Nvidia's eDiffi is an impressive alternative to DALL-E 2 or Stable Diffusion

Nvidia's eDiffi is a generative AI model for text-to-image and beats alternatives like DALL-E 2 or Stable Diffusion, according to the company.
Following OpenAI, Google, Midjourney, and StabilityAI, Nvidia is now showing a generative text-to-image model. All major generative text-to-image models today are diffusion models. Well-known examples are DALL-E 2, Midjourney, Imagen or Stable Diffusion.
These models perform image synthesis via an iterative denoising process, the eponymous diffusion. In this way, images are gradually generated from random noise.
Nvidia's eDiffi uses multiple denoiser experts
AI Models published or presented so far usually train a single model to denoise the entire process. In contrast, the eDiffi model now presented by Nvidia relies on an ensemble of expert denoisers specialized in denoising different intervals of the generative process.
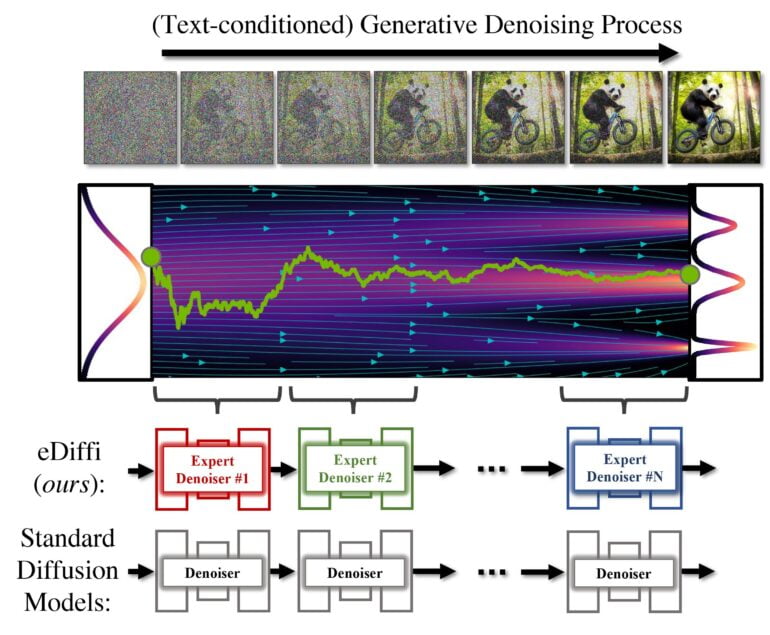
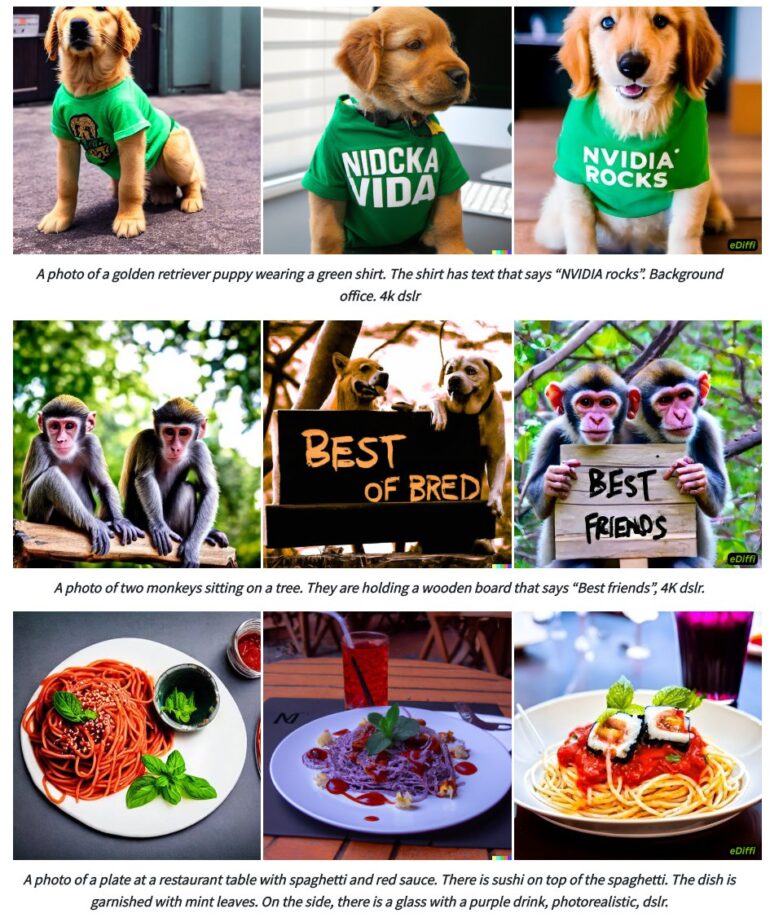
According to Nvidia, eDiffi achieves better results than DALL-E 2 or Stable Diffusion by using various expert denoisers. For example, eDiffi is better at generating text in images and better adheres to the content specifications of the original text prompt in the examples shown by Nvidia.
Nvidia's model relies on a combination of three diffusion models: a base model that can synthesize images at 64x64 resolution and two super-resolution models that incrementally upsample images to 256x256 or 1024x1024 resolution.
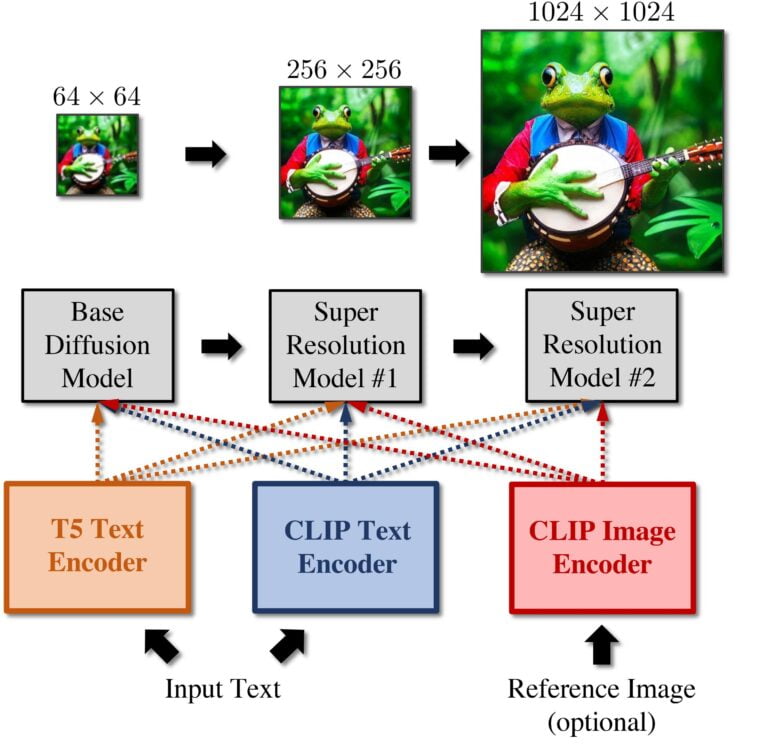
The models calculate T5 text embeddings in addition to the usual CLIP text and image embeddings. T5 is Google's text-to-text transformer and complements CLIP embeddings, according to Nvidia. Combining the two text embeds creates more detailed images that better match the prompt, Nvidia's researchers say.

Nvidia eDiffi paints with words
In addition to text prompts, eDiffi can also process a reference image as input and use its style for image synthesis.
Nvidia also shows a "paint with words" feature where the user can control the position of objects mentioned in the text input by first making a sketch, then selecting words and writing them on the image.
Video: Nvidia
Nvidia is keeping quiet about its plans with eDiffi. So far, only the paper is available.
But the changes presented in the training pipeline could be used in the future for new models of DALL-E or Stable Diffusion, where they could enable major advances in quality and control over the synthesized images.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.