MiniMax introduces AI models with record context length for agents with 'long term memory'

MiniMax, a Chinese AI startup, has released its MiniMax-01 family of open-source models. The company says its MiniMax-Text-01 can handle contexts up to 4 million tokens - double the capacity of its closest competitor.
The new lineup includes two models: MiniMax-Text-01 for text processing and MiniMax-VL-01 for handling both text and visual data. This expanded context window could give AI agents a form of "long-term memory," allowing them to collect, connect, and store information from multiple sources for later use.
"Lightning Attention" increases efficiency
To process such lengthy contexts efficiently, MiniMax uses a hybrid approach. The system combines the "Lightning Attention" mechanism (introduced in 2023 and updated in 2024) with traditional Transformer blocks in a 7:1 ratio. The team says this setup significantly cuts down processing demands for long inputs while keeping the benefits of Transformer architecture.
The model also uses a "Mixture of Experts" (MoE) structure - essentially a layer of specialized sub-models optimized for different tasks. The system picks and combines the most suitable experts based on what it's working with. MiniMax-Text-01 has 32 of these experts, each with 45.9 billion parameters, bringing the total to about 456 billion parameters.
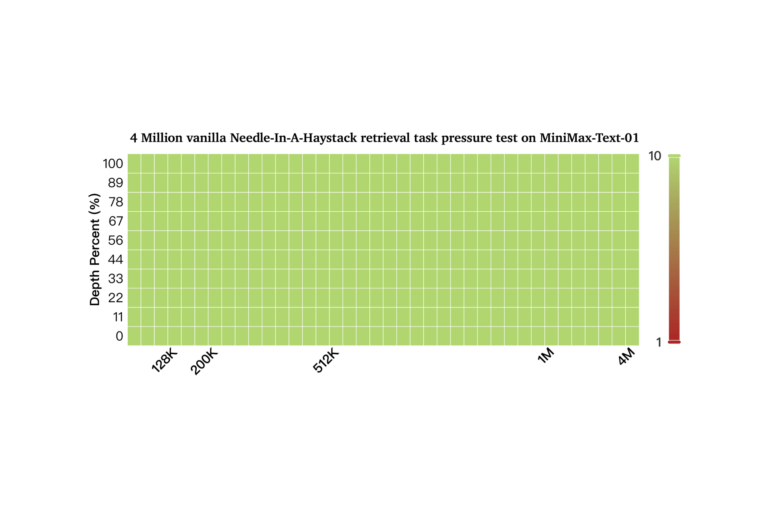
A needle found in the 4 million token haystack
MiniMax has released benchmark tests showing their model performs similarly to top commercial options like GPT-4 and Claude 3.5 Sonnet in standard evaluations.
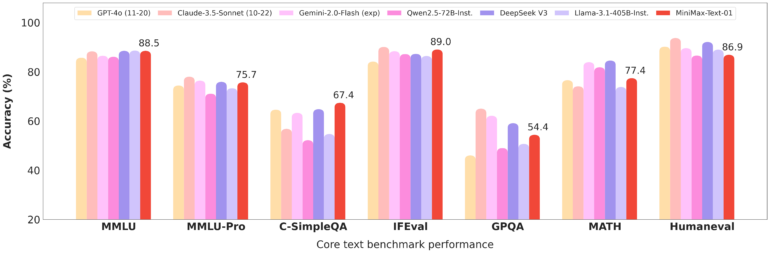
The company says MiniMax-Text-01 particularly shines with long contexts - claiming 100% accuracy in the "Needle-In-A-Haystack" test with 4 million tokens.
However, it's worth noting that Google's year-old Gemini 1.5 Pro, with its 2-million token window, achieved the same perfect score. Researchers have found this benchmark isn't particularly meaningful, and studies suggest that extremely large context windows might not offer real advantages over smaller ones when used with RAG systems.
Models available as open source
Anyone can download the MiniMax-01 models from GitHub and Hugging Face. Users can test them through MiniMax's Hailuo AI chatbot or integrate them via a relatively affordable API.
The company, backed by Alibaba and founded in late 2021, previously made headlines with its Video-01 generator last fall. While MiniMax sees DeepSeek (which recently released its own open-source language model) as a competitor, both companies' models will likely face restrictions from Chinese government censorship.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.