Microsoft's "DIFF Transformer" promises more efficient LLMs with fewer hallucinations

Microsoft Research has created a new AI architecture called the "Differential Transformer" (DIFF Transformer) designed to enhance focus on relevant context while reducing interference. According to the researchers, this approach shows improvements in various areas of language processing.
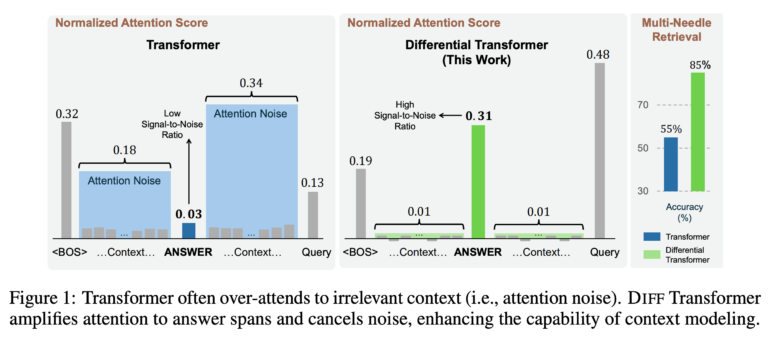
The core of the DIFF Transformer is "differential attention." This involves calculating two separate softmax attention maps and then subtracting them from each other. The researchers explain that this subtraction eliminates common noise in both attention maps - similar to how noise-canceling headphones work.
"Transformer tends to overallocate attention to irrelevant context" says the research team. This leads to problems in accurately retrieving key information. The DIFF Transformer aims to solve this issue through its novel attention mechanism.
DIFF Transformer shows more performance with less data
In tests, the DIFF Transformer achieved comparable performance to conventional transformers using about 65 percent of the model size or training data. For a 3-billion-parameter model trained on one trillion tokens, the DIFF Transformer outperformed variants with established transformer architecture, according to the study.
Advantages were particularly evident in processing longer contexts of up to 64,000 tokens. In tests extracting key information from long texts ("needle in a haystack"), the DIFF Transformer performed significantly better than conventional models. When positioning important information in the first half of a 64,000-token context, the new model achieved up to 76 percent higher accuracy, according to the researchers.
Fewer hallucinations, more robust learning, better quantization
Another advantage of the DIFF Transformer is the reduction of hallucinations - a common problem with large language models. When summarizing texts from datasets like XSum, CNN/DM, and MultiNews, the DIFF Transformer showed 9 to 19 percentage points higher accuracy than a comparable standard transformer. Similar improvements were observed in question-answering tasks.
The new architecture also proved more robust to changes in the order of examples in contextual learning - a known issue with conventional models.
The researchers also report benefits in quantizing AI models. Quantization reduces the continuous values of model parameters to a limited number of discrete values to decrease model size and increase inference speed. The DIFF Transformer reduces outlier activations, which pose a challenge for efficient compression. At extreme quantization to 4 bits, the DIFF Transformer achieved about 25 percentage points higher accuracy than a standard transformer.
Despite these advantages, the throughput of the DIFF Transformer is only about 5 to 12 percent lower than that of a comparable conventional transformer, according to the study. The researchers therefore see the new architecture as a promising foundation for future large language models.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.