AI language models struggle to connect the dots in long texts, study finds

The latest generation of AI language models hits its limits when connecting information across long texts and drawing conclusions, according to new research from LMU Munich, the Munich Center for Machine Learning, and Adobe Research.
The team tested 12 leading models, including GPT-4o, Gemini 1.5 Pro, and Llama-3.3-70B, all capable of handling at least 128,000 tokens.
Models fail when word-matching isn't an option
The NOLIMA (No Literal Matching) benchmark tests how well AI models can link information and draw conclusions without relying on matching words. The test uses questions and text passages crafted to avoid shared vocabulary, forcing models to understand concepts and make connections.
Here's how it works: A text might include "Yuki actually lives next to the Semperoper." The related question would be: "Which character has already been to Dresden?" To answer correctly, the model needs to understand that the Semperoper is in Dresden, identifying Yuki as the answer.
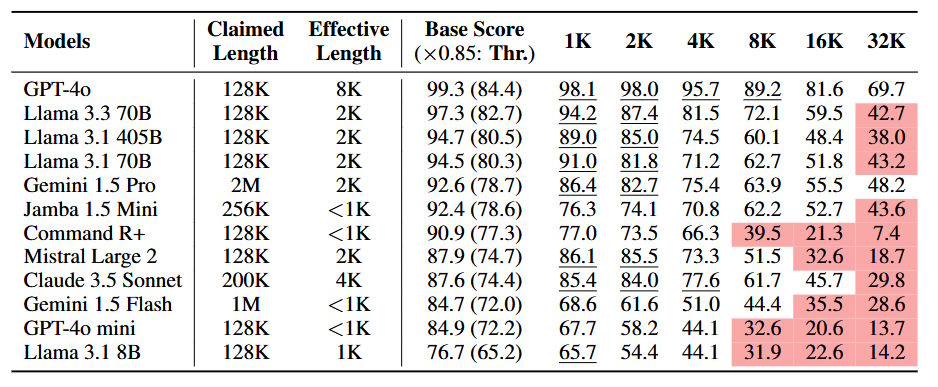
The results show models struggling as text length increases. Performance drops significantly between 2,000 and 8,000 tokens. At 32,000 tokens, 10 out of 12 models perform at half their usual capability compared to shorter texts.
Even specialized reasoning models fall short
The researchers point to limitations in the models' basic attention mechanism, which gets overwhelmed by longer contexts. Without word-matching clues, models struggle to find and connect relevant information.
Performance drops further when more thinking steps (latent hops) are needed. The order of information matters too - models perform worse when the answer comes after the key information.
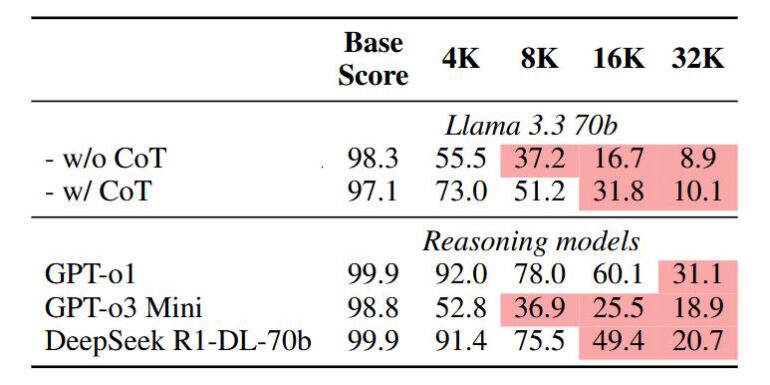
The team also created NOLIMA-Hard, featuring the ten toughest question-answer pairs, to test specialized reasoning models. Even purpose-built systems like o1, o3-mini, and DeepSeek-R1 score below 50 percent with 32,000-token contexts, despite near-perfect performance on shorter texts.
Chain-of-Thought-Prompting (CoT) helps Llama-3.3-70B handle longer contexts better, but doesn't solve the core problem. While word matches make the task easier, they can actually hurt performance if they appear as distractions in irrelevant contexts.
This weakness could affect real-world applications, for example search engines using RAG architecture. Even when a document contains the right answer, the model might miss it if the wording doesn't exactly match the query, getting distracted by surface-level matches in less relevant texts.
NOLIMA as the new context window metric?
While recent months haven't seen major breakthroughs in foundation models, companies have focused on improving reasoning capabilities and expanding context windows. Gemini 1.5 Pro currently leads with a two-million token capacity.
As context windows grew - from GPT-3.5's 4,096 tokens to GPT-4's 8,000 - models initially struggled with basic word sequence extraction. They later showed improvement in manufacturer-published NIAH benchmark results.
NOLIMA could become a new standard for measuring how effectively models handle large context windows, potentially guiding future LLM development. Previous research suggests there's still significant room for improvement in this area.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.