InseRF edits photorealistic 3D worlds via text prompt

Researchers at ETH Zurich and Google Zurich have presented a new method called InseRF for generating objects into 3D scenes.
The method uses a text prompt and a 2D bounding box at a reference point to generate new objects in a NeRF. Experiments show that InseRF outperforms existing methods and can insert consistent objects into NeRFs without requiring explicit 3D information as input.
InseRF combines advances in NeRFs with advances in generative AI, such as transforming single images into 3D models or 3D processing.
InseRF relies on diffusion models and NeRFs
To integrate new 3D objects into NeRF, InseRF starts with a 2D image of the 3D scene, on which the user can mark an area where a change should be made. The change is described by a text prompt, e.g. "a teacup on a table". InseRF then generates a teacup in this 2D view using a diffusion model and estimates the depth information of the generated view. This data is then used to update NeRF and generate the 3D cup.
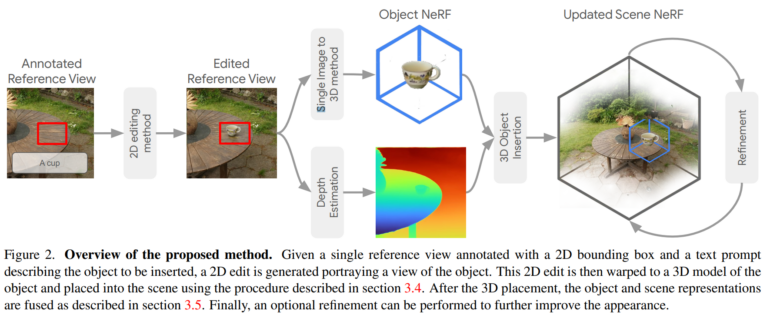
This process makes it possible to create a new 3D object in a scene that is consistent across multiple views and can be placed anywhere. According to the team, the method also overcomes the challenges of 3D-consistent creation and placement of objects in different views, which is a major hurdle for generative 2D models.
InseRF outperforms alternatives
The researchers test InseRF on some real indoor and outdoor scenes from the MipNeRF-360 and Instruct-NeRF2NeRF datasets. The results clearly show that InseRF can locally modify the scene and insert 3D-consistent objects.
Video: ETH Zurich / Google
The performance of InseRF is, however, limited by the capabilities of the underlying generative 2D and 3D models. But future improvements to these models could easily be applied to the InseRF pipeline. The team plans to test additional methods in the future, such as improving shadowing and equalizing the quality of the generated object and its environment.
Further examples and information can be found on the InseRF project page.
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.