
InternLM is a large language model with 104 billion parameters introduced by China's national AI lab, Shanghai AI Lab, together with the surveillance company SenseTime.
The Chinese University of Hong Kong, Fudan University and Shanghai Jiaotong University were also involved in its development. On Chinese-language tasks, it clearly outperforms OpenAI's ChatGPT and Anthropics Claude.
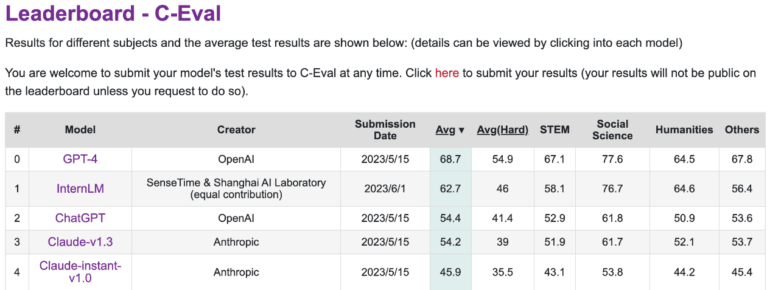
However, it trails GPT-4 in C-Eval, a platform that ranks the performance of large language models in Chinese. InternLM was trained with 1.6 trillion tokens and then, like GPT-4, refined to human needs using RLHF and selected examples. It is based on a GPT-like transformer architecture.
The training was based primarily on data from Massive Web Text, enriched with encyclopedias, books, scientific papers, and code. The researchers also developed the Uniscale LLM training system, which is capable of reliably training large language models with more than 200 billion parameters on 2048 GPUs using a set of parallel training techniques.
InternLM is at ChatGPT level in exam benchmarks
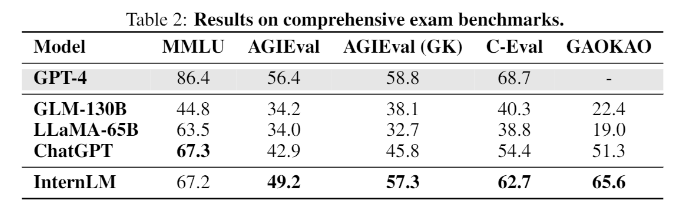
In benchmarks with tasks that mimic human exams, such as MMLU, AGIEval, C-Eval, and GAOKAO Bench, InternLM also achieves ChatGPT-level performance. However, it falls short of GPT-4, which the researchers attribute to the small context window of only 2000 tokens.
In other areas, such as knowledge retrieval, the model lags behind the best OpenAI models. Popular open-source language models, such as Meta's LLaMA with 65 billion parameters, perform worse than InternLM in benchmarks.
The team has not published the language model, so far, only technical documentation is available. However, the team writes on Github that it plans to share more with the community in the future, without giving details.
Regardless, InternLM provides an interesting glimpse into the current state of Chinese research on large-scale language models, assuming that the State AI Lab and SenseTime have done their best work to date. "Towards a higher level of intelligence, there remains a long way ahead," the research team writes.



