Meta's new Apollo models aim to crack the video understanding problem
Meta and Stanford researchers have developed Apollo, a new family of AI models that tackles one of AI's persistent challenges: getting machines to truly understand videos.
While AI has made huge strides in processing images and text, getting machines to truly understand videos remains a major challenge. Videos contain complex, dynamic information that's harder for AI to process, requiring more computing power and raising questions about the best way to design these systems.
A joint team from Meta GenAI and Stanford University conducted extensive research to answer these fundamental design questions. Their systematic approach revealed insights about how to build more effective video understanding systems.
Small-scale insights apply to larger models
The team discovered something that could transform how AI video models are developed: improvements that work in small models reliably scale up to larger ones. This means researchers can test new approaches quickly using smaller, less expensive models before implementing them in larger systems.
When it comes to processing videos, the researchers found that keeping a constant sampling rate of frames per second produces the best results. Their optimal architecture uses two distinct components working together: one processes individual video frames, while the other tracks how objects and scenes change over time.
Adding time stamps between processed video segments proved crucial for helping the model understand how visual information relates to text descriptions. This simple but effective approach helps the system maintain temporal awareness throughout the processing pipeline.
Smart training beats bigger models
The research reveals that how you train an AI model matters more than its size. The team found that a carefully staged training approach, where different parts of the model are activated in sequence, produces significantly better results than training everything at once.
When training the visual components, focusing exclusively on video data helped the model develop stronger specialized capabilities. This targeted approach proved especially effective for tasks requiring detailed video understanding.
Getting the right mix of training data turned out to be crucial. The optimal balance includes 10-14% text data, with the remaining portion weighted slightly toward video content. This careful data composition helps the model develop both strong language understanding and video processing abilities.
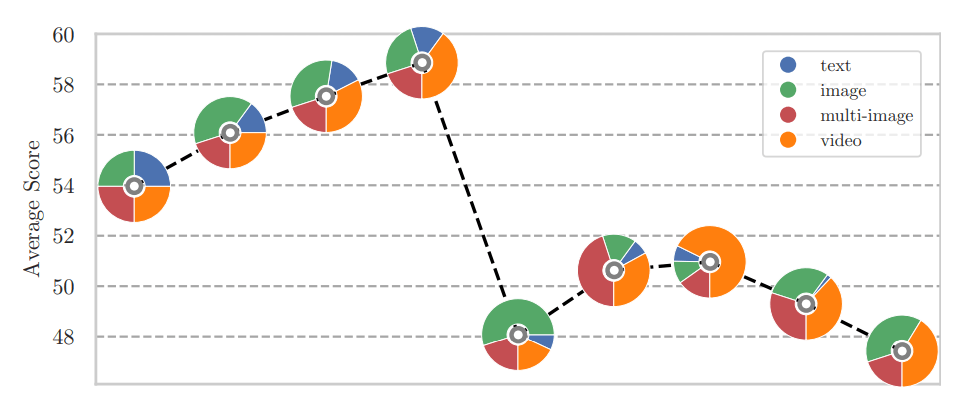
The resulting Apollo models show impressive performance across different sizes. The smaller Apollo-3B outperforms similar-sized models like Qwen2-VL, while Apollo-7B competes with much larger systems. Meta has released both the code and model weights as open source, with a public demo available on Hugging Face.
Better benchmarks for video AI
The research team also tackled another industry challenge: how to test video AI models properly. They discovered that many reported improvements actually came from better language processing rather than enhanced video understanding.
To address this, they created ApolloBench, a streamlined set of testing tasks that cuts down evaluation time while better assessing how well models understand temporal relationships in videos.
Meta's findings align with a growing industry trend: thoughtful design and training strategies often matter more than raw model size. This mirrors recent developments like Microsoft's Phi-4 language model and Google's Gemini 2.0 Flash, which achieve strong results despite their relatively compact size.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.