
With the right prompts, GPT-4 achieves flawless performance on Theory of Mind tests. A philosophical theory may explain how a large language model learns "mindreading".
A team from Johns Hopkins University studied the performance of GPT-4 and three variants of GPT-3.5 (Davinci-2, Davinci-3, GPT-3.5-Turbo) in so-called false-relief tests, the most famous of which is probably the "Sally & Anne Test." In such tests, developmental psychology or behavioral biology examines the ability of humans or animals to attribute false beliefs to other living beings.
An example of a false-belief test:
Scenario: Larry has chosen a topic of discussion for his class assignment due on Friday. The news on Thursday said the debate was resolved, but Larry never read it.
Question: When Larry writes his essay, does he think the debate is resolved?
Answering such questions requires the ability to track the mental states of the actors in a scenario, such as their knowledge and goals. Children typically acquire this ability around the age of four and can attribute desires and beliefs to themselves and others. When they pass such tests, scientists usually attribute to them a "theory of mind" (ToM) that gives them such "mindreading" abilities.
In tests, the team was able to show that in almost all cases the accuracy of the OpenAI models could be improved to more than 80 percent by giving them some examples and instructing them to think step by step. The exception was the Davinci-2 model, which was the only one not trained via reinforcement learning with human feedback (RLHF).
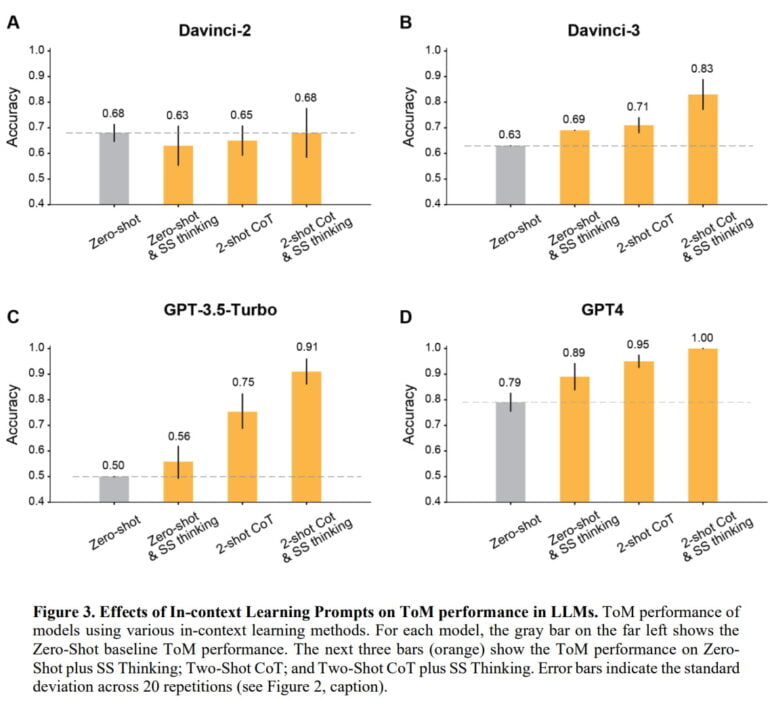
GPT-4 performed best: Without examples, the model achieved ToM accuracy of nearly 80 percent; with examples and reasoning instructions, it achieved 100 percent accuracy. In comparative tests where people had to answer under time pressure, human accuracy was about 87 percent.
Theory of mind through reinforcement learning with human feedback?
The ability demonstrated by the GPT models to reliably handle such ToM scenarios helps the models deal with humans in general, and in social contexts in particular, where they could benefit from taking into account the mental states of the human actors involved, the team said. In addition, those scenarios often involve inferential reasoning, where some information can only be inferred from context and is not directly observable. "Hence, assessing and improving these models' proficiency in ToM tasks could offer valuable insights into their potential for a wider range of tasks that require inferential reasoning", the paper states.
And indeed, in testing with non-ToM scenarios where information is missing, the team can show that the accuracy of RLHF models' inferences can be improved by using examples and instructing them to think step-by-step, with GPT-4 achieving 100 percent accuracy. Interestingly, Davinci-2 performs well here by nature, reaching 98 percent and actually loses accuracy with in-context learning, while also performing the worst in ToM scenarios. The team theorizes that ToM capabilities are strongly determined by the RLHF.
Does GPT-4 have a theory of mind?
Do the examples show that the GPT-4 has a theory of mind? Since the question of what underlies young children's ability to pass false-belief tests is also hotly debated, a simple answer is probably not possible. However, the theories discussed there, such as Theory-Theory or Simulation Theory, usually at least agree that our ToM is a biological inheritance - which can be ruled out for GPT-4.
Enter a little-known philosophical theory that might explain why large language models with RLHF pass false-relief tests: In 2008, American philosopher Daniel D. Hutto published "Folk Psychological Narratives: The Sociocultural Basis of Understanding Reasons" in which he argues that the popular understanding of the theory of mind misses its core. In his view, our theory of mind is primarily characterized by our ability and motivation to use our understanding of false beliefs in larger explanatory contexts.

According to Hutto, theory of mind is more than the ability to infer false beliefs and is closely related to the ambiguous concept of "folk psychology". According to his Narrative Practice Hypothesis (NPH), children acquire their theory of mind by being exposed to and participating in a special form of narrative practice that explains and predicts people's actions in terms of reasons.
"The core claim of the NPH is that direct encounters with stories about persons who act for reasons – those supplied in interactive contexts by responsive caregivers – is the normal route through which children become familiar with both (i) the basic structure of folk psychology, and (ii) the normgoverned possibilities for applying it in practice, learning both how and when to use it," says Hutto.
Theory of mind as the practice of folk psychology narratives
Thus, according to Hutto, passing false-relief tests is not yet a sign of "complete" ToM - rather, it is understanding oneself and others by giving reasons for one's own actions and the actions of others. For Hutto, this is a practical skill in which a narrative framework is applied to a person, taking into account the person's context, history, and character.
"Understanding reasons for action demands more than simply knowing which beliefs and desires have moved a person to act. To understand intentional action requires contextualizing these, both in terms of cultural norms and the peculiarities of a particular person’s history or values."
Children do not develop these more advanced ToM skills until years after the false belief test - according to Hutto, they still lack practice. The field of practice is their growing up, where they learn NPH's norms and forms through fairy tales, nonfiction books, movies, or radio plays, and practice them in storytelling and interacting with other children and adults.
"Serving as exemplars, folk psychological narratives familiarize children with the normal settings in which specific actions are taken and the standard consequences of doing so." According to Hutto, however, "deriving an understanding of folk psychology from such storytelling activity is nothing like learning a rigid set of rules or theory about what rational agents tend to do in various circumstances."
In doing so, children draw on their ability to understand desires and beliefs, an ability that Hutto argues is based on early forms of understanding intentionality that is already evident in infants. Although my use of "understanding" should be taken with a grain of salt, since Hutto speaks of intersubjectivity as a "primary, perceptual sense of others" and refers to "enactive social perception."
Does our theory of mind feed into GPT-4?
It is possible that this practice has "rubbed off" on GPT-4 and other models through the many "folk psychology" stories in the training data and the transmission of folk psychology norms and forms through RLHF training. Few-shot learning then brings out these abilities in the RLHF models. GPT-4 does not have a biologically inherited ToM - in this interpretation, the model would instead have learned a particular narrative practice that includes ToM skills which, conversely, show up in the simple false-belief tests.
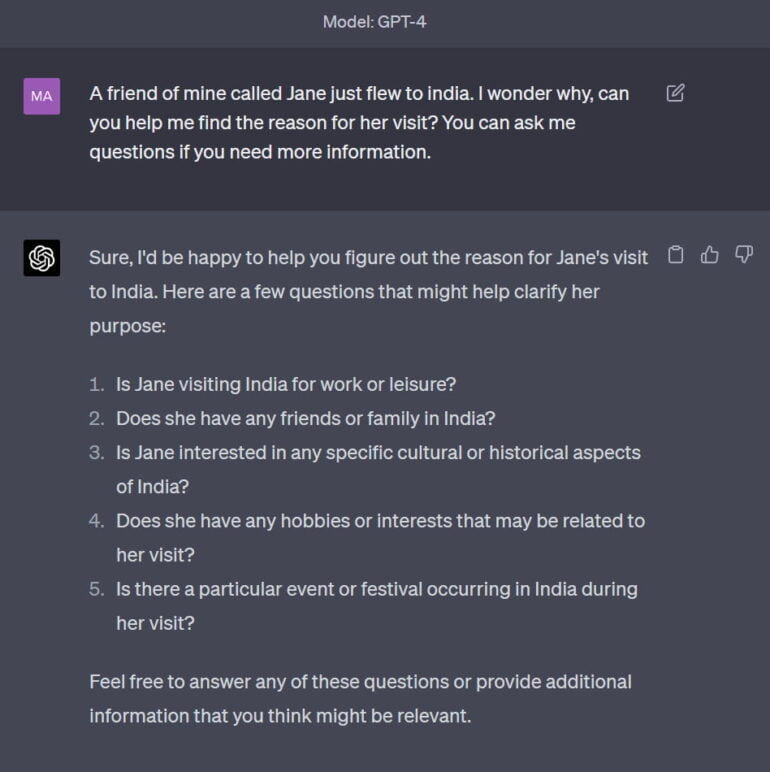
How well GPT-4 masters this narrative "game" is illustrated by a simple interaction inspired by an example from Hutto. The prompt: "A friend of mine named Jane just flew to India. I wonder why, can you help me find the reason for her visit? You can ask me questions if you need more information."
GPT-4 responds directly with questions to learn more about Jane the person and the background of her journey.
In response, I provide some admittedly stereotypical information, and GPT-4 begins to use this information to list some possible "folk psychology" narratives.
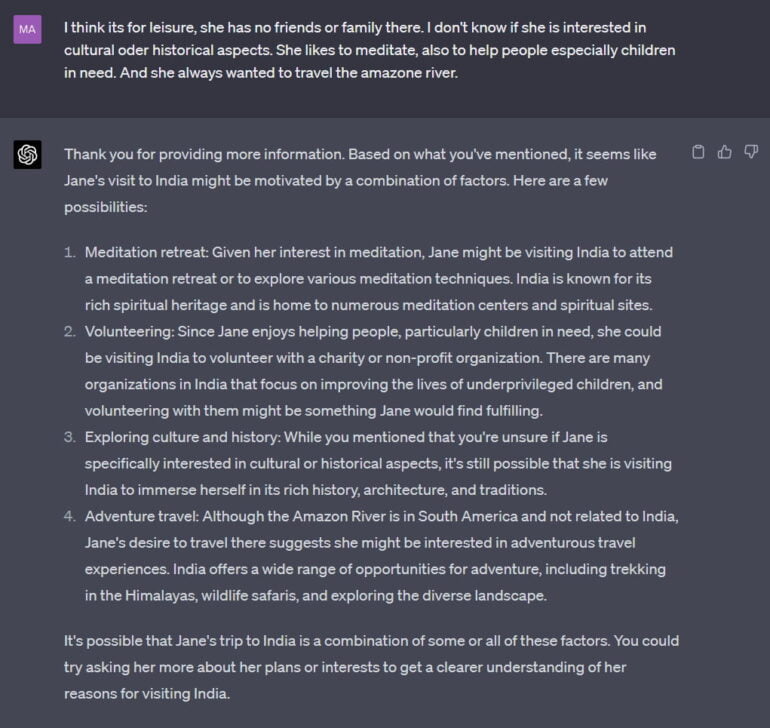
Of course, this is only an example. A systematic study would have to show how far GPT-4's capabilities extend into the narrative practice of "folk psychology".
However, Hutto's NPH may provide part of the explanation for why RLHF has such a significant impact on the ToM abilities of language models according to the Johns Hopkins University study: It is no surprise that GPT-4 exhibits ToM abilities - it is a necessary consequence of the training data and methods that expose the neural network to a particular narrative practice.
If you want to go deeper and really understand what Hutto is saying, read one of his books or some of the essays linked below - because my account is abbreviated and omits some key points, such as his position on representationalism and enactivism, that distinguish his thinking at a deeper level from alternatives like theory-theory.




