Large AI models could soon become even larger much faster

Google demonstrates a new method that improves Mixture-of-Experts models and cuts their training convergence time in half.
Scaling model size, training data, and other factors have led to major advances in AI research, such as in natural language processing or image analysis and generation. Researchers have repeatedly demonstrated a direct relationship between scale and model quality.
Therefore, ever larger models with hundreds of billions or even trillions of parameters are being developed. To increase the training efficiency of such gigantic networks, some AI companies use so-called sparse models.
These models use only parts of their network, e.g., to process a token. Densely trained models like GPT-3 activate the whole network for each processing step.
With its Pathways project, Google is pursuing the future of artificial intelligence, which should be able to learn new tasks live and process numerous modalities. A central element of Pathways is scaling - and thus sparse modeling. In a new paper, Google demonstrates an advance that significantly improves the training of the mixture-of-experts architecture often used in sparse models.
Google has been researching MoE architectures for more than two years
In August 2020, Google introduced GShard, a method for parallelizing AI computations. The method enabled for the first time the realization of a sparsely trained Mixture-of-Experts model with 600 billion parameters (MoE-Transformer).
Within a Transformer module, there is typically a single Feed Forward Network that forwards information such as tokens. In an MoE-Transformer network, there are multiple such networks - the eponymous experts. Instead of passing all tokens through a single network, an expert processes only certain tokens.
In the GShard-trained MoE-Transformer, two experts usually process each token. The intuition behind this is that artificial intelligence cannot learn successfully if it cannot compare one expert with at least one other expert.
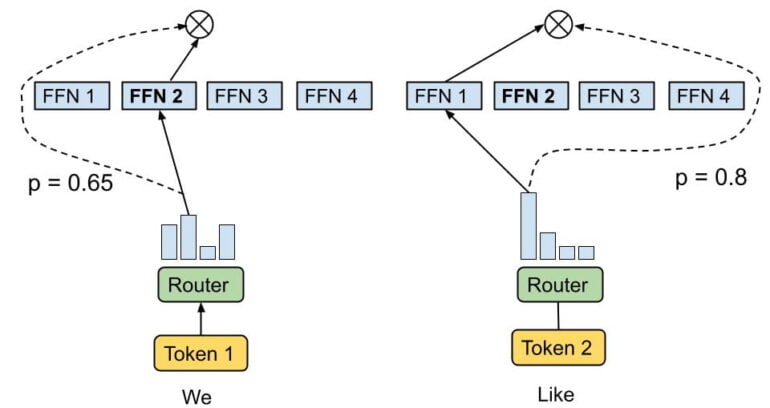
In January 2021, Google researchers presented the 1.6 trillion parameter Switch Transformer model, also a sparsely trained MoE-Transformer. It has one crucial difference: Instead of two or more expert networks per token, a router forwards information to only one network at a time. Google compares this process to a switch. Hence, the name of the AI model.
In the work, Google showed that the Switch Transformer can be trained faster and achieves better results than previous approaches.
Conventional MoE architectures tend to be imbalanced
Now Google has published a new paper that further refines the MoE system. Existing variants like Switch Transformer have some drawbacks, according to the authors. For example, certain expert networks can be trained with the most tokens during training, so not all experts are sufficiently utilized.
This leads to a load imbalance in which overused expert networks do not process tokens to avoid running out of memory. In practice, this leads to worse results.
In addition, the latency of the entire system is determined by the most heavily loaded expert. So in the case of a load imbalance, some advantages of parallelization are also lost.
It would also be useful for an MoE model to flexibly allocate its computational resources depending on the complexity of the input. So far, each token has always been assigned the same number of experts - two in the case of GShard and one in the case of Switch Transformer.
Google demonstrates Mixture-of-Experts with Expert Choice Routing
Google identifies the chosen routing strategy as the cause of these disadvantages. Conventional MoE models use token-choice routing, which independently selects a certain number of experts for each token.
In its new work, Google proposes an expert for the experts: In the so-called expert choice routing, the router selects a certain number of tokens for each expert network. This allows the routing to be more flexible, depending on the complexity of the available tokens.
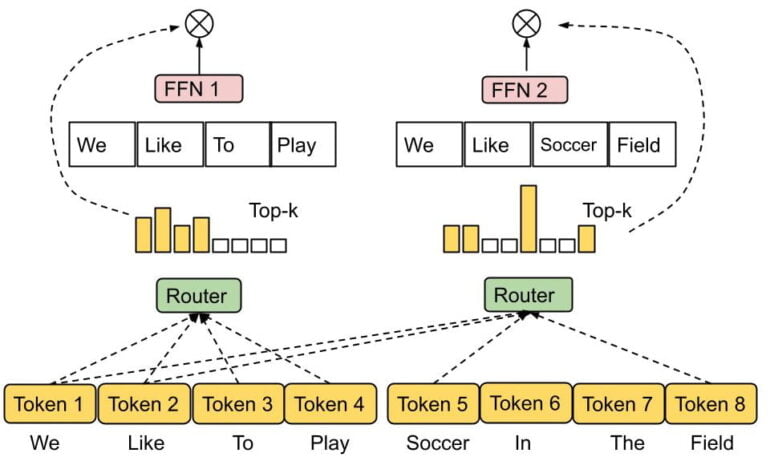
According to Google, the expert choice routing method achieves perfect load balancing despite its simplicity. It also enables a more flexible allocation of model compute, since the tokens can be received by a variable number of experts.
In a comparison with Switch Transformer and GShard, Google shows that the new method improves training convergence time by more than two times. With the same computational effort, it also achieves better results in fine-tuning eleven selected tasks in the GLUE and SuperGLUE benchmarks. For a smaller activation cost, the method also outperforms the densely trained T5 model in seven of the eleven tasks.
The team also shows that expert choice routing assigns a large proportion of tokens to one or two experts, 23 percent to three or four, and only about 3 percent to four or more experts. According to the researchers, this confirms the hypothesis that expert choice routing learns to assign a variable number of experts to tokens.
Our approach for expert choice routing enables heterogeneous MoE with straightforward algorithmic innovations. We hope that this may lead to more advances in this space at both the application and system levels.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.