Deepseek-V3 emerges as China's most powerful open-source language model to date
Chinese AI company Deepseek just released its most powerful language model yet. Early tests show that the new V3 model can go toe-to-toe with some of the industry's leading proprietary models, and shows particular improvement in logical reasoning tasks.
The model, now available on Github, uses a Mixture-of-Experts (MoE) architecture with 671 billion total parameters, of which 37 billion activate for each token. That's a significant increase from V2, which has 236 billion total parameters, with 21 billion active during inference.
The training was also more extensive, processing 14.8 trillion tokens - almost double V2's training data. According to Deepseek, the full training took 2.788 million H800 GPU hours and cost approximately $5.576 million.

What's particularly impressive is that they achieved this using a cluster of just 2,000 GPUs - a fraction of the 100,000 graphics cards that companies like Meta, xAI, and OpenAI typically use for AI training. Deepseek credits this efficiency to their optimized co-design of algorithms, frameworks, and hardware.
Deepseek v3 is faster and smarter
One of V3's biggest improvements is its speed - it can process 60 tokens per second, making it three times faster than its predecessor. The team focused heavily on improving reasoning, using a special post-training process that used data from their "Deepseek-R1" model, which is specifically designed for complex reasoning tasks.
When benchmarked against both open-source and proprietary models, it achieved the highest score in three of the six major LLM benchmarks, with particularly strong performance on the MATH 500 benchmark (90.2%) and programming tests such as Codeforces and SWE.
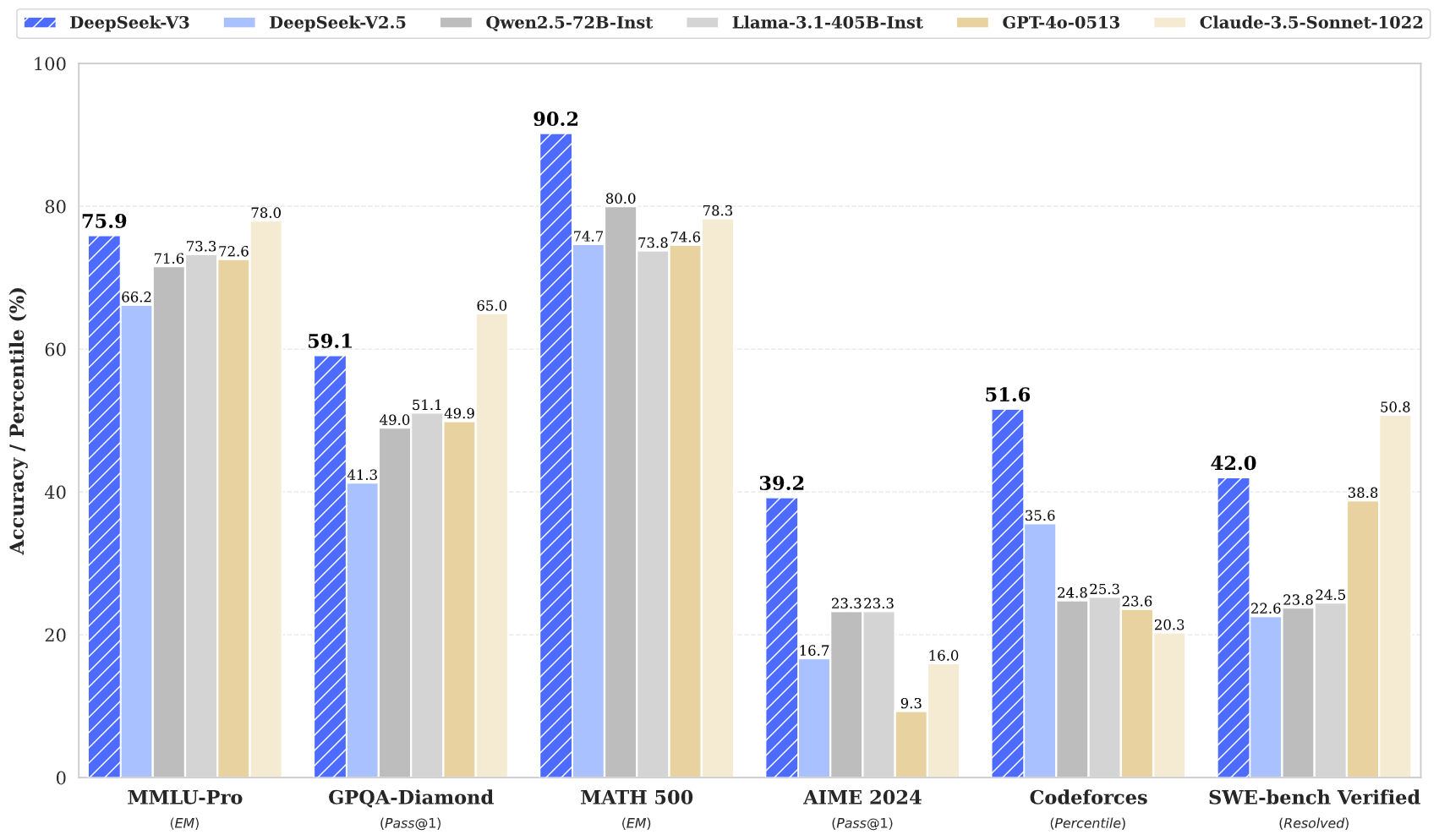
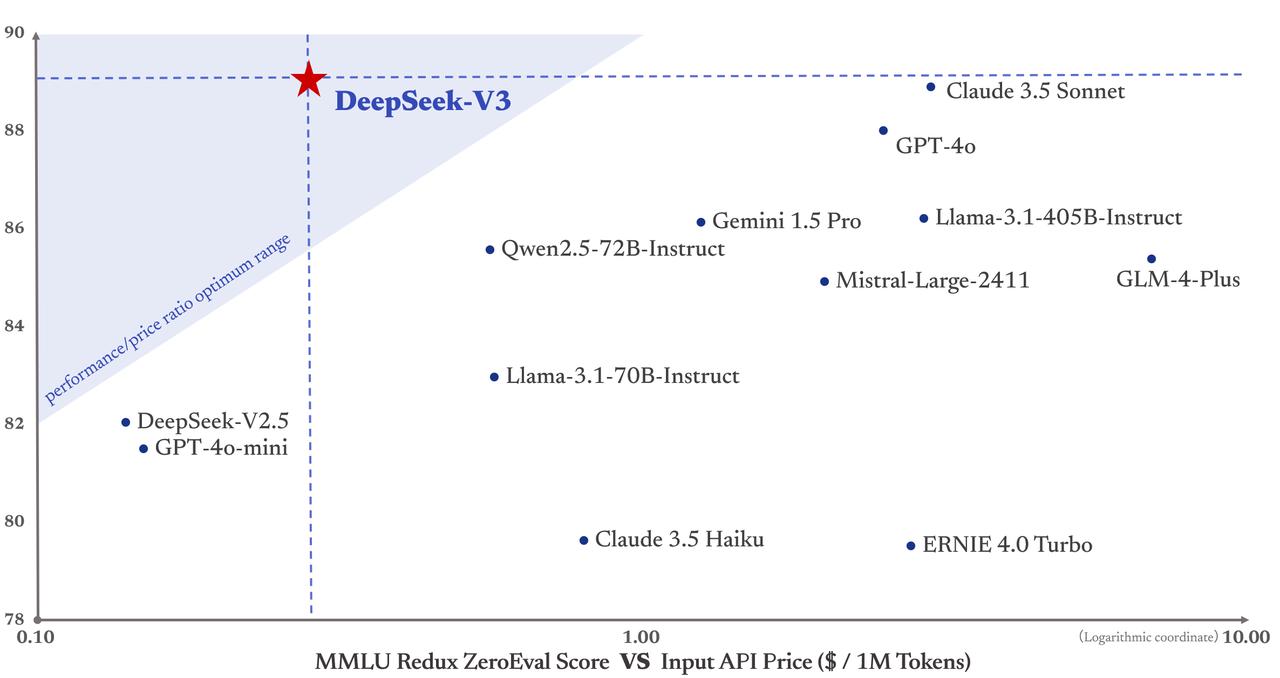
According to Deepseek, V3 achieves performance comparable to leading proprietary models like GPT-4o and Claude-3.5-Sonnet in many benchmarks, while offering the best price-performance ratio in the market. The API pricing will hold steady at V2 rates until February 8th. After that, users will pay $0.27 per million tokens for inputs ($0.07 for cache hits) and $1.10 per million tokens for outputs.
The model is released under the Deepseek License Agreement (Version 1.0), which grants users a free, worldwide, non-exclusive and irrevocable copyright and patent license. Users can reproduce, modify, and distribute the model, including for commercial purposes, though military applications and fully automated legal services are prohibited.
Founded just last year, Deepseek plans to improve its model architecture. The company wants to "break through the architectural limitations of Transformer, thereby pushing the boundaries of its modeling capabilities," and support unlimited context lengths. Like OpenAI, it says it is taking an incremental approach to artificial general intelligence (AGI). Its current lineup includes specialized models for math and coding, available both through an API and for free local use.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.