Alibaba's Qwen2.5-VL-32B matches larger models with just 32B parameters

Update March 26, 2025:
Alibaba has unveiled its latest multimodal AI model, Qwen2.5-VL-32B, released under the Apache 2.0 license. Early benchmarks show the model outperforming larger competitors like Gemma 3-27B and Mistral Small 3.1 24B. In some tests, it even surpasses Alibaba's own Qwen2-VL-72B and older versions of OpenAI's GPT-4o, though not the current release.
The model achieves top scores in MMMU (Multimodal Machine Understanding), which tests how well AI systems understand different types of media, and MathVista, which evaluates mathematical reasoning using images. The MM-MT-Bench, which measures interaction quality, shows significant improvements over its predecessor. These gains extend to pure text tasks as well.
Developer Simon Willison tested Qwen2.5-VL-32B on a Mac with 64GB RAM. His tests showed the model could provide detailed, well-structured descriptions of complex coastal maps, accurately interpreting depth lines and geographical features.
Apple Silicon users can choose from several optimized versions of the model, including 4-bit, 6-bit, 8-bit, and bf16 variants, making it accessible on different hardware configurations.
The Qwen team plans to focus on developing longer and more effective reasoning processes for handling complex visual tasks. This continues the work they started with QVQ, their first multimodal model with reasoning capabilities released in late 2024.
Original Article January 29, 2025:
Alibaba says its new Qwen2.5-VL model is a useful "visual agent"
Alibaba has added a multimodal visual language model to its Qwen2.5 series, marking another step in the Chinese tech company's effort to compete in the commercial AI space.
Building on the open source Qwen2-VL model from fall 2024, the new version promises better handling of various data types including text, images and hour-long videos. The team says they've made particular progress with diagrams, icons, graphics and layouts. The model comes in three sizes: 3, 7 and 72 billion parameters.
These improvements also make the model useful as a visual assistant, according to the company. In several demos, Alibaba shows Qwen2.5 analyzing screen content and providing instructions for tasks like booking flights, checking weather forecasts, and navigating complex interfaces like Gimp.
In this demo, Qwen2.5-VL helps to book a flight ticket based on the starting point and destination. | Video: Qwen
Here Qwen2.5-VL helps to get the weather forecast for Manchester, UK. | Video: Qwen
Qwen2.5-VL can also understand more complex user interfaces, such as those of Gimp. | Video: Qwen
While Qwen2.5 isn't a specialized agent model like OpenAI's recently introduced CUA, it excels at analyzing interfaces, identifying relevant buttons and planning workflows. This capability could make it valuable as the foundation for an open operator-like system.
Qwen2.5 beats GPT-4o and Claude 3.5 Sonnet in benchmarks
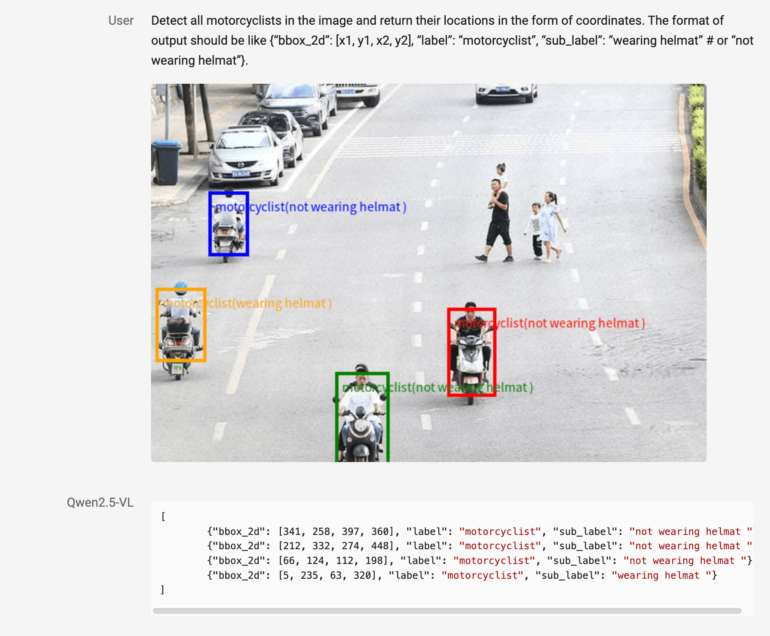
The model can identify specific objects and their components - for instance, determining whether a motorcyclist is wearing a helmet. When processing documents like invoices and forms, it can output the information in structured formats like JSON for easy reuse.
According to Alibaba, the largest version, Qwen2.5-VL-72B, performs on par with OpenAI's GPT-4o, Claude 3.5 Sonnet and Gemini 2.0 Flash across various benchmarks, sometimes outperforming them in areas like document comprehension and visual assistance without special training.
The smaller versions, Qwen2.5-VL-7B-Instruct and Qwen2.5-VL-3B, also show improvements over GPT-4o-Mini and the previous Qwen2-VL in many tasks.
Qwen plans omnimodal model like GPT-4o
Looking ahead, the Qwen team plans to enhance the models' problem-solving and reasoning capabilities while adding support for more input types. Their ultimate goal is to create an AI model that can handle any kind of input or task, including audio. A detailed paper on the model's architecture and training process is in development.
The Qwen2.5 VL models are available open source through GitHub, Hugging Face and ModelScope, as well as through Qwen Chat, though some commercial use restrictions apply. Due to Chinese regulations, these models, like those from Deepseek, avoid discussing certain topics deemed sensitive by authorities.
The company recently expanded the Qwen2.5 series to include a model supporting context windows of up to one million tokens.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.