Open-source LLM Jamba focuses on performance and efficiency with unique hybrid architecture
Israeli AI company AI21 Labs introduces Jamba, a hybrid language model that combines Transformer and structured state space modeling (SSM).
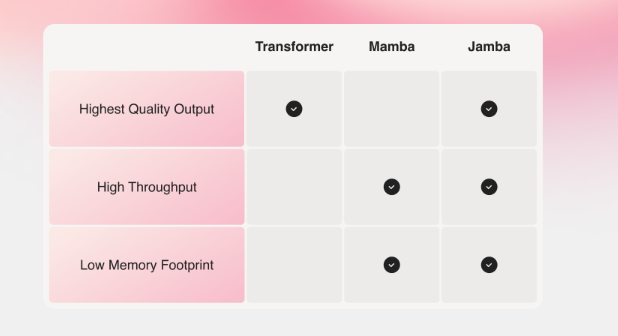
According to the company's announcement, Jamba is the first production-ready model based on a combination of the Transformer architecture and the Mamba SSM architecture. This hybrid approach is designed to surpass existing models in terms of efficiency and context window while maintaining high output quality.
Architectural innovation for more LLM efficiency
Researchers at Carnegie Mellon University and Princeton University developed the Mamba architecture. It specifically optimizes memory usage and processing speed, which decrease significantly with increasing context length in pure Transformer models.
However, pure SSM models do not achieve the same output quality as the best Transformer models, especially for tasks that require good memory. To address this issue, AI21 Labs combines both approaches in the Jamba architecture and adds Mixture-of-Experts (MoE) layers.
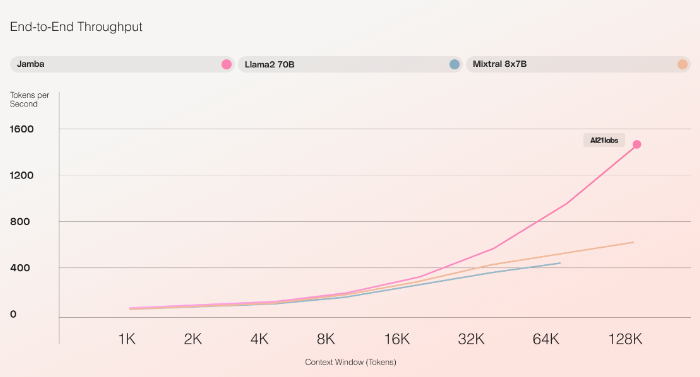
According to AI21 Labs, Jamba is the first hybrid SSM Transformer scaled to production size. It offers a context window of 256,000 tokens and, in initial tests, achieves a processing speed three times faster for long contexts than the Mixtral 8x7B Transformer. Jamba processes approximately 1,600 tokens per second, while Mixtral manages around 550.
Focus on efficiency with high output quality
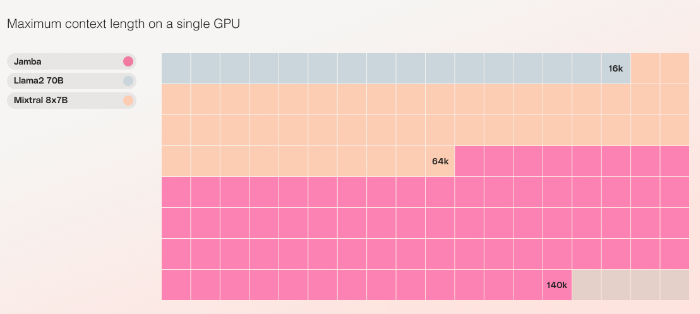
Jamba uses 12 billion of its 52 billion parameters for inference more efficiently than a Transformer-only model of comparable size. According to AI21labs, the additional parameters improve the model's performance without a proportional increase in computational complexity. Jamba is currently the only model in its size class that can process up to 140,000 token contexts on a single 80GB high-end GPU.
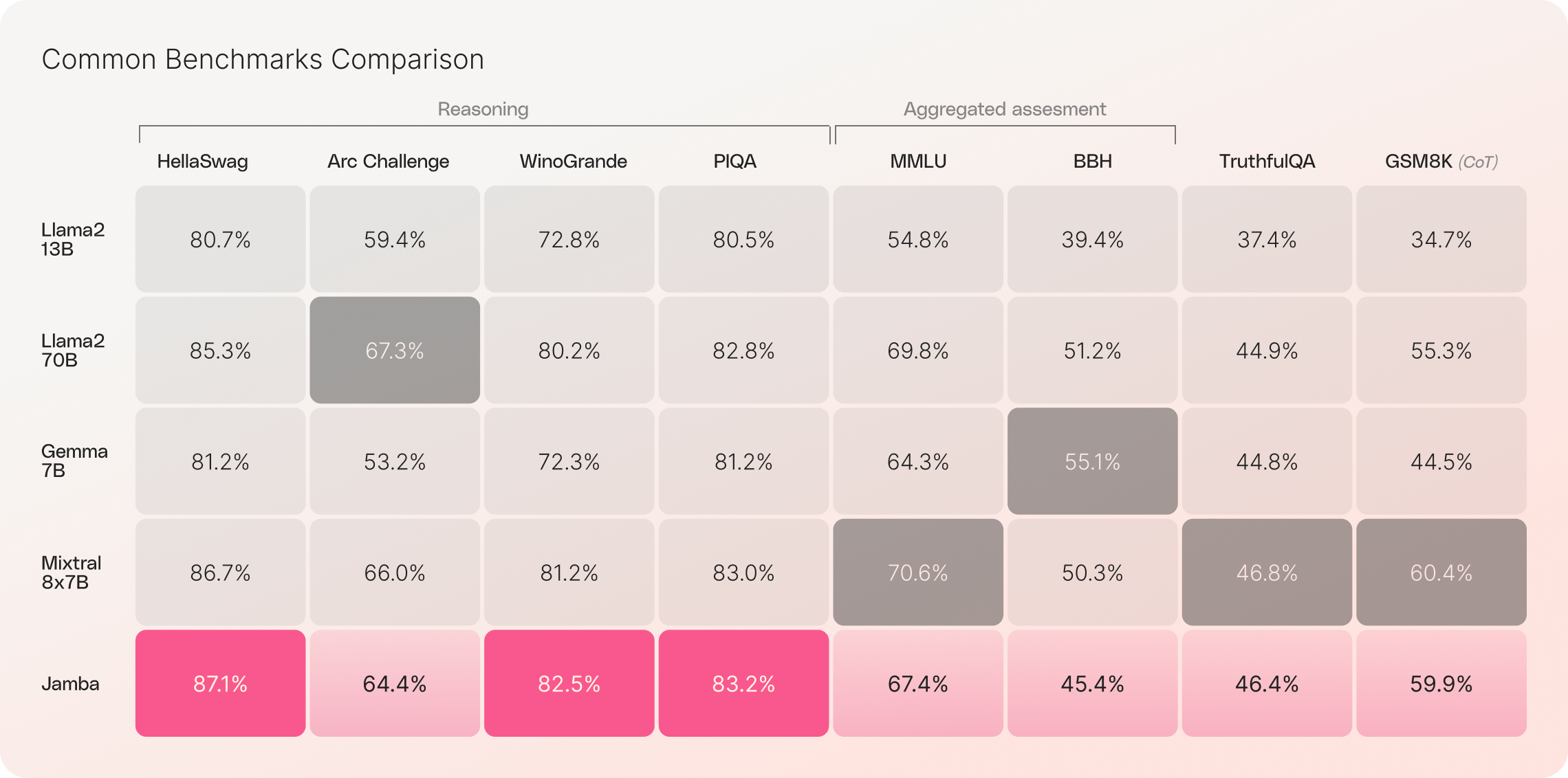
In benchmarks, Jamba performs on par with Mixtral8x7B while offering the aforementioned advantages in speed and efficiency.
AI21 makes the weights of the Jamba model available under the Apache 2.0 open-source license and invites developers to experiment with the model and develop it further. An Instruct version of Jamba will also be available soon as a beta through the AI21 Labs platform.
Additionally, Jamba is offered through Nvidia's API catalog, allowing developers of enterprise applications to deploy Jamba via the Nvidia NIM Inference Microservice.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.