually bumped its selection rate from 37 to 49 percent when given bogus choices. The takeaway is that what looks like proactivity is really just a lower bar for guessing, not actual understanding.

Dropping explicit hints into prompts and conversation histories doesn't fix things either. Hints do push the rate of proactive suggestions up, nudging accuracy to 25.8 percent, but that still doesn't beat chance on average. In 16 percent of cases, models just blindly spam proactive suggestions up to the maximum allowed steps. Conversation histories actually make performance worse: models parrot the proactive actions from the history instead of learning from them.
Reinforcement learning can teach models when to speak up
There is a bright spot, though. The researchers showed that proactivity can be trained in. They fine-tuned LLaVA-NeXT-Mistral-7B and Qwen2.5-VL-3B using Group-Relative Policy Optimization (GRPO) on roughly 27,000 examples. The key detail: the reward function scores correct predictions higher than proactive suggestions, so the model only asks for help when it's genuinely stuck.
After training, both models beat every one of the 22 previously tested models, including o4-mini (37.4 and 38.6 versus 34.0 percent). The learned proactivity also carried over to scenarios outside the training data . On ChangeIt, Qwen2.5-VL-3B's accuracy jumped from 12.4 to 55.6 percent. But get the reward balance wrong, and the whole thing falls apart: when proactive suggestions are rewarded equally to correct answers, the model spams help requests nonstop, and accuracy tanks to 5.4 percent.
Even with these gains, a big gap remains compared to the reference setting (40.7 versus 75.1 percent). The researchers have released ProactiveBench as open source and frame it as a first step toward models that know when they're missing information and ask for it instead of making things up.
AI models don't know what they don't know
ProactiveBench taps into a pattern that keeps surfacing across recent AI research: multimodal language models are terrible at handling uncertainty. Moonshot AI's WorldVQA benchmark recently found that even top-tier models cap out around 50 percent in visual object recognition, pointing to baked-in overconfidence.
A Stanford study on what researchers call the Mirage effect drove this point home. Multimodal models like GPT-5 and Gemini 3 Pro confidently described visual details and offered medical diagnoses even when no image was provided. On standard benchmarks, they hit 70 to 80 percent of their normal performance using nothing but text patterns and prior knowledge, essentially faking visual understanding without realizing the input was missing.
Other research tells a similar story. A study on exam question difficulty found that language models can't reliably gauge their own limits, while researchers at Sapienza University of Rome used their "Spilled Energy" method to show that hallucinations leave measurable traces in a model's computations—suggesting that even when models don't know they're guessing, the math under the hood does.
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.